Power Queryの中で、最も強力な機能の1つがPivotの解除である。名前から結果をイメージしにくいですが、簡単に言えば、
横に伸びているデータを縦にまとめる
あるいは専門用語でいえば、
データの正規化
となります。
ピボットの解除
ピボットの解除は恐らくPower Queryにおいて、最も強力な機能の1つとなります。ここでは実例を交えて、この機能について解説していきます。以下のようなテーブルがあったとします。
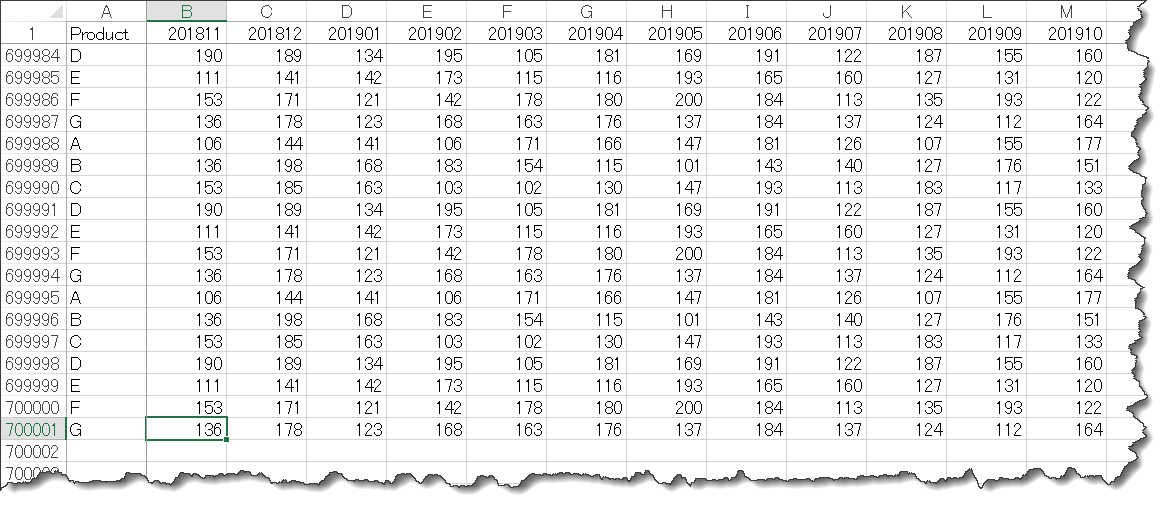
サンプルデータの特徴
A列:商品名(Product)
B~M列:年月別売上高
データ量:70万行
データサイズ:35MB
このデータセットはワークシートに出力されたデータであり、ファイルサイズがかなり大きいものとなっています。ここで例えば、このテーブルでPivotテーブルを作成し、数字分析について行いたいとした場合、実に都合が悪いデータセットとなります。なぜならば、この書式はデータ分析用の書式になっていないためです。
データ分析を行う場合、
1列1属性
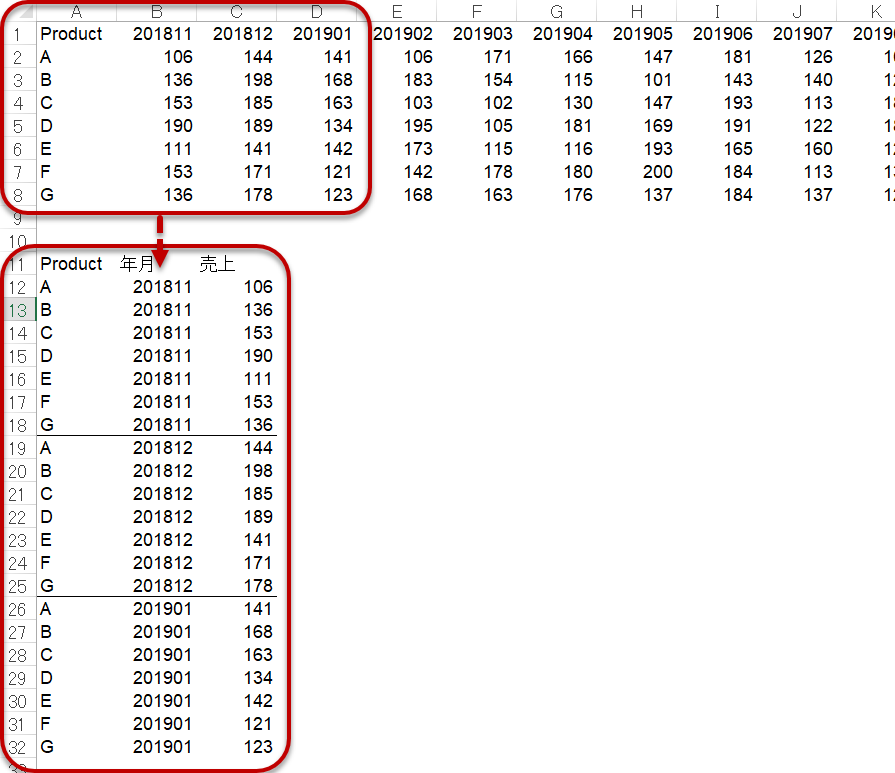
というルールがあり、通常は同じ列に同じ属性のものが入ることになります。この例は、クロス集計(マトリックス表記)による売上高を表示したものであり、この状態から以下の図のように、書式を変更してあげる必要があります。

