前回は書式が異なるデータを集計しようとした場合、いくつかハードルがあることを話しました。
サンプルファイル(フォルダパスの修正方法は上記第1回をご参照)
今回はその続きで、いくつかのテクニックを使って簡単にデータを抽出できてしまうことを紹介したいと思います。
抽出のパターン
前回の最後に、下記3つのパターンで抽出が可能であると述べました。個人的には初心者は1、Power Queryの玄人は2、M言語を少し知っている人は3を試すのが良いと思いますが、今回は3について話をしていきたいと思います。
- パターン別に結合するためのクエリを3つ作り、最後にまとめて1つのクエリとして結合する
- 全てのパターンに通用するカスタム関数を作り、各ファイルに対してまとめてそれを適用する
- 数式バーの中身を少し書き換えて従来のTable.Combineを使って結合する
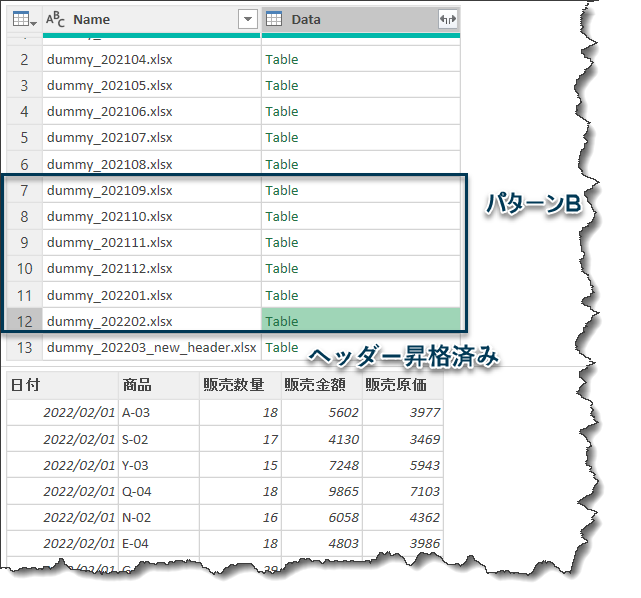
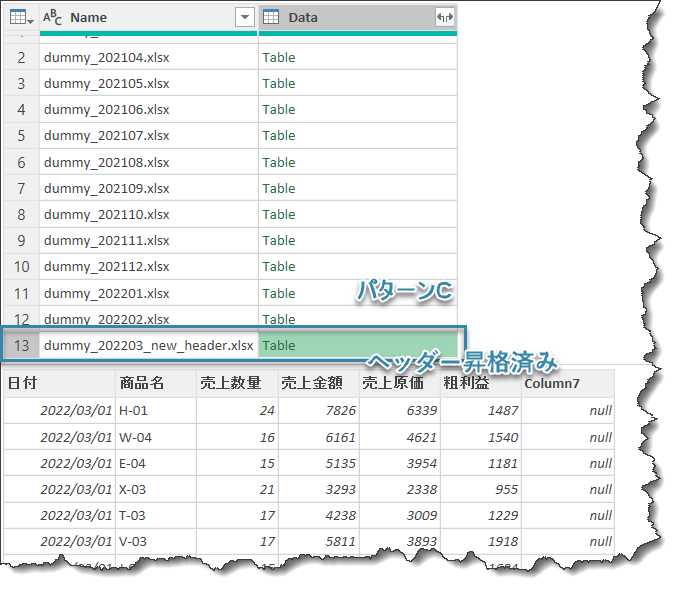
前回使用したsqSalesを再利用します。なお、sqはstaging queryの略で、最終的に出力用のクエリではなく、途中で繰り返し再利用できるクエリという意味になります。個人的に好んで使用しているネーミング表現です。念の為、パターン別の画像を再度載せておきます。
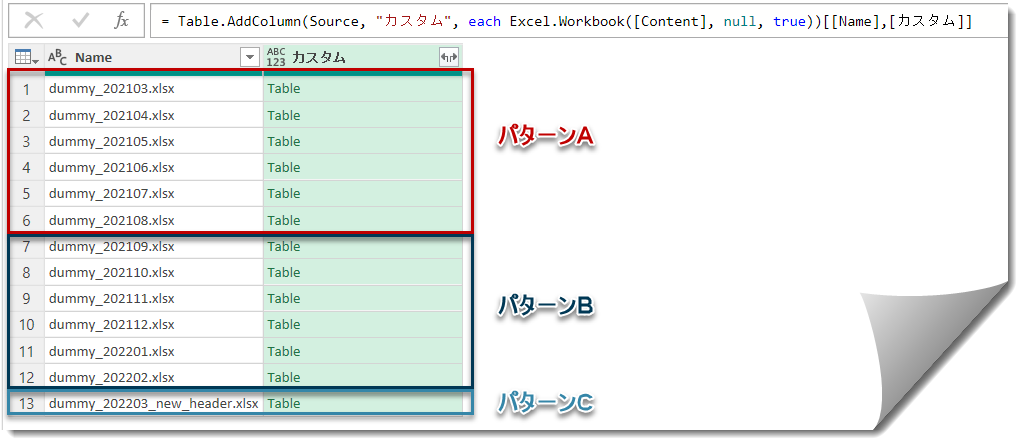
Table.TransformColumnsの使用
