Excelでデータ分析をやったことがある人であれば、データクレンジング*1ほど、時間が掛かる作業はないと知っているはずです。Excelのヘビーユーザーであるほど、書式の異なるデータを”マッサージ”して1つのデータセットとして結合する作業をしてきた経験が多いのではないかと思います。私もそのうちの1人で、Power Queryを使用する前までは以下のステップをベストプラクティスとして考えていました。
以前の集計方法
Power Queryが登場する前までは、以下のような方法でデータを最新の状態に保っていました。
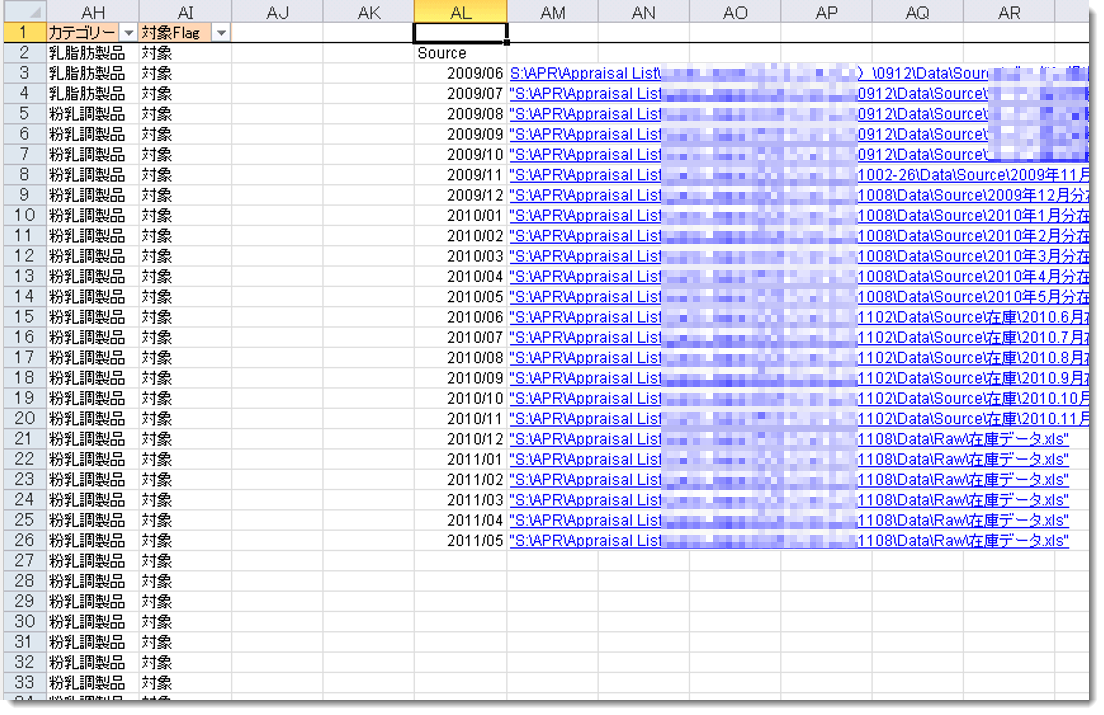
- 基データ(Excel / CSV等)を全て特定し、下図のようにExcelの同じシートに時系列別に値貼り付けを行っていく
-
その際、重要なのはデータソースをリンクで残すことであり、これにより他の人がオリジナルデータの在り処を容易に特定できるようになる
-
貼り付け後のデータは既に基データではないため、対象Flag等の列を追加し、自由に加工できるようにデータを追加していく
-
在庫・売上・財務情報等、必要なデータを全て集計し、1つあるいは複数のファイルでPivotで時系列に集計し、更に分析を行う(下図)
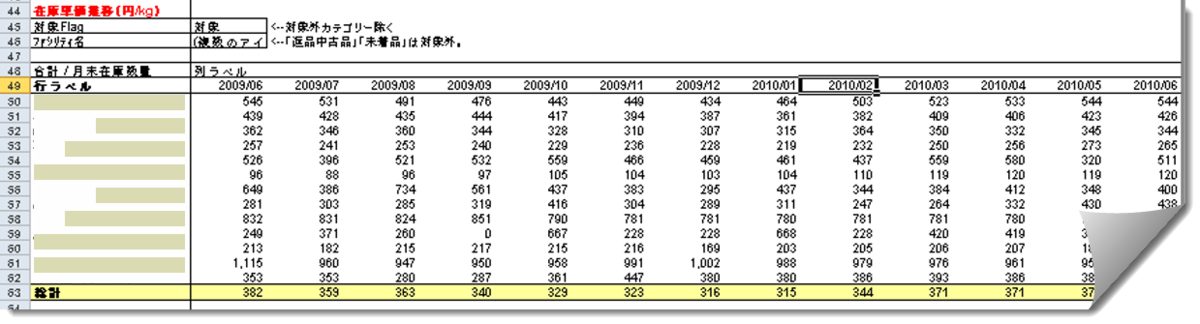
Power Queryとデータモデルを基本とする現在ではもはや考えられないようなやり方だったのですが、少なくとも2016年くらいまではこれがファイルベースのデータソースでデータ分析をするため、データ粒度を確保しつつ、基データもタッチしなくて済むやり方だったのです。