この図の特徴は[Product]列はそのまま、右に広がっていた年月列がPivot解除後では[年月]という属性列にまとめられ、同じように右に広がっていた各列の数字がも[売上]という列に縦に格納されていることです。
この作業はデータ分析の前処理において最も重要なことの1つであり、
横長のデータを縦長にする
と覚えておくと役に立ちます。
Power Queryによるピボットの解除
「Pivotの解除」という言葉、その意味がピンとこないと思いますが、要するに「横に広がった状態のデータ」がPivotテーブルで集計された状態で、それを元に戻す(解除する=縦長の状態に戻す)作業となります。
Excelでこれをやろうとすると、例えば以下のようなことを手作業で行うことになるため、非常に時間が掛かってしまいます。
これに対して、Power Queryを使えば一瞬でこれを行うことができ、かつ、Pivotを解除した後に縦に増えた大量のデータを格納することができるようになります。
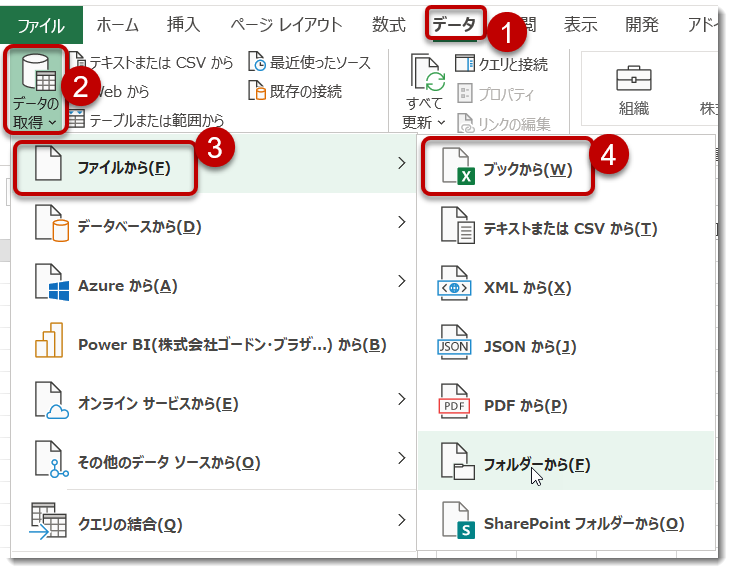
- データの接続
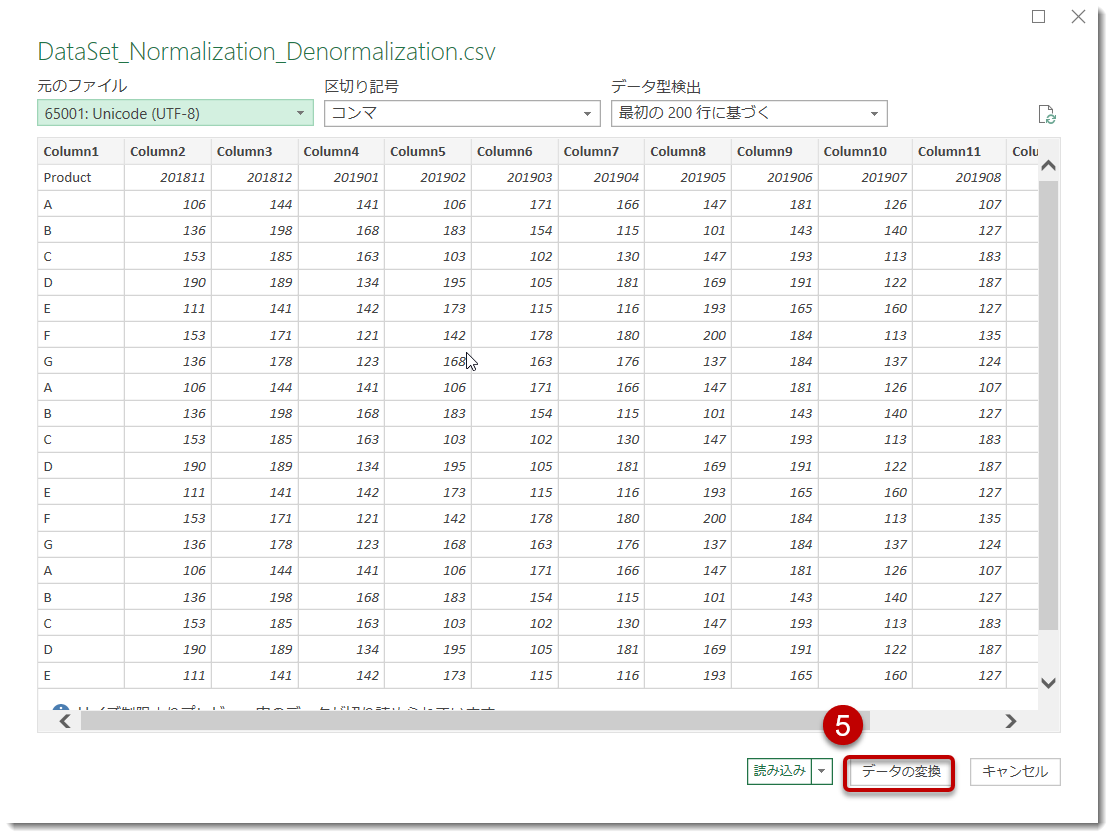
- 対象ファイルを選択し、クエリエディタに読み込む

- 不要なステップを削除する
Power Queryでは、読み込まれたデータに対して、自動的に「データ型の変更」を行う場合があり、「ヘッダーの昇格」の前にこのステップは不要