Power Queryの言語の中で、どの関数が好きかと聞かれれば、恐らくこの関数は入っていることは間違いないでしょう。Table.TransformColumnsという関数を使用して、Table.Combineを使用する前に、全てのパターンのヘッダーを正しく昇格していきます。やり方を紹介するために、Table.TransformColumnsについて紹介をしておきます。公式ドキュメントは以下の通りですが、読んでいても面白くないので、いくつか実例を見てみます。
実例1:全ての列をテキストに変更
データ処理に際して、全ての列をテキスト型に変換してから、最後に各列のデータ型を指定することがあります。その場合、以下の式を入力すれば、全ての列がテキストに変換されます。
= Table.TransformColumns(前ステップ名, {}, Text.From)

これにより、テキストを操作する関数を使うことができるようになり、エラーの発生を防ぐことが可能になったりします。
実例2:1つの列に対する処理を行う
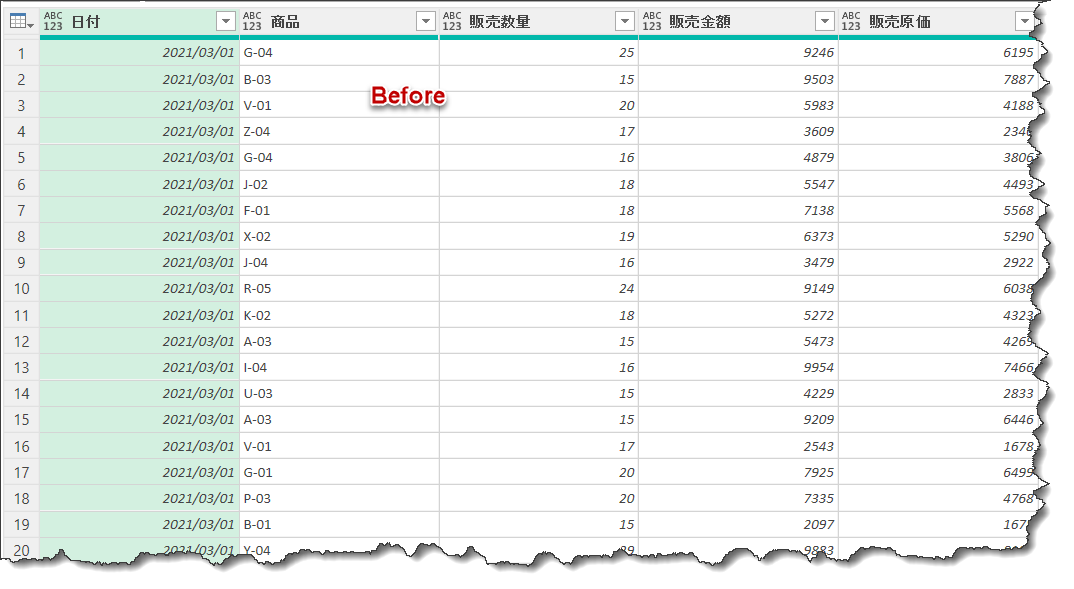
上記Afterの状態で、以下の式を入れてみます。
= Table.TransformColumns(Custom1, {"日付", Date.From})
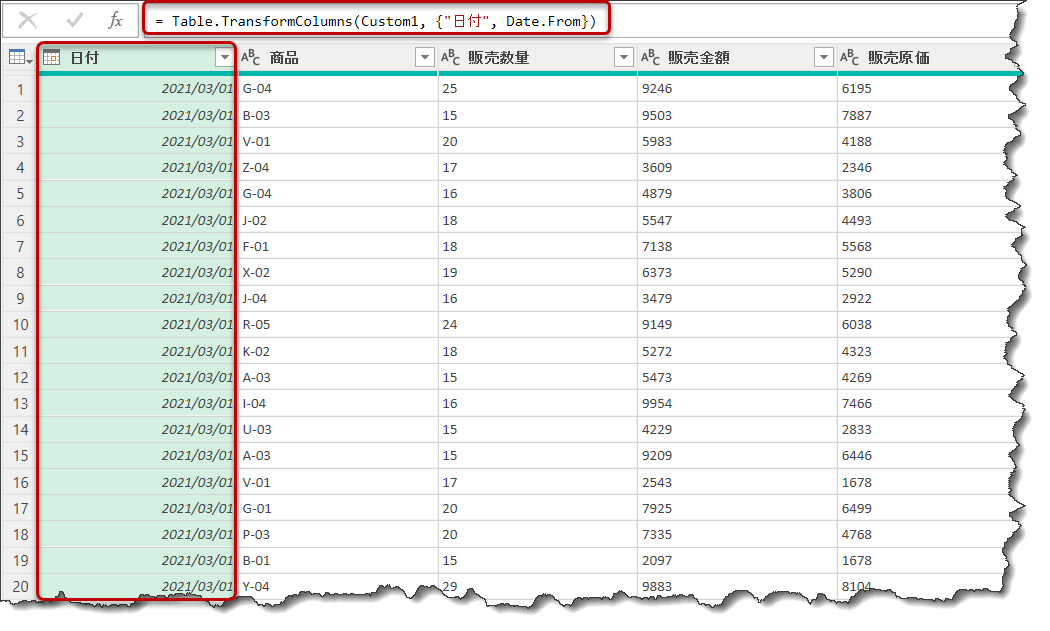
ご覧の通り、Date.Fromという関数が入ったことで、[日付]列は日付型に変換されました。この[日付]列に対して、下図のように追加で処理を加えてみます。
