前回の記事では、Excelでデータを結合をする際のベストプラクティスを紹介しました。今回は結合したクエリに「分類」をマージして、異なるデータ粒度でクエリをワークシートに出力する方法を紹介します。マージとは、Power Query版VLOOKUPであり、例えばマッピングテーブル(商品マスタ等)から該当する分類をVLOOKUPで抽出してくることに該当します。
今回は以下のようなデータセットを使用します。Excel内にてCategoryという「商品」及び「分類」が入っているテーブルを作成します。テーブルの作成及びクエリ化は以下の記事より。
マージの基本
「データ」 > 「データの取得」 > 「テーブルまたは範囲から」より、クエリとして取り込みます。
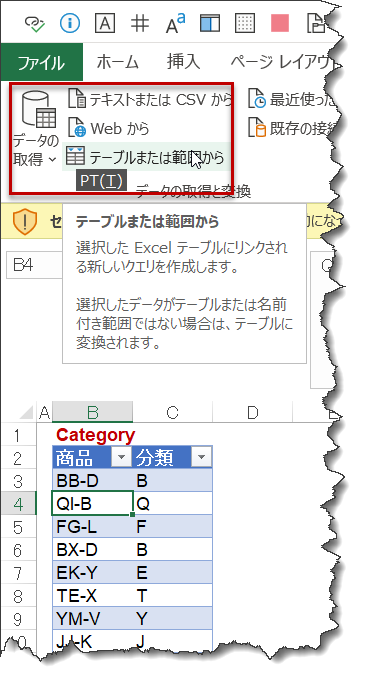
下記はCategoryを読み込んだクエリであり、このクエリにある[商品]をキーとして、Inventoryクエリ内に[分類]を抽出する作業を行います。
やり方は非常にシンプルで、以下の手順を行います。
- クエリInventoryをクリック
※Inventoryは前の記事「Power Queryの基礎 8_Excelの結合①」で紹介済 - 「ホーム」 > 「クエリのマージ」
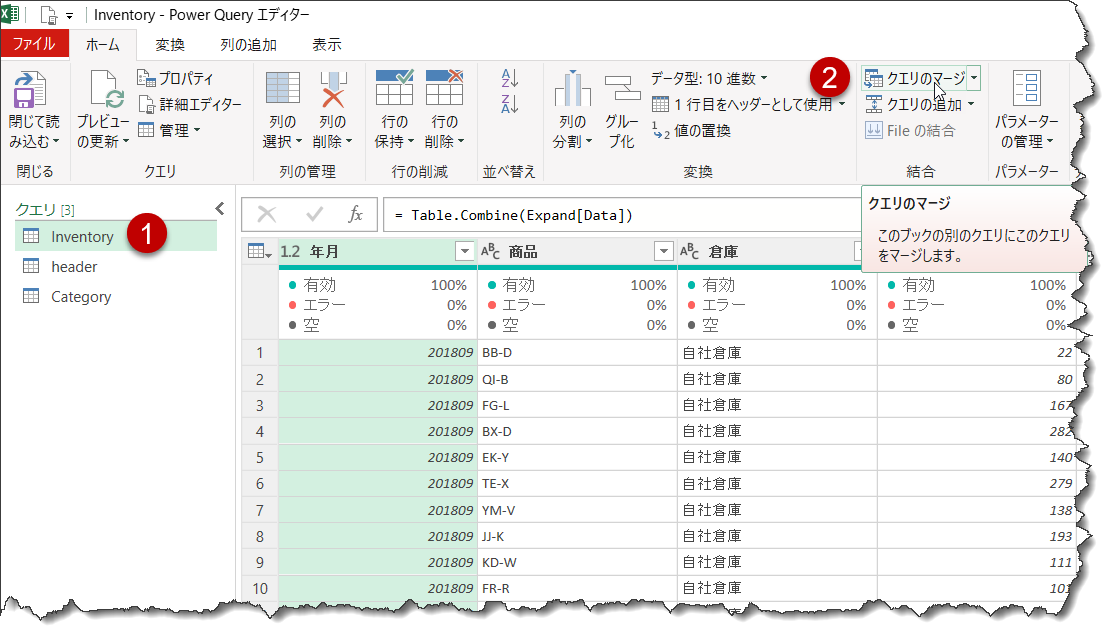
- マージしたいテーブルを選択