この方法の良いところはデータが同じブック内に格納されているため分析しやすいこと、細かい部分について見たい場合の検索が楽であることですが、デメリットとして
- ファイルサイズが大きくなってしまう
- 無駄に数式が多くなるとファイル操作時のパフォーマンスが落ちてしまう
- 在庫と売上を紐付けて分析を行うのに、スナップショット(現時点)ベースの分析がメイン
であったことが挙げられます。このやり方はPower Queryを知らない会社では重宝されるかもしれませんが、Power Queryを活用できる場合、二度とこのようなやり方をやらないのが賢明です。
現在の集計方法
Power Queryを活用してデータを集計していきますが、過去紹介したExcelやCSVの結合方法が良い事例になっていると思います。
ヘッダー名が同じで、データを結合する前の書式が同じ場合、上記のやり方でほぼ問題なく対応できると思います。現在のやり方は以下の通り。
- 結合するためのファイルがExcelとテキスト(CSV/TXT)のどちらか?
- Excelの場合、Excel.Workbook関数を用いてデータを抽出。テキストの場合、Binary.CombineもしくはCsv.Documentを用いてデータを抽出。
- どちらの場合でも、最後にデータを結合する際、Table.Combine(前ステップ名[Data])という数式で展開を行うこと。これにより、違うシートやファイルで列の順番が違っていた場合、あるいは、列名が追加されていた場合でも、全てのデータが過不足なく抽出される