= Table.TransformColumns(Custom2, {"日付", each Date.AddYears(_, 1), type date})
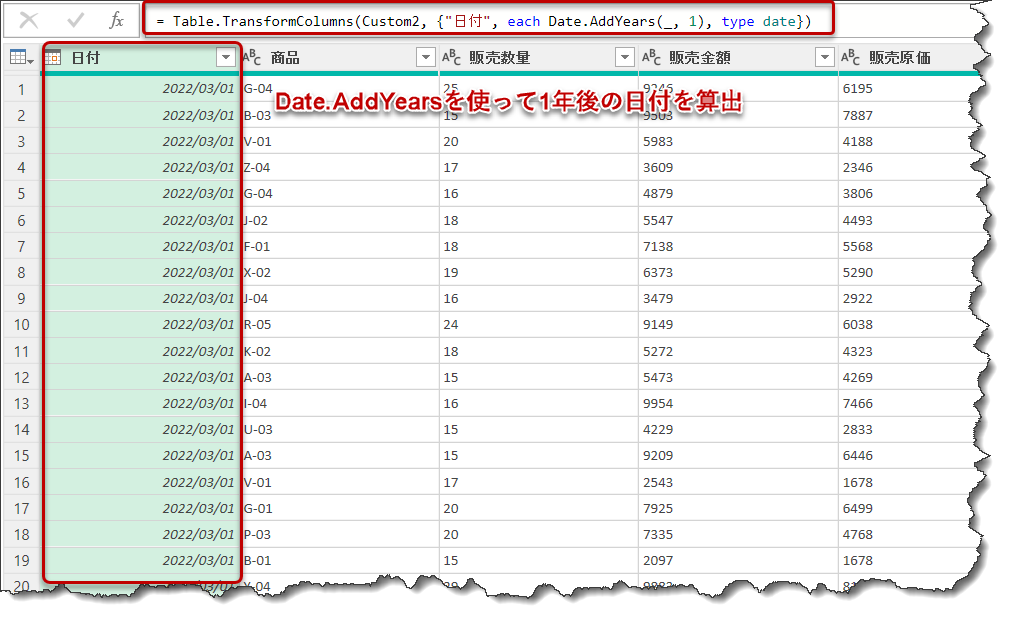
この数式により、規定の年月日から1年後の日付にTransformされました。eachは「それぞれの行(セル)に対して処理を行う」という意味であり、
[日付]列のそれぞれの行(セル)に対して、1年を追加
という処理が行われました。
実例3:複数の列に対する処理を行う
続けて、以下の式を入力してみる。
= Table.TransformColumns(Custom3,
{
{"商品", each Text.Replace(_, "-", "=")},
{"販売数量", Number.From}
}
)
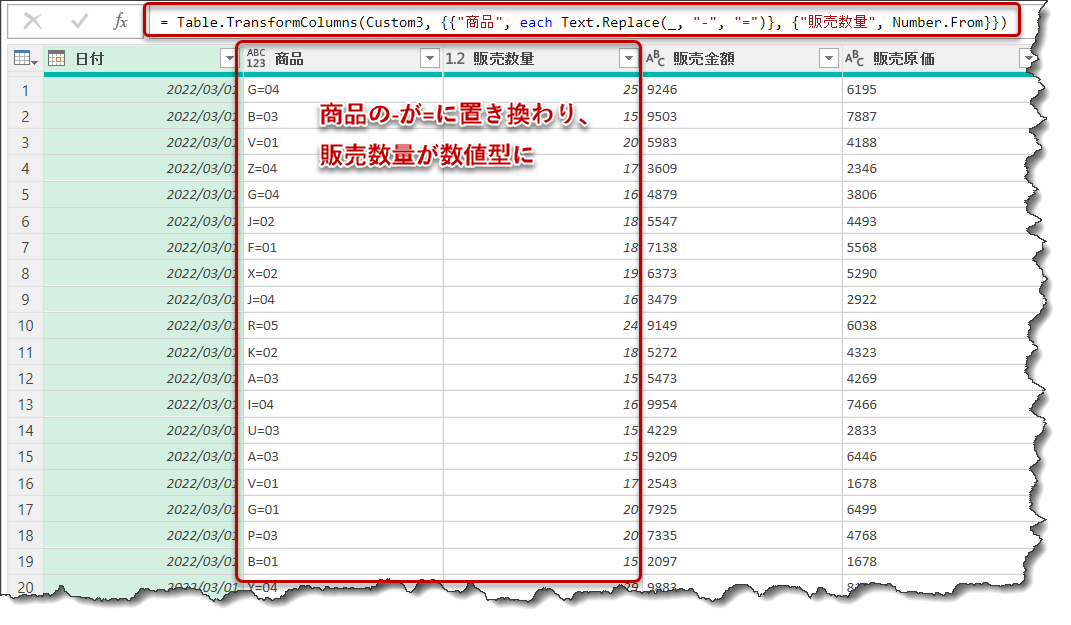
Table.TransformColumnsは選択した列に対して個別に処理を行うことも可能です。この例では、[商品]列の-を=に変更しつつ、[販売数量]列のデータ型を数値型に変更しています。同時に複数の列を処理できることから、非常に使い勝手が良いことが分かります。
標準UIを使って、ボタンぽちぽちしてもこの関数が出ることは多いのですが、上記紹介した3つの事例を念頭に入れ、コードを少しだけマニュアル修正するだけで楽に期待する結果を得ることができるようになります。
展開前にヘッダーの昇格を実現