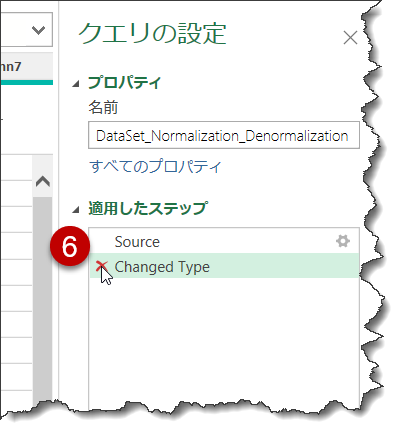
- ヘッダーの昇格を行う
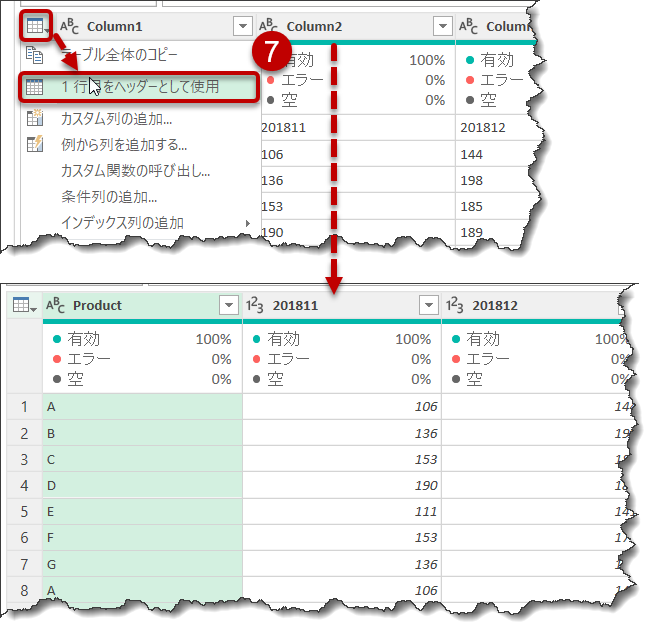
- いよいよPivotの解除を行う。やり方は2つあるが、ここでは[Product]列だけを選択して、「その他の列のピボット解除」をクリック(殆どの場合、「その他の列のピボット解除」を選択することになる)
※ 1列だけでなく、複数の列を選択した状態でもPivotの解除が可能
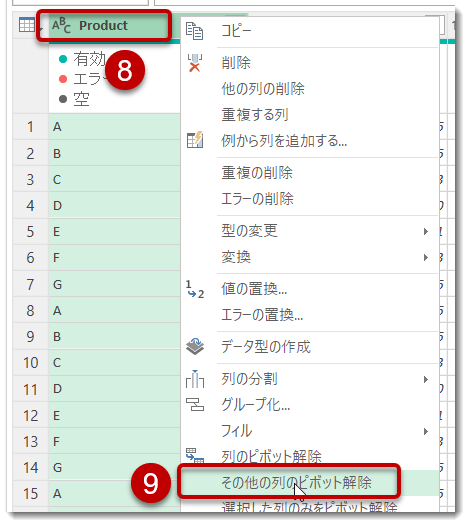
ここで重要なことは、残しておきたい列を選択して、「その他の列のピボット解除」をクリックすることであり、このやり方であれば年月が入っている列がどこまであるかを意識することなく、選択されていない列が全てPivot解除されることになる -
解除後、数式エディタの中を変更し、Pivotが解除されたことを確認
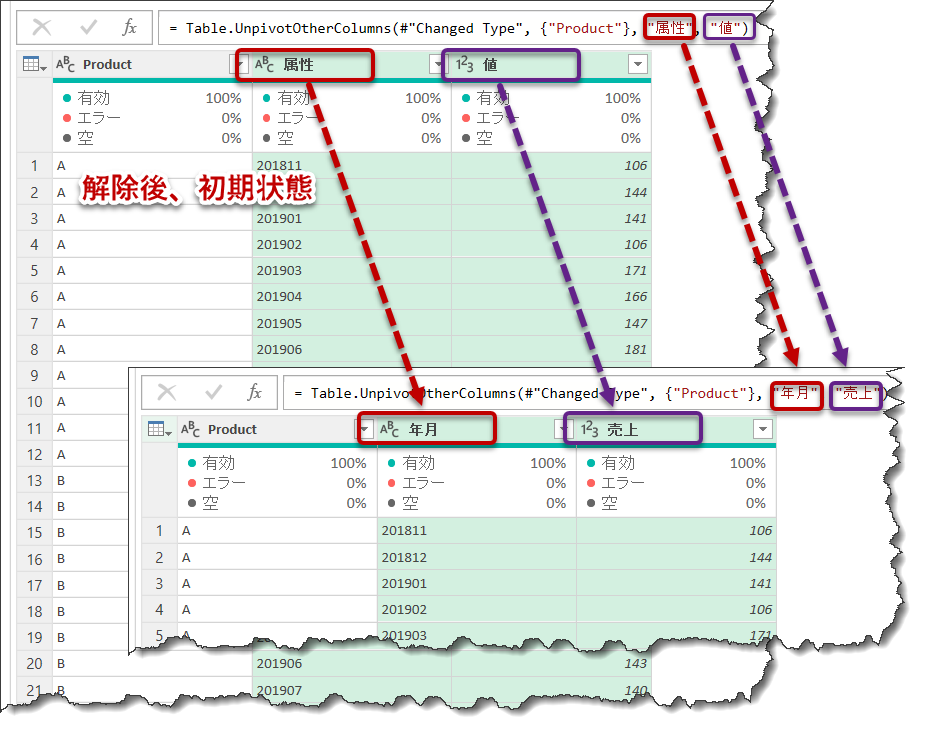
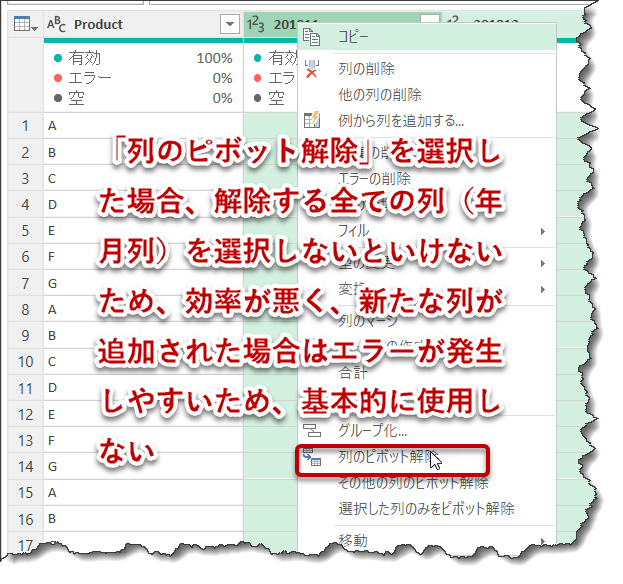
なお、下記のように、「その他の列のピボット解除」ではなく、「ピボットの解除」を選んだ場合、解除する全ての列を選択する必要があるため、基本的には使用しないコマンドとなります