※ 言い換えれば、Table.ExpandTableColumnというM言語*2は使用しないことになる
詳細は上記ブログをよく読んで頂ければ分かりますが、今回紹介するのは実務上、最も遭遇しやすい事例となります。
ヘッダーの昇格が使用できるケース
Power Queryではヘッダーの昇格(Table.PromoteHeaders)という関数があります。Tableベースのデータでない限り、Excelのワークシート上にあるデータ、あるいは、テキストファイルの中のデータはヘッダーの昇格を必ず行う必要があります。
例えば、以下のようなM言語でExcel内のデータを抽出することができますが、最後のステップにTable.PromoteHeadersがあるからこそ、アウトプットにヘッダー名が表示されるようになるのです。
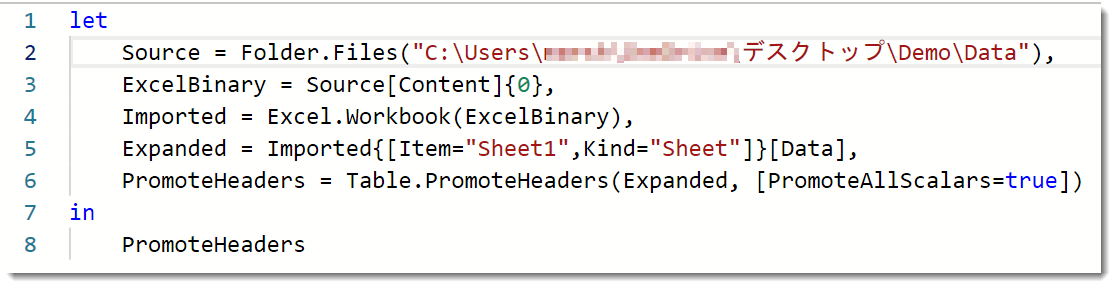
上記M式のアウトプット
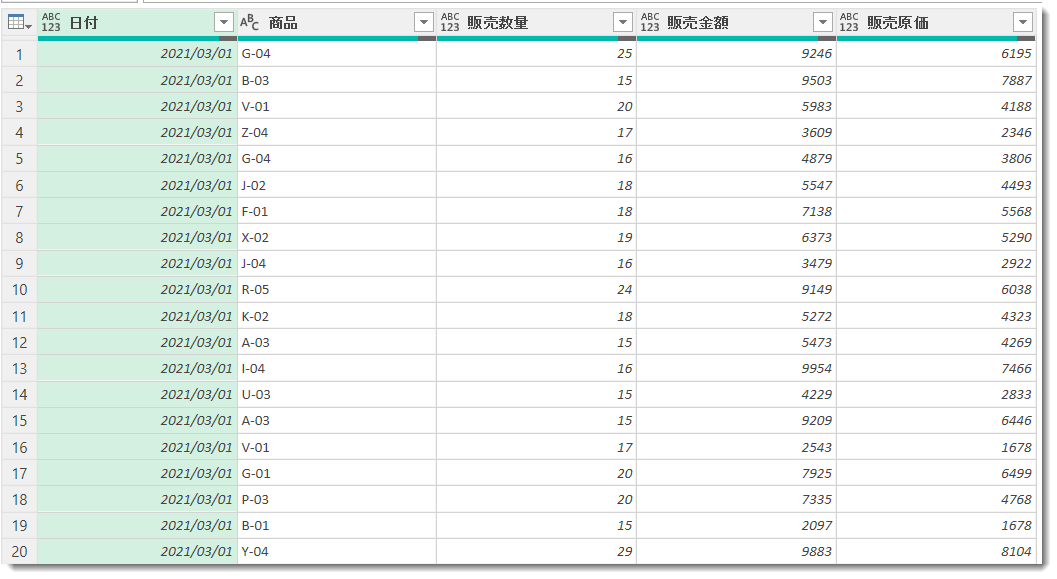
M言語に慣れている人であれば、このスクリプトが何をやっているのかが分かると思いますが、以下それぞれのステップで実行されていることを簡単にまとめておきます。
- Source
Folder.FilesというM言語を使用し、フォルダパスの直下にある全てのファイルのリストを取得 - ExcelBinary
取得されたリストの一番上のものにアクセス([Content]は列、{0}は1行目、これらを組み合わせると、1行目の[Content]という列の中身にアクセス、となる) - Imported