いよいよデモデータを使用して、データを結合する前に全てのファイルのヘッダーを昇格していきます。おさらいですが、ヘッダーを昇格する前の状態(パターンA~C)は下記の通りです。

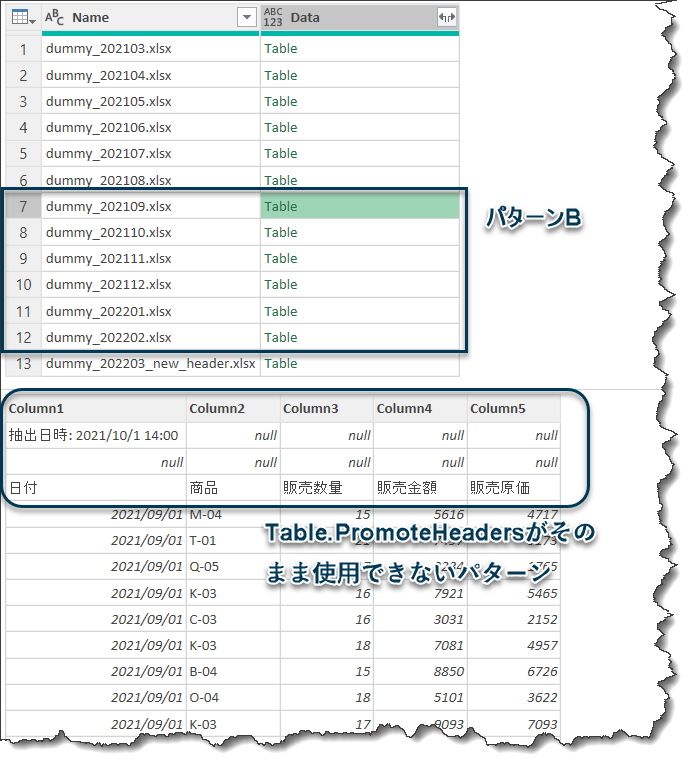
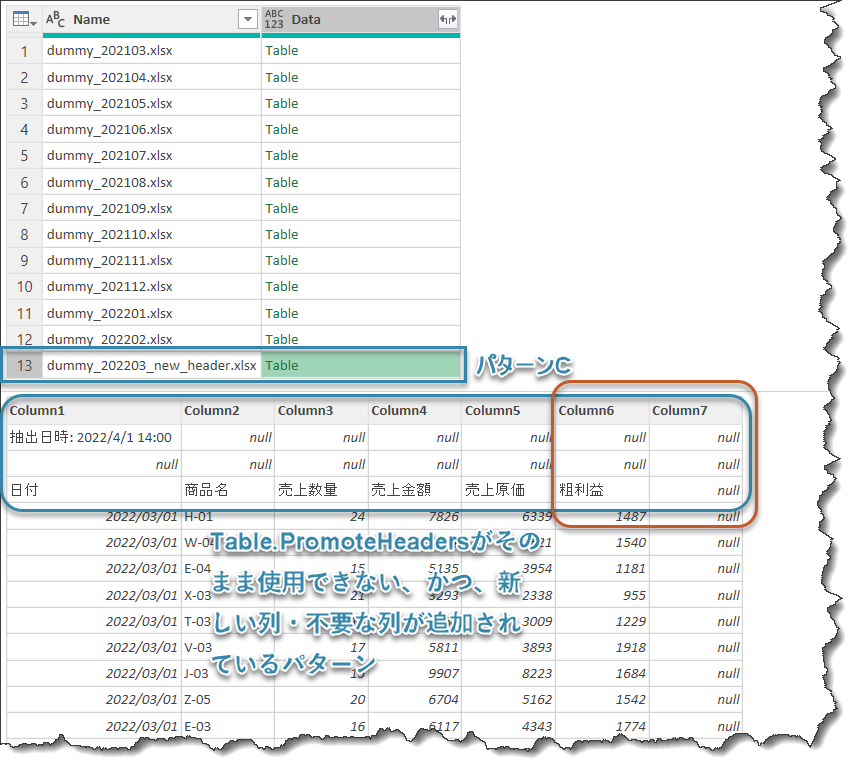
繰り返しになりますが、Table.Combineを使用することが最後のステップになりますので、
全てのファイルでヘッダーが昇格された状態
へ変換する必要があります。データを展開する前にこれを実施する必要があるため、先ほど紹介したTable.TransformColumnsを使用します。ヘッダーを全て昇格するための構文は以下の通り。

これにより、パターンA~Cまで、全てのファイルのヘッダーが昇格される状態となりました。
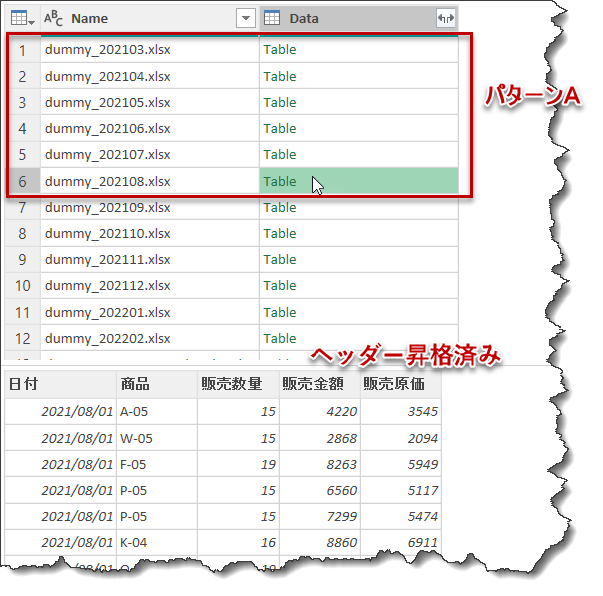
この結果において最も重要なステップは5行目のSkipRowsと6行目のPromoteHeadersとなります。まず5行目ですが、以下の数式となっています。
= Table.TransformColumns(Expanded, {"Data", each Table.Skip(_, each _[Column3] = null)})
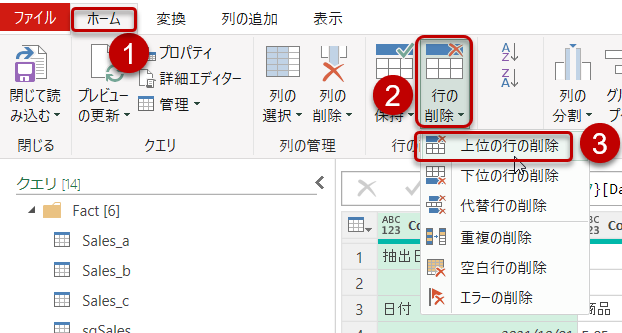
Table.TransformColumnsは解説した通り、[Data]列に対する処理を行うものですが、どのような処理を行ったかというと、Table.Skipという関数を使った処理となります。Table.SkipというM言語は通常、以下のUI操作を行うと自動的に挿入されます。