最後にピボット解除されたことで増加した行数について確認してみます。下図の通り、元々70万行だったデータセットが、ピボット解除されたことで840万行(70万行×12ヵ月)に増えたことになります
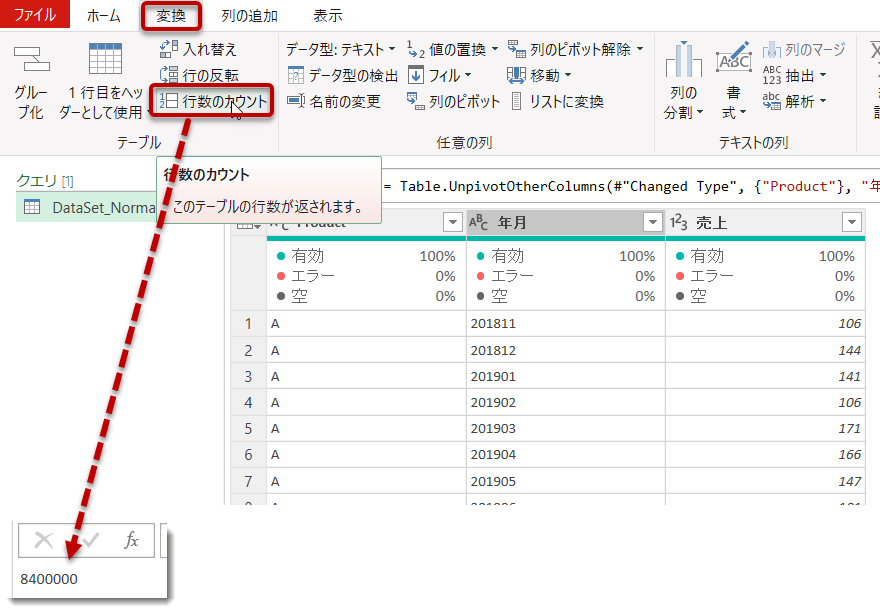
元々70万行でもかなりデータ量は多いですが、これが840万行になったことでそもそもデータをExcelシートに出力できなくなりました。
ピボットの解除の先にあるもの
Power Queryを使い始めた人がよく陥りがちなワナとして、Excelユーザーと同じ考え方をすることです。Power Queryの目的はETL(Extract, Transform, Load)であり、取得(Extract)と成形(Transform)以外に、Loadというオプションがあります。Loadは読み込むを意味しており、データをどこに出力するかが最終的な目的となります。
Excelユーザーであれば、データはワークシートに出力されるものであると全員が認識していますが、Power Queryの場合、ワークシートだけでなく、その他様々な選択肢があり、ワークシートにデータを出力しないことがベストプラクティスであったりします(後述)。
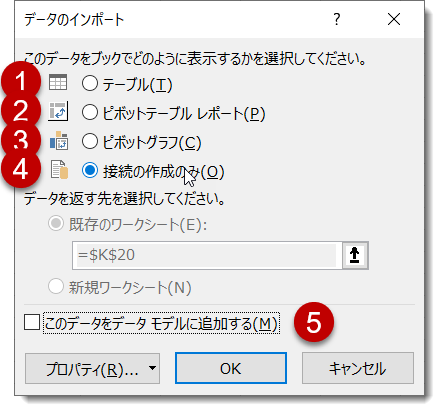
先ほどのクエリを出力しようとした場合、以下5つのロード先があります。
- テーブル