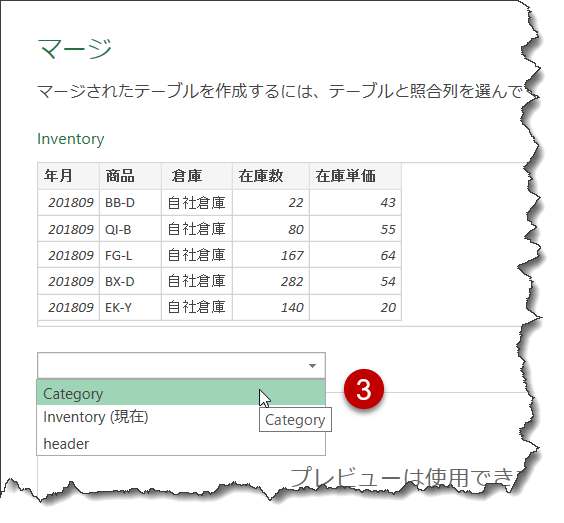
- Inventoryでのキー(紐づけ用)を選択
- マージ先のキーが入っている列を選択(名前はInventoryのキー列と異なってもOK)
- 結合の種類をそのまま(左外部)
- 一致している行数の確認し、OK
※ここが一致しない場合、左外部のマージをした場合、マージを展開した後の[分類]列にnullが出現する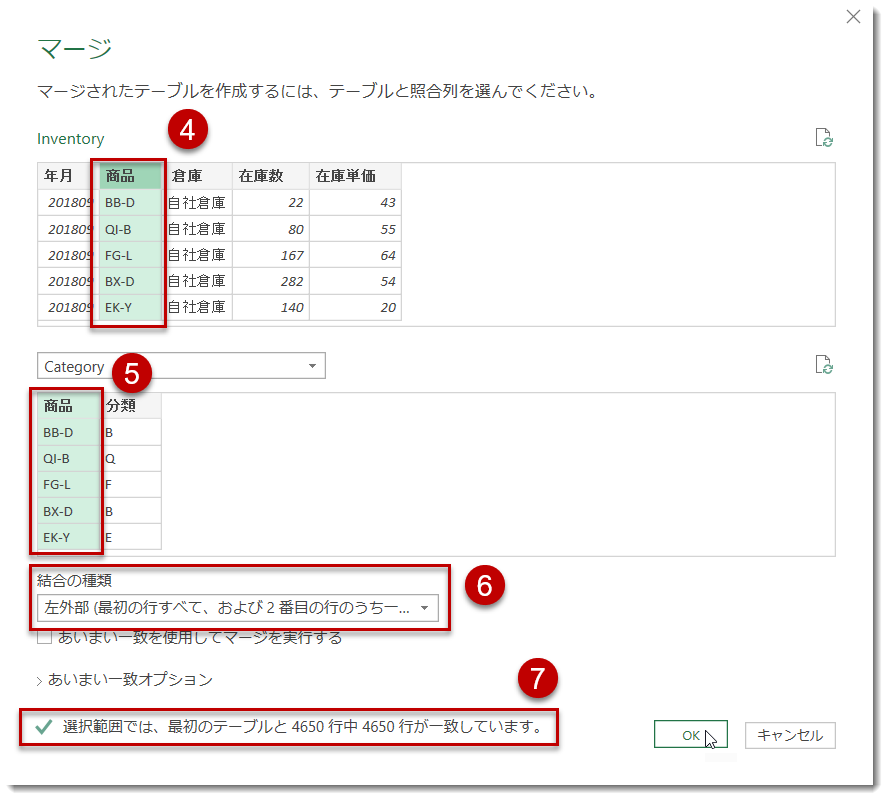
- 以下のように、Inventoryに新しい列が追加される
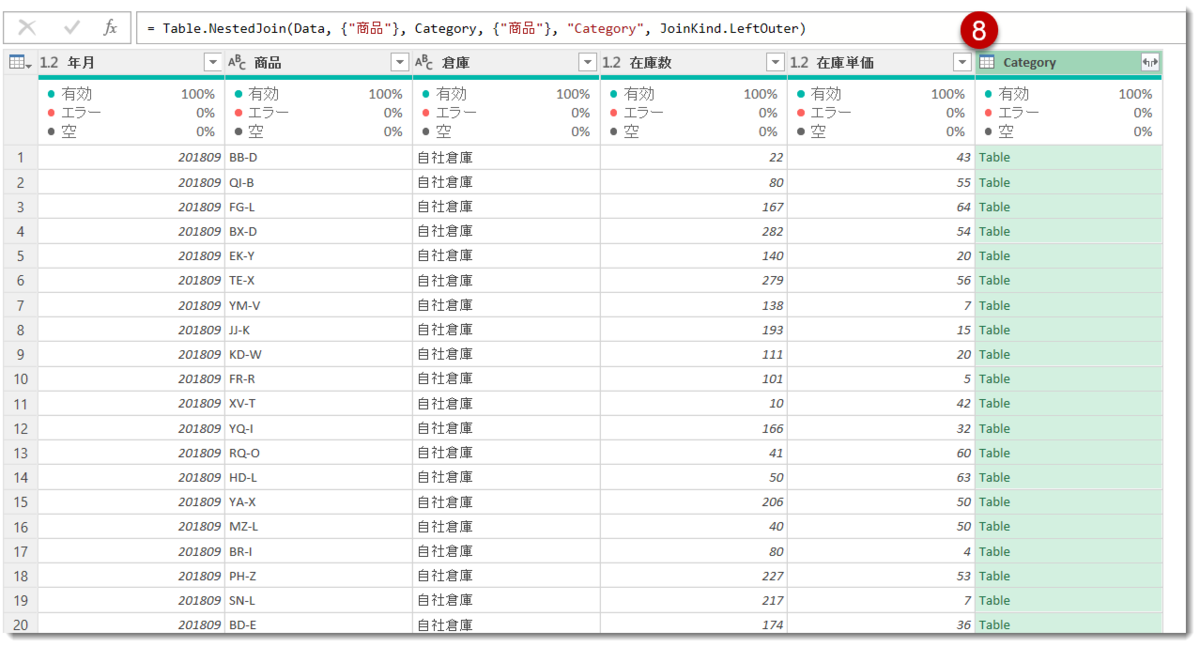
-
←→の部分をクリックし、下図のように選択

-
OKをクリックすると、下図のようにVLOOKUPで分類が抽出されたクエリに
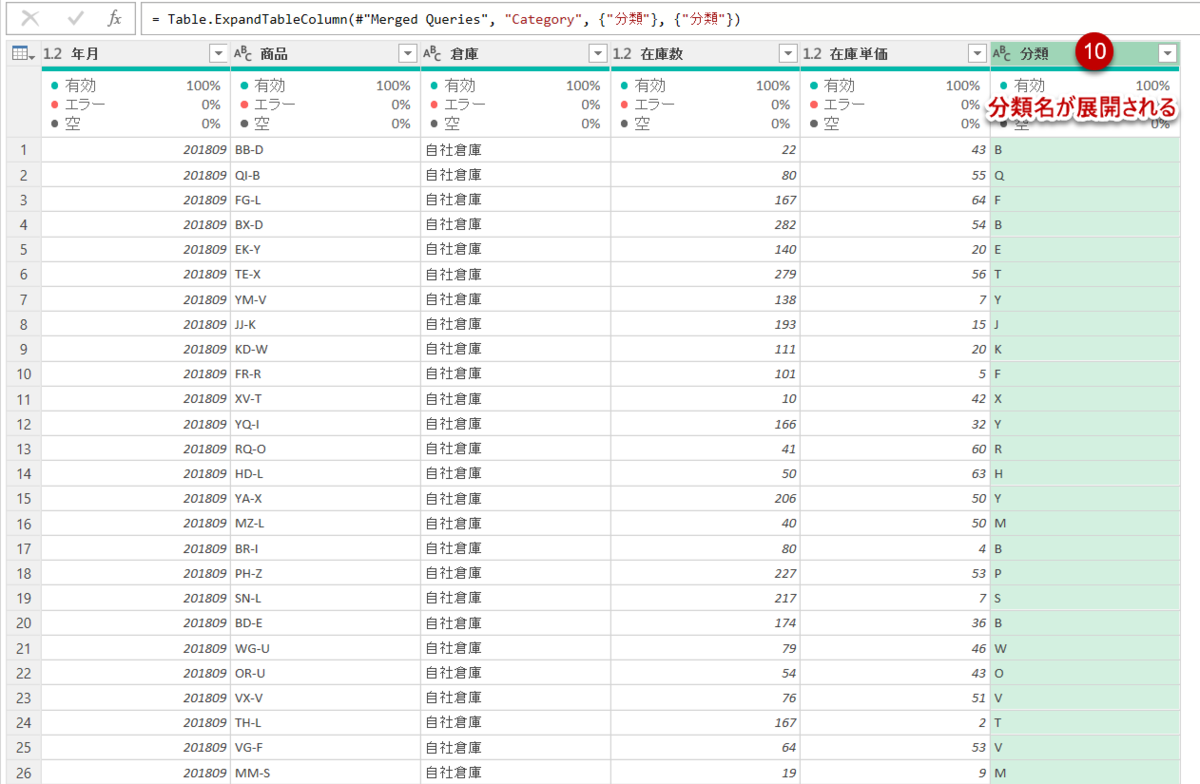
ここで分類のフィルターを開き、一番下の「さらに読み込む」をクリックし、null値がないことを確認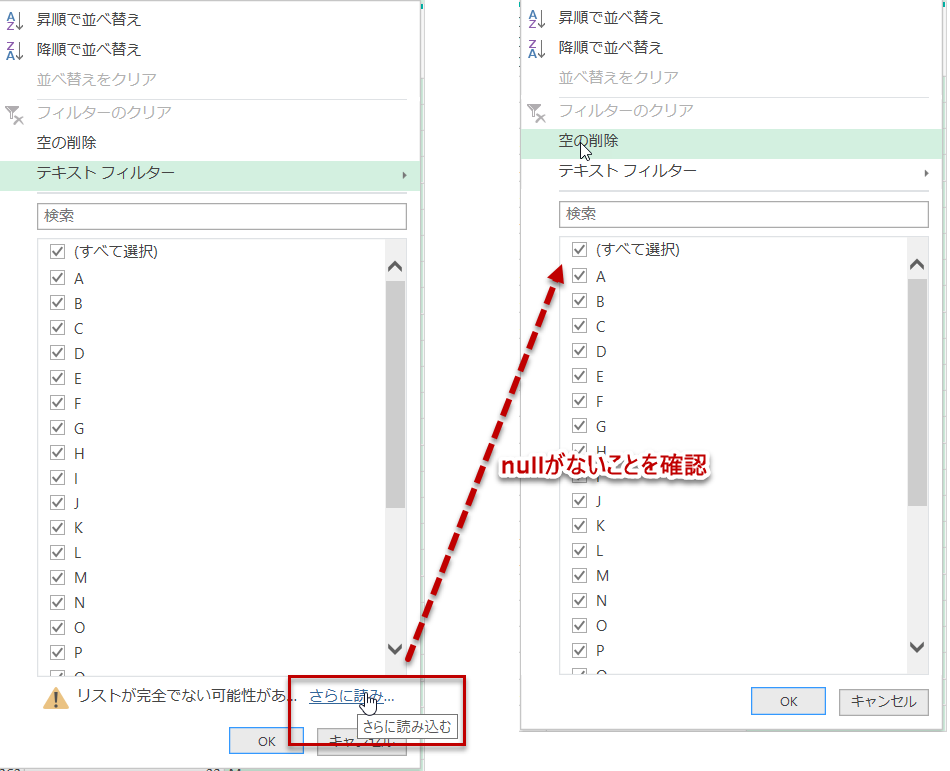
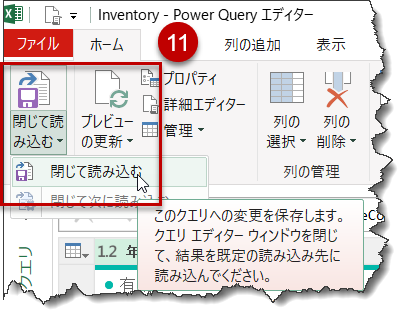
- この状態で一度出力を行う(「閉じて読み込む」をクリック)
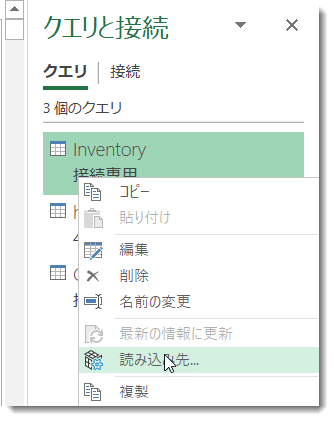