Excel.Workbook関数を使用し、ExcelBinaryでアクセスしたBinary(データを格納するコンテナのようなイメージ)の中身を取得 - Expanded
Item(名前と認識しておけばOK)がSheet1、Kind(種類:Sheet, Table等)がSheetとなっている行にある、[Data]という列の中身を抽出 - PromoteHeaders
抽出されたデータのヘッダーを昇格
上記ステップは1つのExcelの中からシート内のデータを抽出する際の1つのやり方ですが、覚えておくと応用が利きますので、1つのパターンとして認識しておくのが良いと思います。
このケースでは、最後にTable.PromoteHeadersを使用すれば、ヘッダーが昇格されますが、今回はそれができないケースを紹介します。なお、Table.PromoteHeadersを使用しないで、Excelデータのヘッダーを昇格させる場合は、下記日記をご参考ください。
ヘッダーの昇格が使用できないケース
ヘッダーが使用できない場面は以下のようなケースです。まずはサンプルファイルをダウンロードしてください。
サンプルファイル(ダウンロード)
上記URLにアクセスし、以下のようにダウンロードボタンをクリックして、サンプルデータをダウンロードしてください。
Zipを解凍すると、Demo_AdvancedHeaderというフォルダが出現し、その直下に「RenameSelectHeaders.xlsx」というExcelが入っていますので、それを開く。ここで以下の操作を行います。