こちらはデータ量が100万行以内であれば、出力したデータを参照し、Pivotテーブルを作ることが可能ですが、上述の通り、データ量が840万行に増えたため、①という選択はありません。 - ピボットテーブル レポート
こちらは、Power Queryの840万行のデータをワークシートに出力することなく、Pivotテーブルを作成することができるオプションです。この場合、840万行というデータセットでもPivotテーブルを作成できるようになります。 - ピボットグラフ
ピボットテーブル レポートと同様、チャートを作ることができ、これを選択するとチャート選択の画面に変わり、840万行のデータセットを使ってExcelチャートが作成できるようになります。 - 接続の作成のみ
こちらは、データを出力させたくない場合に使いますが、データにアクセスできないため、分析ができない状態となります。 - このデータをデータモデルに追加する
最後の出力候補は「データモデル」になります。Excel 2016ではProfessional版、Office 365であれば全てのバージョンにデータモデルがあり、分析用データベースにデータを出力することになります。
ここでは2と5をそれぞれ比較してみます。なお、2はPivotテーブルを使ったことがある人であれば誰でもその機能を知っているのですが、5についてはもう少し解説します。
データモデルとは、データ分析をするための「データベースエンジン」であり、Power BIやExcelの両方に共通してBIを構築する際に必要なものとなります。このデータベースエンジンには特徴があり、(詳細は割愛しますが)特に重要な概念の1つに「列データベース」があります。列データベースの特徴はデータサイズの圧縮率が高いことであり、以下はその例となります。
まずは2と5をそれぞれに対してピボットテーブルを以下のように作ってみると、結果は同じであることが分かります。
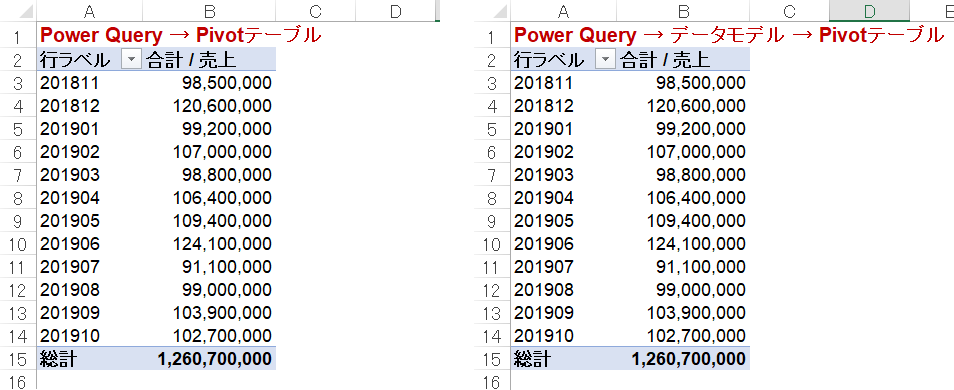
どちらもワークシートにデータを出力していない点においては、上述したベストプラクティスに当たりますが、実はこのデータセットが840万行によって構成されていることを考えると、データモデルにデータを出力することがベストプラクティスになるのです。
上記2つのケースをそれぞれファイルとして保存した場合、保存後のファイルサイズが全く異なることに気が付くはずです。

上にあるExportToDataModel.xlsxはデータモデルに出力したもの、下にあるExportToPivot.xlsxはPower Queryのデータに直接接続してPivotテーブルを作成したものとなります。ご覧の通り、前者(データモデルに出力)のファイルサイズはわずか129KBであり、後者の直接Power QueryからPivotを作成したファイル(5.9MB)の僅か1/45というサイズになっています。