- 接続専用の状態でInventoryが作られていた場合、クエリを右クリックして、もう一度「読み込み先」を選択
-
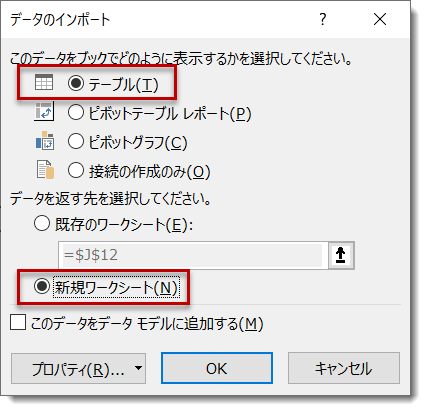
下図のように、新しいワークシートに出力する
- 無事クエリが読み込まれていれば、下図のようになる
ここから、以前の記事のように、出力されたデータセットを基にPivotテーブルを作り、Excel内で分析を行う。
マージの種類
上述したマージですが、合計で6つあります。今回の例では下図の一番左上の「左外部」を使っており、図が示す通り、元々あるデータセットのデータ量を増やすことなく、追加情報を取得(マージ)するものとなります。「左外部」が最もポピュラーなマージであるため、マージする場合は殆どのケースがこちらになります。
「右外部」は「左外部」の逆のパターンで、通常は最初に商品マスタ等のクエリ(今回の例でいえばCategory)を選び、2番目のクエリにInventoryを選んでマージを行います。
「完全外部」は両方の行全てに対して行うもので、行数が「左外部」の時よりも増えることになります。その他、「内部」は両方のクエリに存在するもの、「左反」はマージ先クエリに存在しない値を返すもの、「右反」は「左反」の逆バージョンになります。
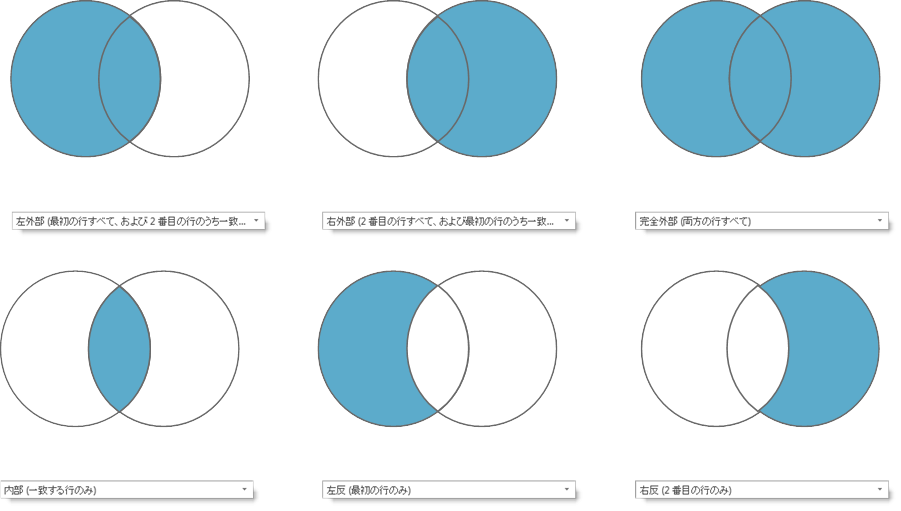