- セキュリティの警告がある場合、「コンテンツを有効にする」をクリック
- 「データ」>「データの取得」>「Power Queryエディタの起動」
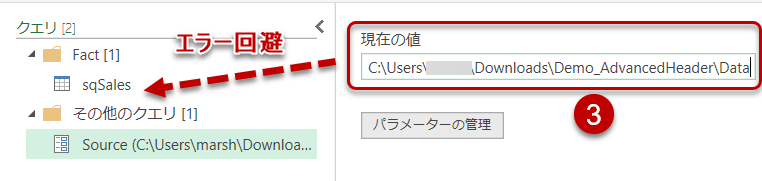
- クエリエディタが立ち上がるので、Sourceというパラメータをクリックし、解凍したDataフォルダのパスを入力する

- フォルダパスが正しく入力されると、sqSalesというクエリが正しく反映されるが、この例では解凍先はDownloadsフォルダ
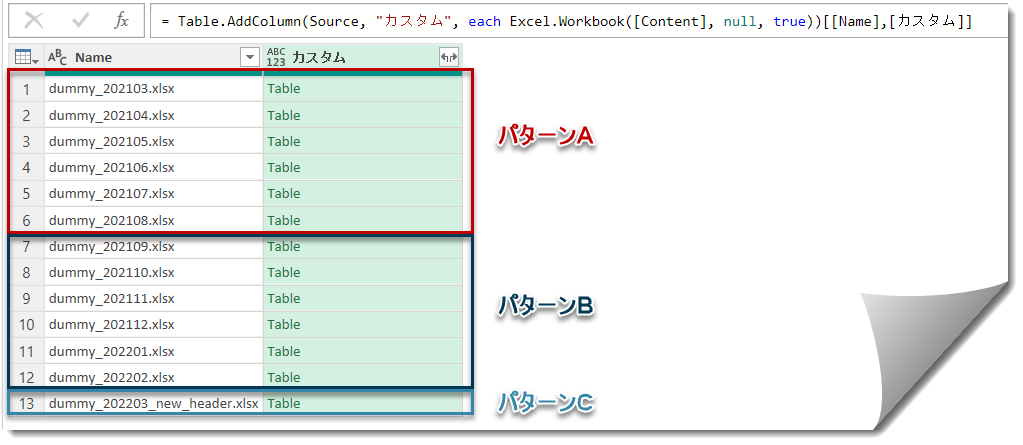
ここまで行えば、前準備は終わりですので、ここからsqSalesのクエリの中身を見ていくことになります。sqSalesクエリをクリックすると、以下の画面になりますが、3つのパターンが存在します。
なお、このsqSalesのクエリの目的は、Name列にある全てのファイル(全て1シートのみ)のデータを正しく結合することであり、これを行うためには最後のステップが必ず
Table.Combine(前ステップ[Data])
になることが重要です。そのため、[Data]列のTableを展開する前に、全てヘッダーの昇格を終えている必要があり、以下それぞれのパターンでこれを行うためのハードルが存在することになります。
パターン別違い