①~③
④~⑤
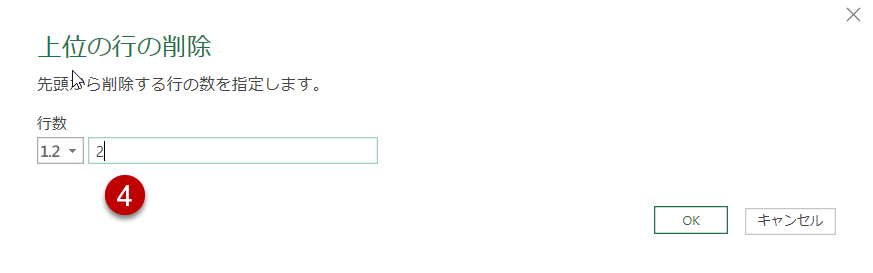
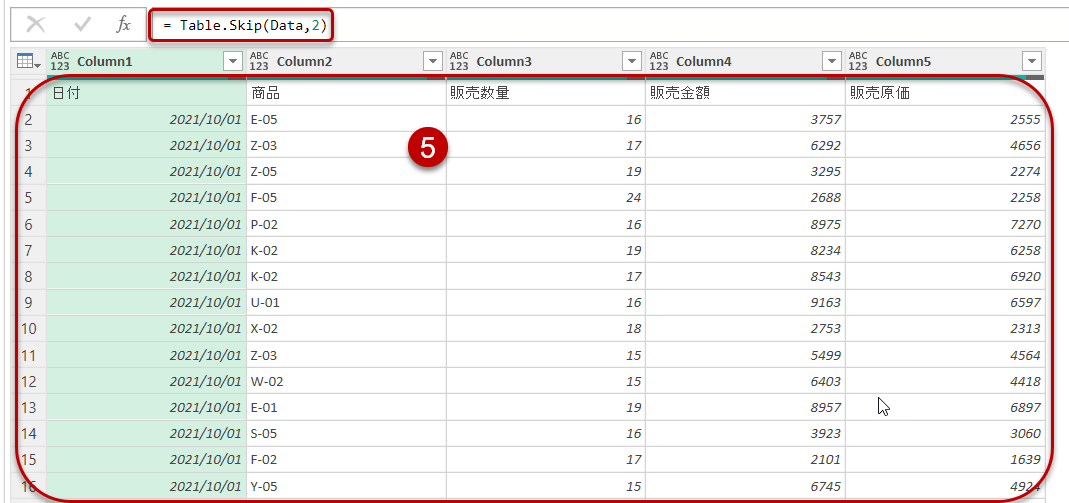
すなわち、Table.SkipはUIを操作した場合の「上位の行の削除」というコマンドに当たるわけです。Table.Skip(前ステップ名, 2)とある場合、テーブルの上位2行目をスキップした残りのデータを抽出せよ、という意味になります。この2の部分は定数でも良いし、パラメータ化した変数でも良いのですが、もう一つの使い方として、2を条件分岐として使用することです。
例えば、下記クエリは上記Table.Skipのステップを入れる前のクエリですが、ここでは目視で上位2行を削れば、ヘッダーの昇格ができることが分かっています。

しかしながら、例えば他のファイルは必ずしもこのクエリと同じように、2行目までをSkipすれば良いとは限りません。例えば、3行目までnullとなっていた場合、Table.Skipでは3行目のnullが残ってしまい、そのまま知らずにヘッダーの昇格を行うと、このnullの状態をそのまま昇格してしまうことになります。
試しに上図のクエリに下記ステップで2行目以降にnullの行を5行追加してみる。
= Table.InsertRows(Data,
1,
List.Repeat({
[Column1 = null, Column2 = null, Column3 = null,