これらのマージ手法をうまく活用するためにはとにかく機能を確かめてみることが大事であり、実務ベースで試していくとその違い、使用場面が掴めてくると思います。Power Queryは執筆時点では残念ながら上図のように、ビジュアルでマージ後のイメージを提供してくれないですが、いずれ小さなアイコンとして導入されるのではと期待しています(一部、Power BIサービスの機能であるデータフローでアイコン表示となっていますが、本記事の対象外となりますので、別途機会があれば解説します)。
分類別クエリの作成(グループ化)
先ほど出力したクエリは基データの状態であり、データ粒度が最も細かくなっているものとなります。このデータ粒度であれば、Pivotテーブルにした後、好きなように分析を行うことができるのですが、そこまで細かい粒度ではなく、クエリとして例えば「年月+分類別」のデータだけを出力したい場合、以下のことを行うとできるようになります。
クエリエディタを開き、Inventoryクエリを右クリック > 参照
すると、下図のように、Inventoryを参照したInventory (2)というクエリが作成されるので、このクエリをクリックしてF2を押してクエリの中身をハイライトし、名称をInv_DateCategoryに変更します。
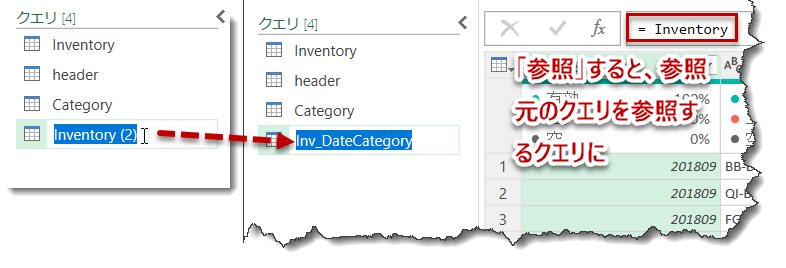
M言語の数式は
= Inventory