パターンAは202103~202108までのデータで、Data列の空白をクリックすると分かりますが、Table.PromoteHeaders(もしくは、Excel.Workbook(ExcelBinary, true, true))いう式が使えるパターンになります。

パターンBは202109~202202まで、ヘッダーまでnullが2行入った状態のデータとなっています。
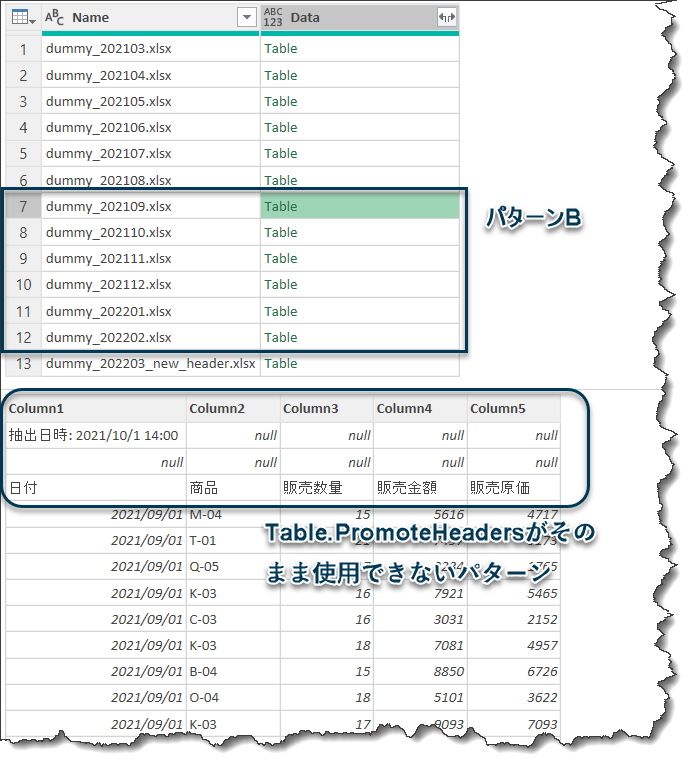
パターンCはパターンBを踏襲しつつ、列が2つ追加されたことに加え、列名もなぜか微妙に変わっているパターンです。
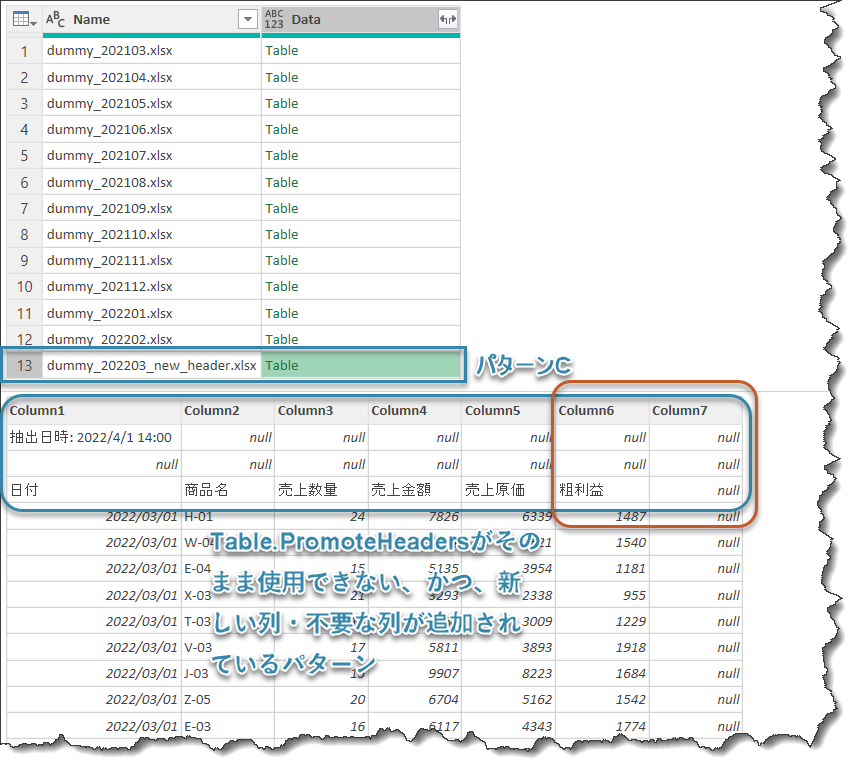
実務上、ある日突然データの書式が変わることも多いので、今まで説明してきたやり方ではエラーが発生してしまいます。
問題点
ここでどのような問題が発生するのかについて見ていきます。まずはsqSalesをクリックし、詳細エディタ(「表示」タブ >詳細エディタ )を立ち上げます。以下の構文で構成されていますが、ここでExcel.Workbook内のnullをtrueに書き換えてみます。
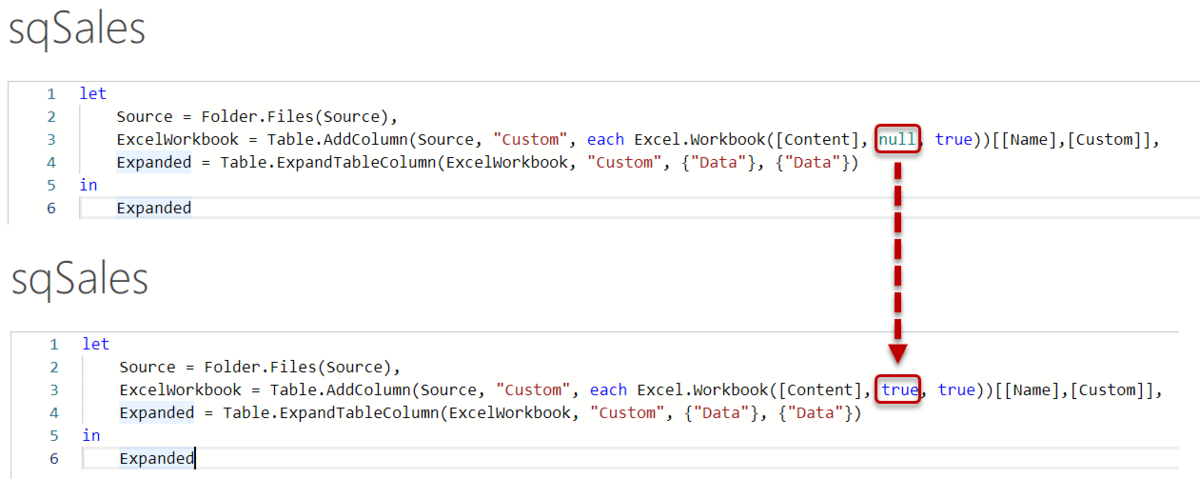
すると、パターンAは展開する前にヘッダーが昇格された状態になりました。
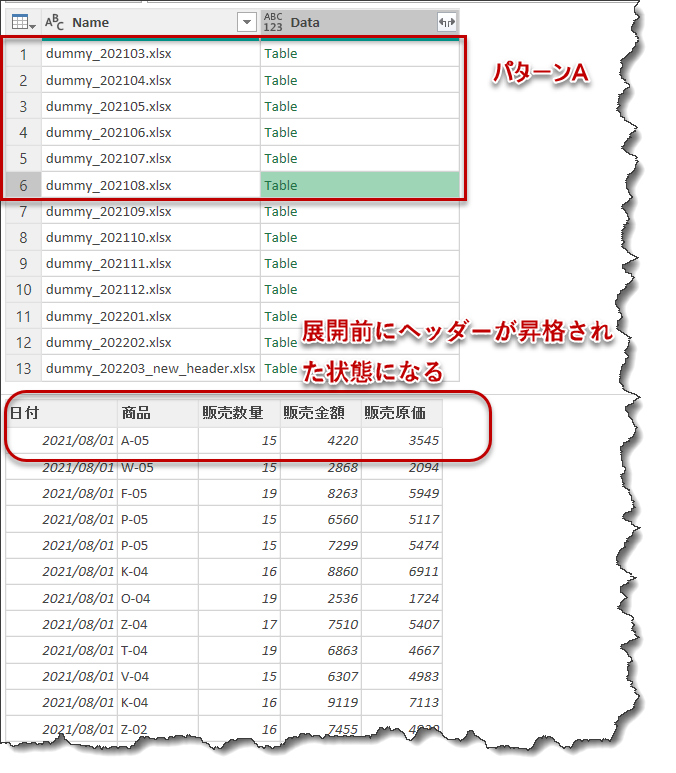
全てのパターンがこれと同じであれば、そのままTable.Combineを使用して列順序や列名に関係なく、全てを過不足なく結合できるのですが、パターンBを見ると以下のようになってしまいます。
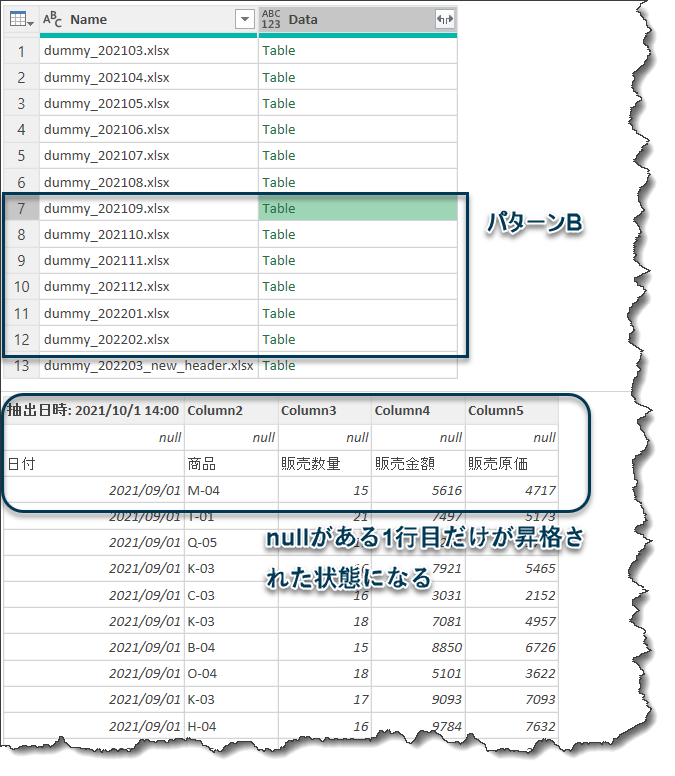