Column4 = null,Column5 = null]}, 5)
)
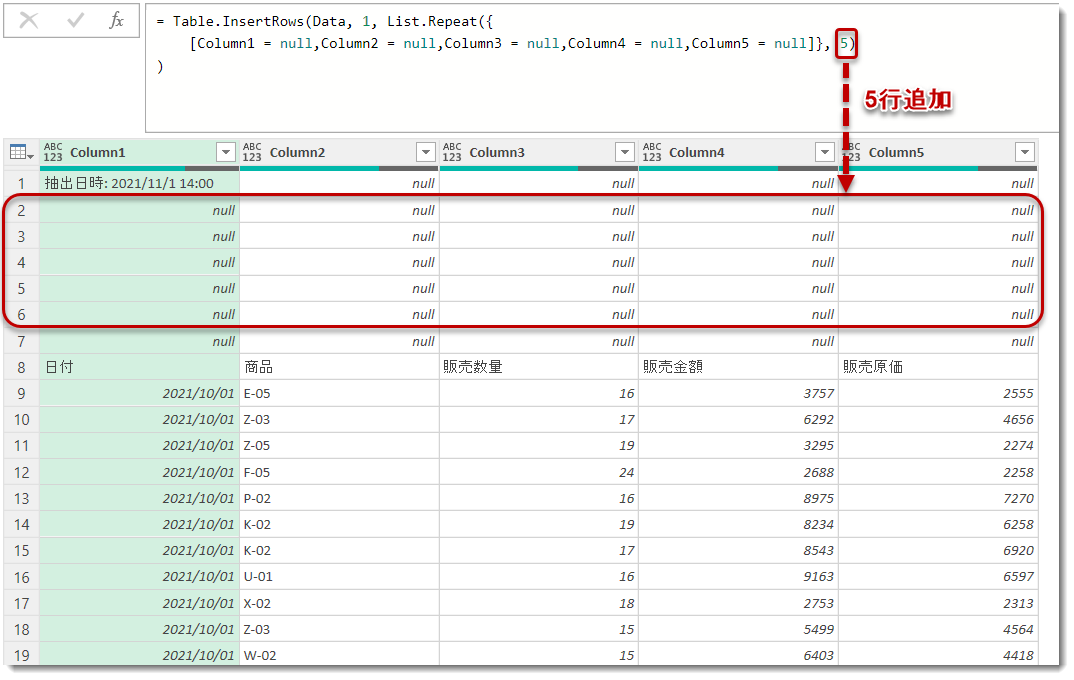
ここで先ほどのTable.Skipの式は下図のようになり、ヘッダーの昇格が出来ない状態になってしまう。
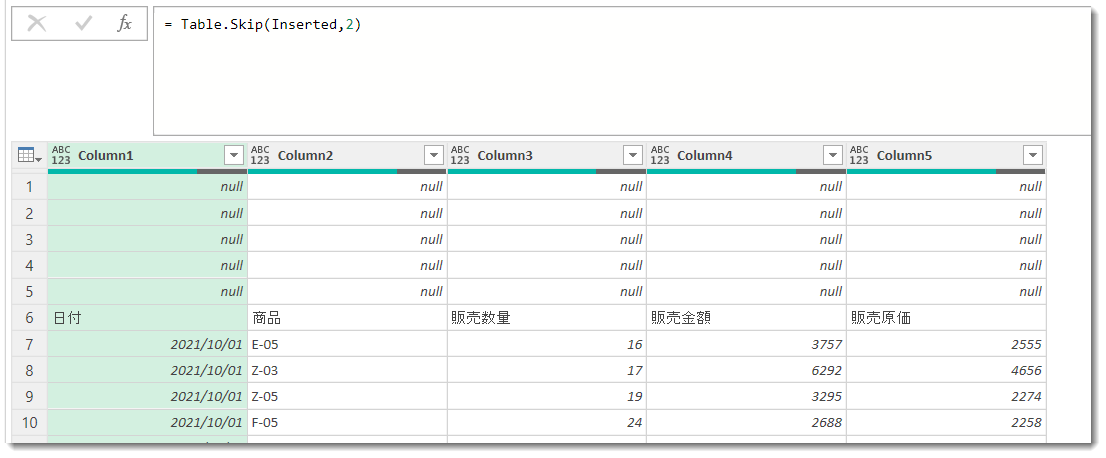
一方、このTable.Skip(Inserted, 2)をTable.Skip(Inserted, each [Column3] = null)に変更すれば以下の通りとなり、この後Table.PromoteHeadersでヘッダーの昇格ができるようになります。

この式の読み解き方は、
[Column3]列がnullである限り、行をSkipする
ですが、Loop処理のような特徴を持っています。これをTable.TransformColumnsと一緒に使った場合、
= Table.TransformColumns(Expanded, {"Data", each Table.Skip(_, each _[Column3] = null)})
という式になります。[Column3] = nullを指定した理由は、[Column3]であれば[Column1]のように、直下にテキストが入っていない可能性が高いことを想定したもので、[Column1]には「抽出日時○○」というテキストが入っているため、each _[Column1]にしてしまうと、nullが除外されないまま、Loop処理が終わってしまうからです。