となり、Excelでいうセルを参照したような状態になりますが、Power Queryではクエリを参照することで、テーブルそのものを参照することができるようになります。「参照」の上に「複製」というものがありますが、違いは以下の通りです。
参照:文字通り、クエリを参照し、テーブルやスカラー値を参照
複製:上の例でいえば、Inventoryをもう一つ複製していることであり、M言語の数式はInventoryと同じものになります(下図)
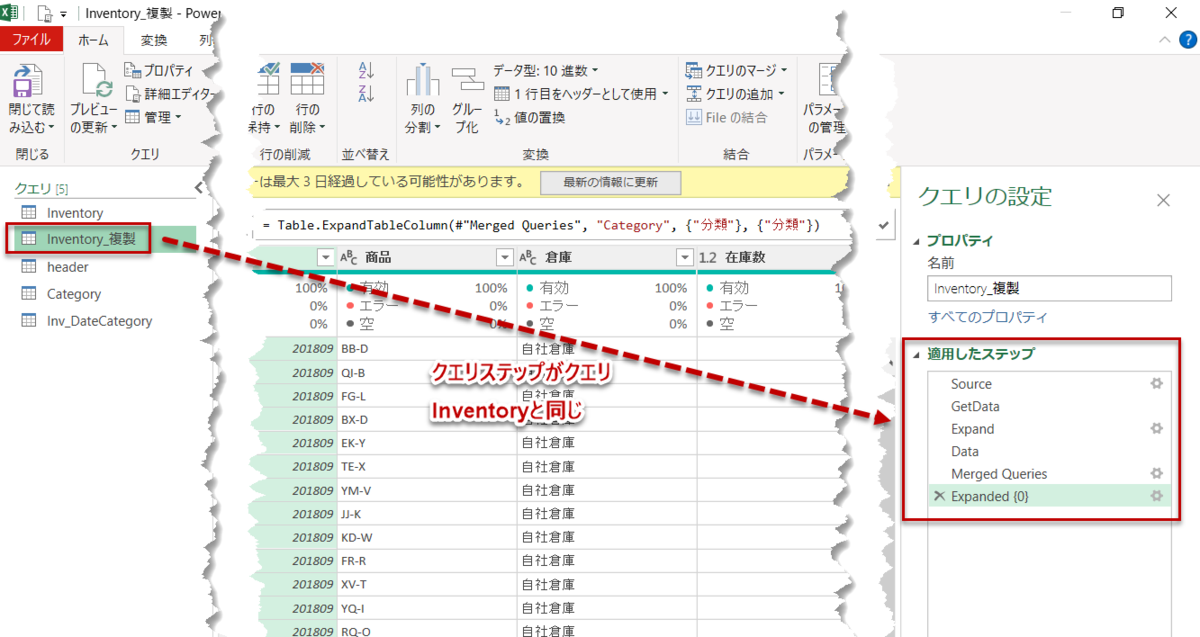
「参照」と「複製」の使い分けですが、前者はオリジナルデータを残したまま、データ粒度を変更したりして再利用したい場合、後者はマージ等を行う際に起こる循環参照を防ぐためと単純に覚えておくと良いでしょう。
Inv_DateCategoryのクエリをクリックし、グループ化を行います。やり方は2つあり、どちらでも良いですが、列数が少ない場合は
予めグループ化したい列を複数選択してグループ化
がシンプルで分かりやすいです。下図のように、Ctrl + クリックでグループしたい複数の列を選択し、右クリック > グループ化を選択。
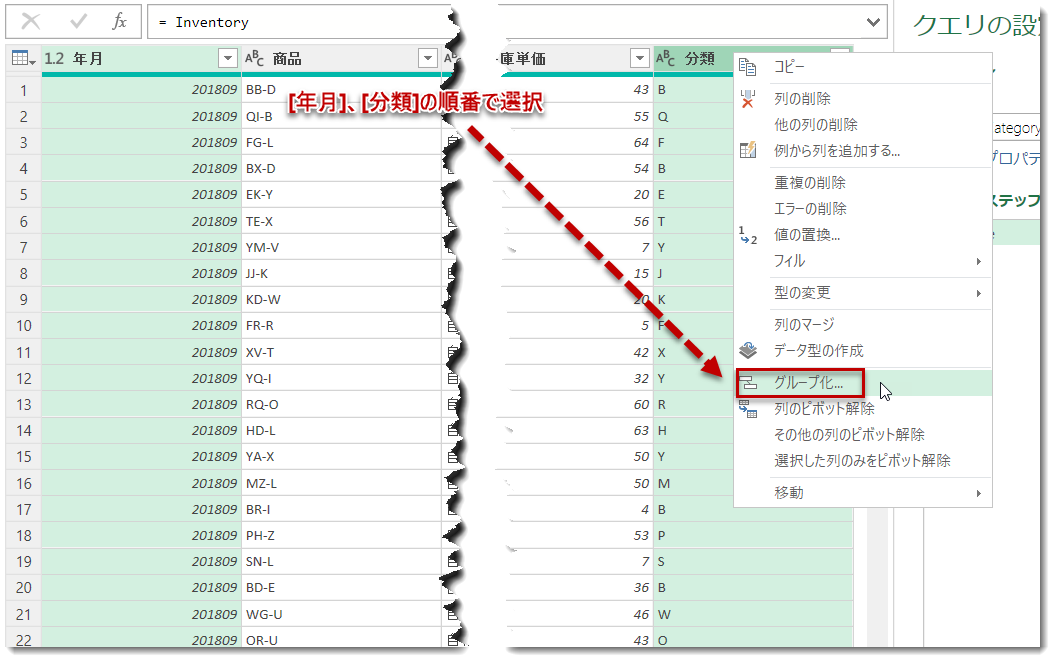
ここで留意しなければいけないのは、以下の2点。
- 選択した列の順番でグループ化した際のデータの階層が決まってしまう