これでは当然上述したやり方は通用せず、例えTable.Combineで結合したとしても、追加作業(追加ステップ:nullを削除等)が発生してしまいます。何より、デモでは
[日付]、[商品]、[販売数量]、[販売金額]、[販売原価]
という順番になっていますが、何かの理由で別のファイルが
[日付]、[商品]、[販売金額]、[販売原価]、[販売数量]
という順番になった場合、Table.Combineではもはや正しくデータを結合できない状態になってしまいます。
パターンCもパターンBと同じになりますので、説明は省略しますが、列が追加されていることや、列名が変更となっています。パターンAとパターンBとデータを結合するためには、不要な列を削除したり、列名を変更したりする必要が出てきます。このパターンCが実は1番厄介で、一回で結合できるようにするためには少しテクニックを駆使する必要があります。
考え方
今回はここまでにしますが、デモデータを使って、どうやれば効果的にこれら3つのパターンを1つのデータセットとして結合することができるのでしょうか?いろいろなやり方がありますが、以下ヒントとなります。
- パターン別に結合するためのクエリを3つ作り、最後にまとめて1つのクエリとして結合する
- 全てのパターンに通用するカスタム関数を作り、各ファイルに対してまとめてそれを適用する
- 数式バーの中身を少し書き換えて従来のTable.Combineを使って結合する
全て実現可能なやり方ですが、次回は3について詳細に見ていくことにします。