もう一つ留意点として、eachの後に意図的に_(アンダースコア)を入れていますが、こちらはそれぞれの行(この場合、[Data]列の中身)の中の[Column3]に対して、Table.Skipを実施していることを明示したものであり、アンダースコアがなくてもこの場合は特に問題ありません。
そして、最後のステップ「PromoteHeaders」ですが、下記の通り、もう一回Table.TransformColumnsを使って、[Data]列の中身に対して処理を実施しています。
= Table.TransformColumns(SkipRows, {"Data", Table.PromoteHeaders})
これがTable.Combineを使用する前に全てのデータのヘッダーを昇格するやり方で、非常に応用が利くものですので、パターンの1つとして覚えておくと便利です。
データの結合及びその後
ここまでくれば、あとは1ステップのみ。[Data]列を右クリック > ドリルダウン
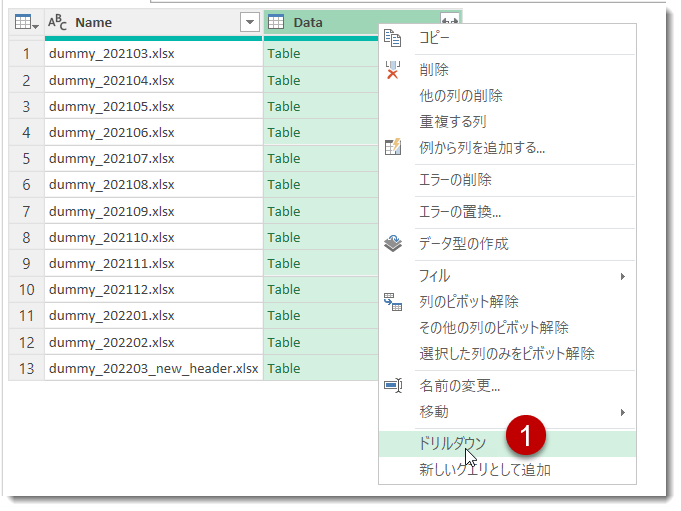
列をドリルダウンすると、Power Queryは以下の式を返します。
= 前ステップ名[列名]
この動作はぜひ覚えて頂きたいのですが、要するにその列をリスト化したものとなります。この例では
=PromoteHeaders[Data]
となりますが、下図のように、外からTable.Combineで囲ってあげるとリストとなっているTableの中身を全て抽出して、列名・列順に関係なく、漏れなく全てのデータを結合することができます。