- グループ化する場合、基本的には数値型の列以外の列で行う
1は[分類]、[年月]の順にクリックしてしまうと、出来上がりのクエリは順番が逆になってしまうこと、2については基本的に日付型・テキスト型の列をグループ化することがニーズとして高い、ことになります。
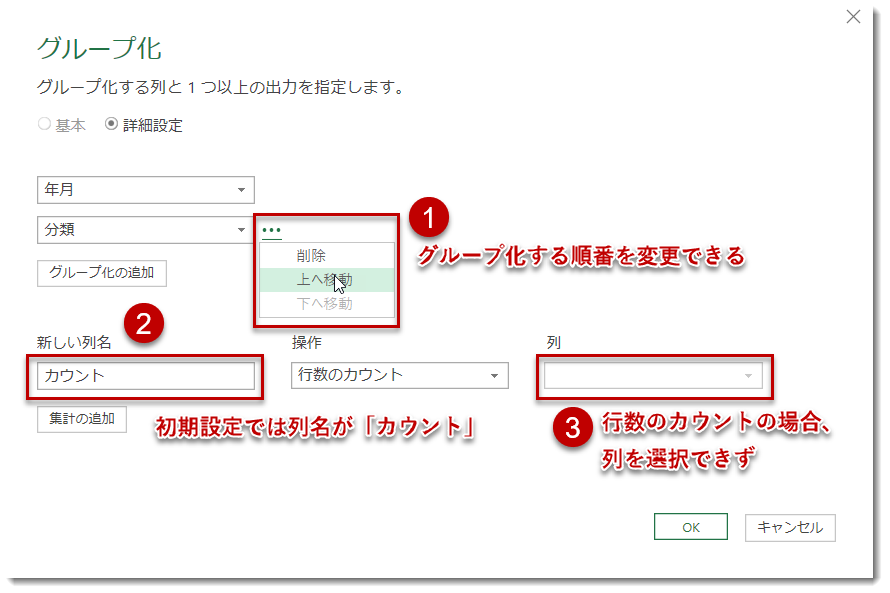
「グループ化」をクリックすると、上図の「グループ化」の設定ウィンドウに切り替わり、①ではグループ化の順番を変更できる一方で、②は①でグループ化した列に対して、何を算出したいかを設定するもの(数字列)となります。
初期設定では自動的に「カウント」が設定されており、このままOKを押すと、グループ化した階層でInv_DateCategoryの行数をカウントしてくれます。ここではもう一つの列(数値列)を追加して、以下のようにします。
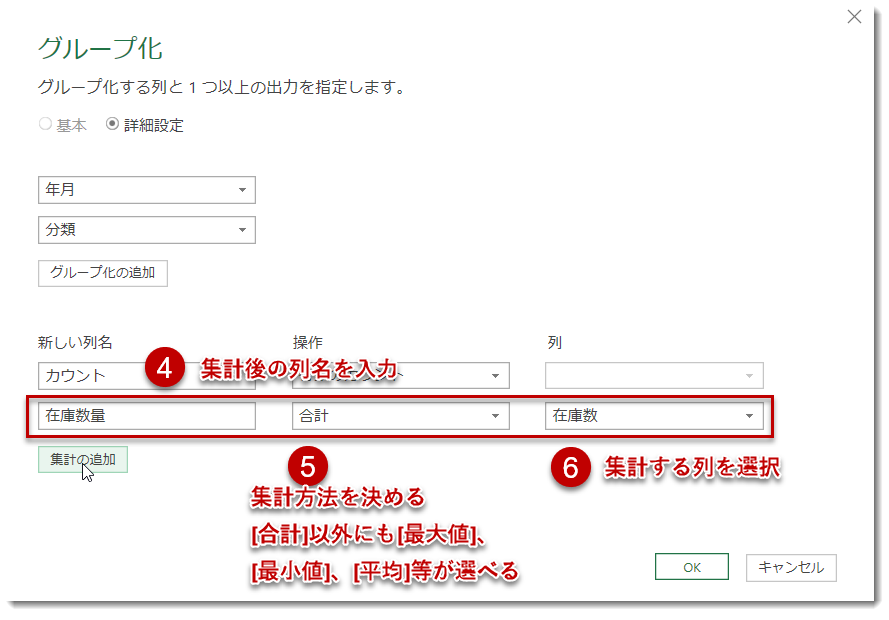
上図の通り、「集計の追加」で数値列をいくつでも追加することは可能であり、今回は在庫数量という列を追加してみます。なお、在庫金額を追加したい場合はグループ化する前にInventoryクエリにて在庫金額(在庫数量×在庫単価)を算出してあげる必要があり、これは在庫単価をグループ化してしまうと間違った結果になるためです。そのため、新しい列として追加される数値列は、
何でもグループ化できるものではない