これが上述した「列データベース」にデータを格納した場合のメリットであり、Excelでデータ分析をする際、基本的にPower Queryからデータモデルにデータを出力することがベストプラクティスとなります。
なお、データモデルに格納されたデータを確認したい場合は、以下の手順で出来ます。
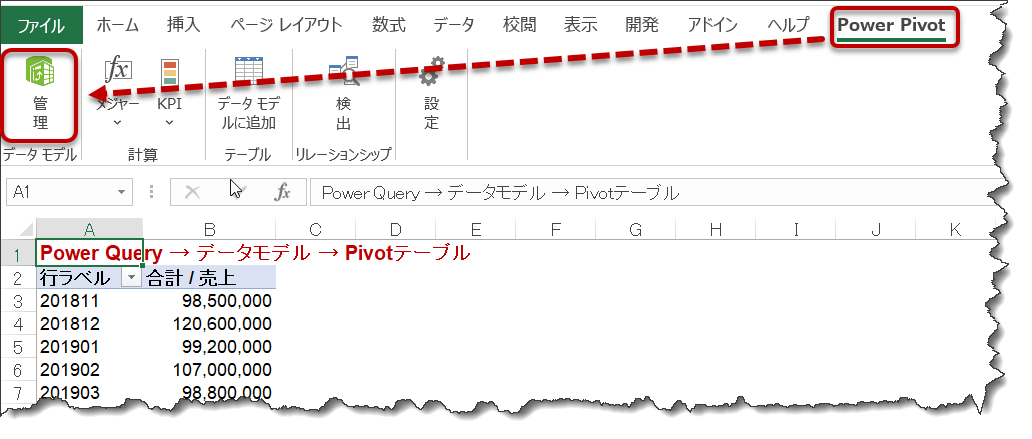
細かく説明しませんが、Excelではデータモデルに格納されたデータはPower Piovtという名称になり、Power Pivotの管理タブをクリックすることでロードされたデータを見ることができるようになります。この状態になって初めて、データベースエンジンによる圧縮の効果が出るようになるわけです。
まとめ
- ピボットの解除はPower Queryにおいて最も使用される機能の1つであり、Excelで手動変換した場合と比べ、莫大な時間を削減してくれる
- ピボットの解除を行う理由は、横に広がっているデータ(クロス集計形式)を分析に適した書式に戻す作業である
- ピボットの解除を行ったことにより、データ量が100万行を超える場合もあるが、Power QueryではExcelのワークシートに読み込まない限り、影響は受けない
- 基本的にデータモデルに出力してPivotテーブルを作成することがベストプラクティス
- データモデルはBI構築に際して最重要な概念の1つであり、列データベースというテクノロジーで大量なデータ分析を可能にするものである