結合結果は以下の通りですが、ここで意外なことが起こっています。
① なぜかnullが出現している
② 同じ属性の列名が複数存在している
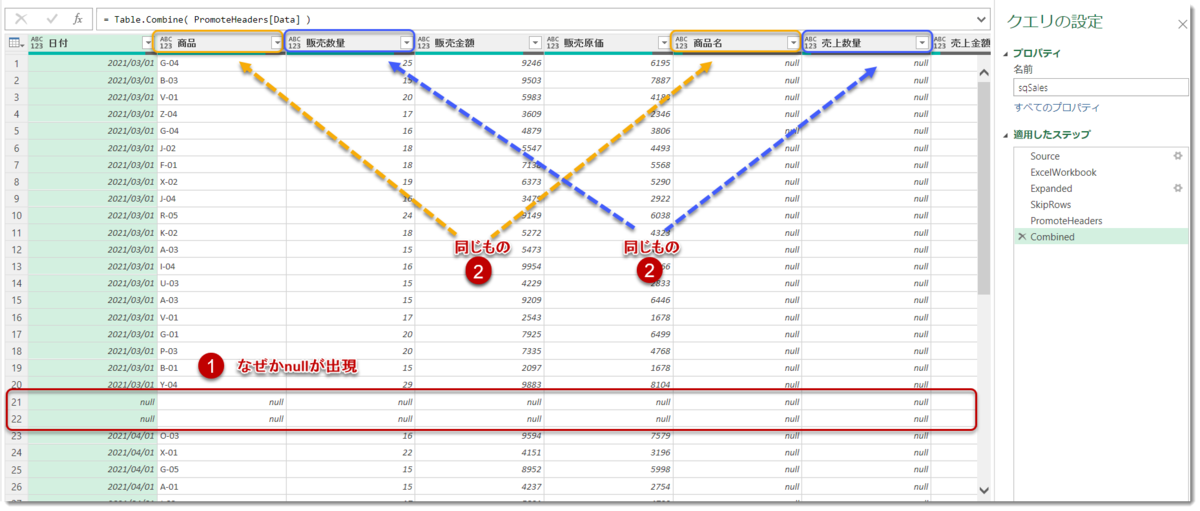
①については実はTable.Skipは1行目からnullの行をSkipしていく処理を行っているため、nullではなくなった瞬間(つまり、文字列が入っているセルを特定した瞬間)、Skipが終わることになっています。そのため、データの一番下にnullがあった場合、①の通り、そのまま結合された状態となって出現してしまうのです。これについては結合してからでないと判明しない場合(=今回の場合)があり、別途対処してあげる必要があります。
一方、②についてはdummy_202203_new_header.xlsx(パターンC)のヘッダー名がパターンAとBと違うことが原因ですが、Table.Combineが[Data]列にある展開前のTableの列名をダイナミックに過不足なく全て抽出してくれたからこそ、修正が必要であると気づいたわけです。そしてここで
パターンA・B vs パターンCの列名統一
という調整が必要となってきます。
長くなってしまうので、今回はここまでにしておきます。次回は①と②の解決法について紹介していきます。①は非常に簡単に解決できますが、②はヘルパークエリ*1を必要とし、Excelのワークシートにテーブルを新規作成しない方法等、もう少し高度なことを見ていきます。
*1:メインで使うクエリをヘルプするためのクエリで、テーブルやリスト等のことを指す