ことを意識しておくことが重要です。グループ化が完了すると、以下のクエリが作成されます。
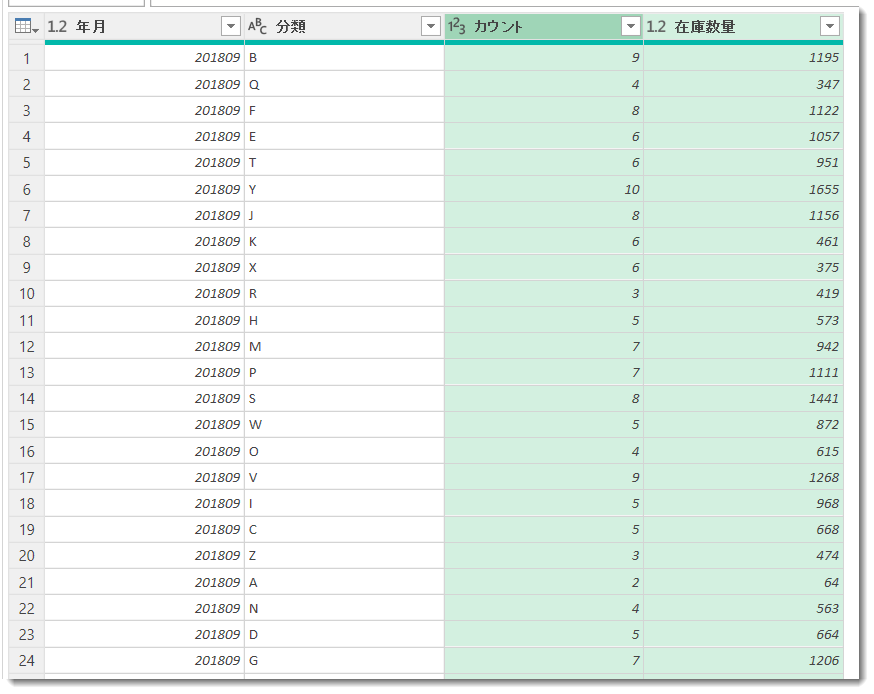
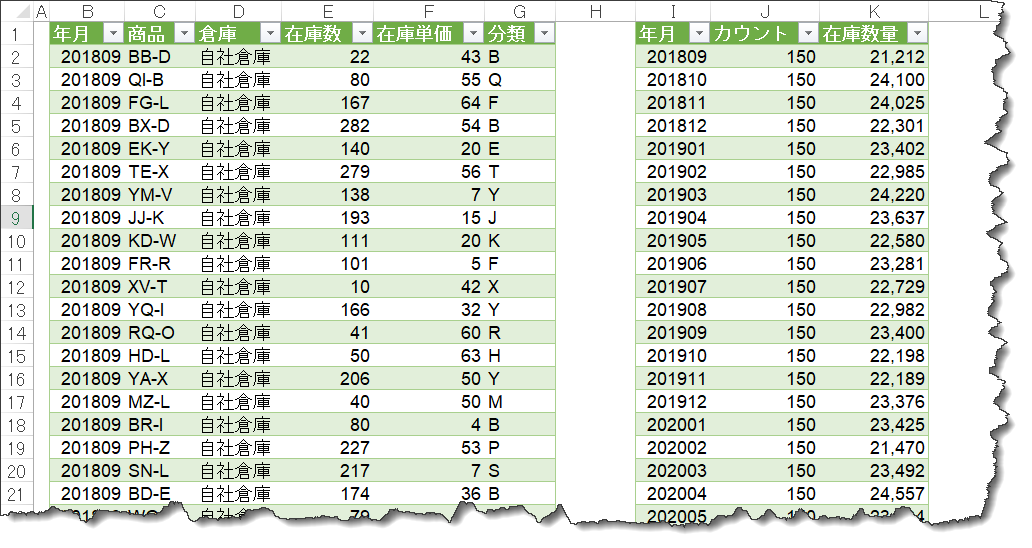
元々のクエリInventoryにあった[倉庫]や[商品]、[在庫単価]等の列が消え、指定した列だけが残った状態でグループ化された結果となっていることが分かります。なお、ここで最初の行について吟味しておくと以下の意味となります。
201809(2018年9月)時点で、分類Bには、9つの商品(カウント = 9)があり、この分類Bにおける在庫数量は1,195個であった
グループ化とは、Pivotテーブルのように、クエリ内で集計することを意味します。ここでグループ化されたクエリ(Inv_DateCategory)を出力してみます。
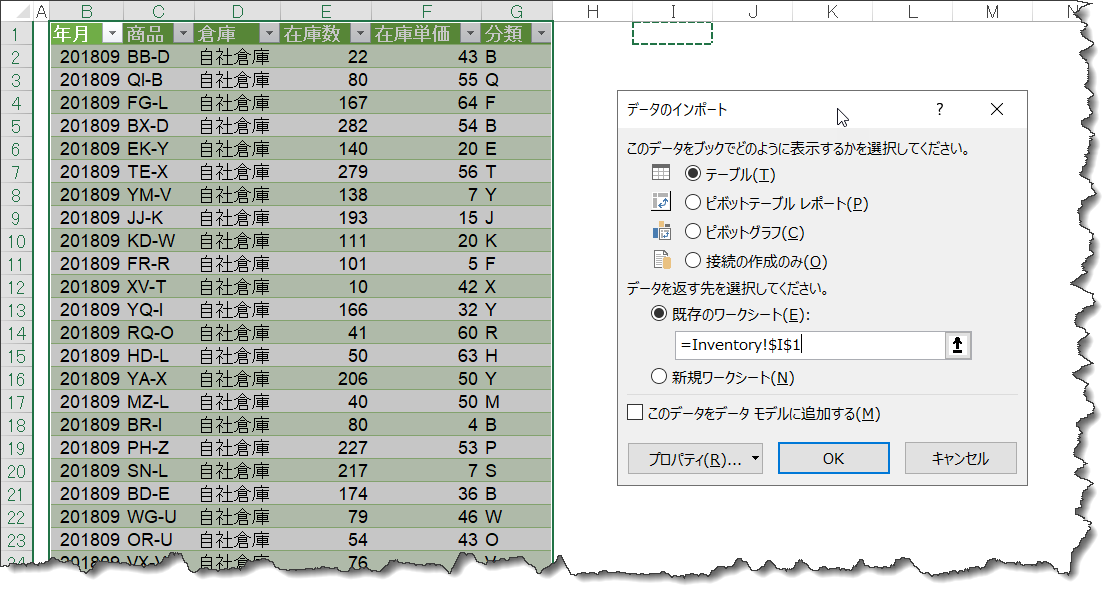
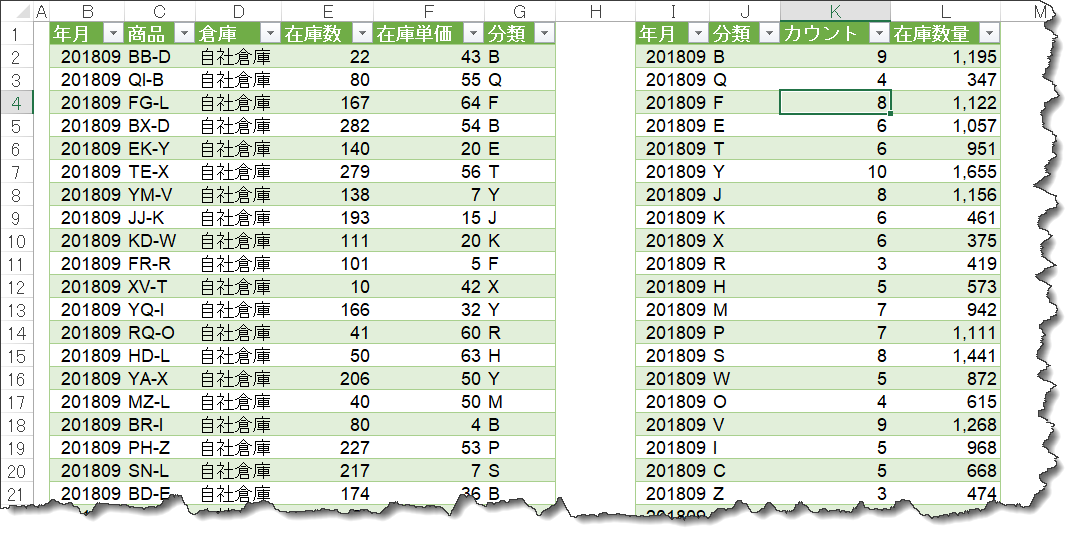
無事、クエリがシートに出力され、左側のInventoryクエリと比べるとその違いが分かるかと思います。
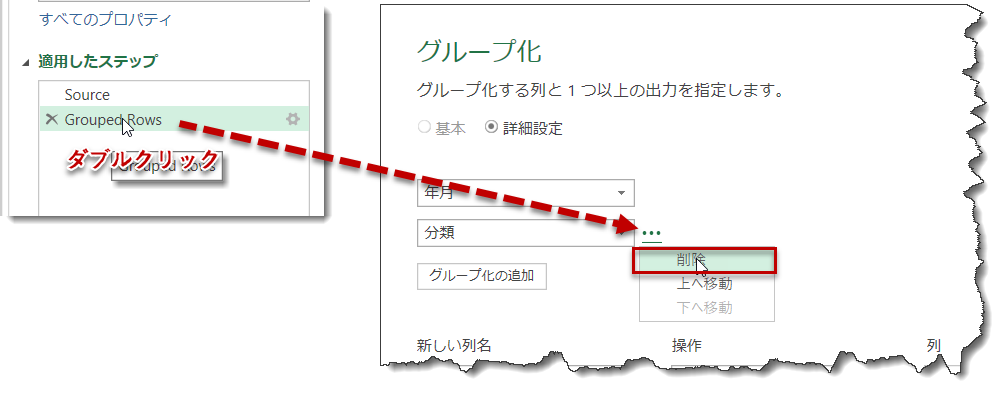
ここで、もう一度Inv_DateCategoryクエリを立ち上げ、クエリエディタの右側の「適用したステップ」の一番最後のステップをダブルクリックし、「分類」の横にある「・・・」から「分類」を削除して全ての設定を適用し、クエリエディタを閉じてみると・・・
先ほど出力したクエリ(分類列含む)が年月だけの結果となって、ワークシート上に出力されるようになりました。Power Queryが便利なところは、このように自由に出力時のフォームを変更できることであり、詳細データから概要データを簡単に作ることが可能であることにあります。
まとめ
- Power Queryではマージ機能を使えば、VLOOKUPのように異なるテーブルから必要なデータを抽出してくることができる
- マージの種類は全部で6つあり、使用場面に合わせて使っていくことになる
- 最も使用するマージの種類は左外部である
- クエリを再利用するには「複製」と「参照」を使う。前者はM言語のソースコードを複製し、クエリ名が違うまったく同じクエリを作ること、後者は1つのクエリを参照し、異なるデータ粒度に変更したり、別の用途で使用したりする
- Power Queryにおけるグループ化はデータの粒度を減らす機能であり、詳細データから概要データへの変換に際して使用される
- グループ化の種類は複数あり、「合計」「最大」「最小」「行数のカウント」等を使い分けていく
マージとグループ化はPower Queryにおいて最も基本的な操作であり、使いこなすのにそれほど時間はかからないと思われます。