前回、前々回の記事に続き、今回はTable.FirstNで列をキープする方法と列名の正規化(列名を統一して、データを正しく結合できるようにする)を中心に見ていきたいと思います。この記事が初めてという方はぜひ下記①と②を読んでおくことをお勧めします。
サンプルファイル(フォルダパスの修正方法は下記第1回をご参照)
データの一番下にあるnullを削除
前回はすべてのファイルを結合することに成功したものの、下図の①通り、nullが出現してしまう事態となりました。この原因は各ファイルのデータの一番下にnull値が存在していたためであり、Table.Skipの兄弟分であるTable.FirstN関数を使用すること簡単に取り除くことができます。
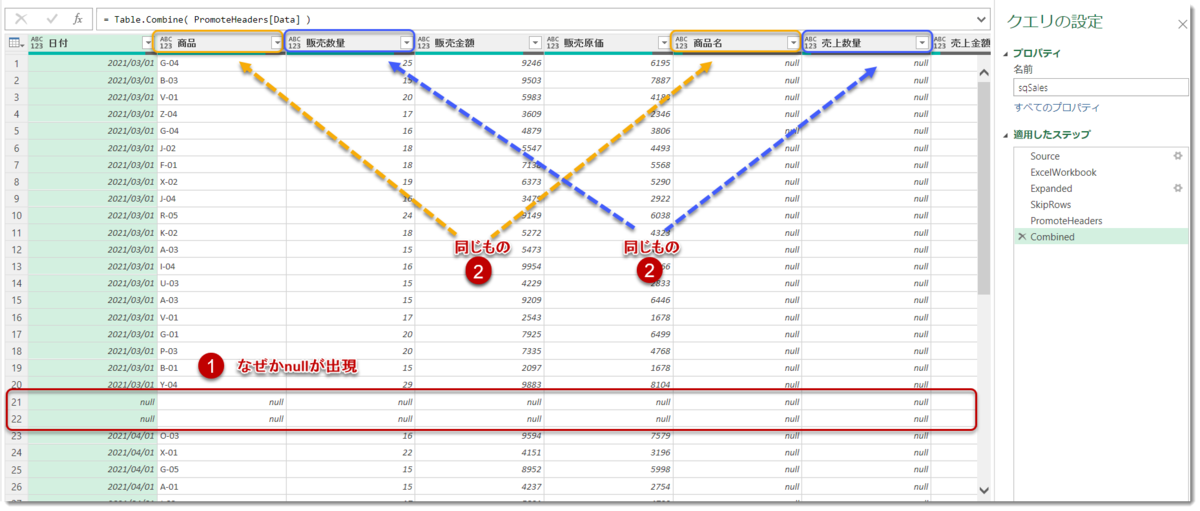
Table.Skipは上からN行を削除(Skip)することで不要な行を減らす関数でしたが、Table.FirstNはその名の通り、上からN行だけをキープする関数です。例えば、上から5行目だけを残したい場合、UI操作で以下のように行います。


Table.Skipと同じく、
= Table.FirstN(前ステップ名, each [列名] <> null)
といったように条件分岐させて行を残すこともできます。今回の例では、Table.Combine(下図:適用したステップ「Combined」)を使用する前にこれを行う必要があるため、SkipRowsとPromoteHeadersというステップの間にTable.FirstNを挿入します。

以下そのやり方です。

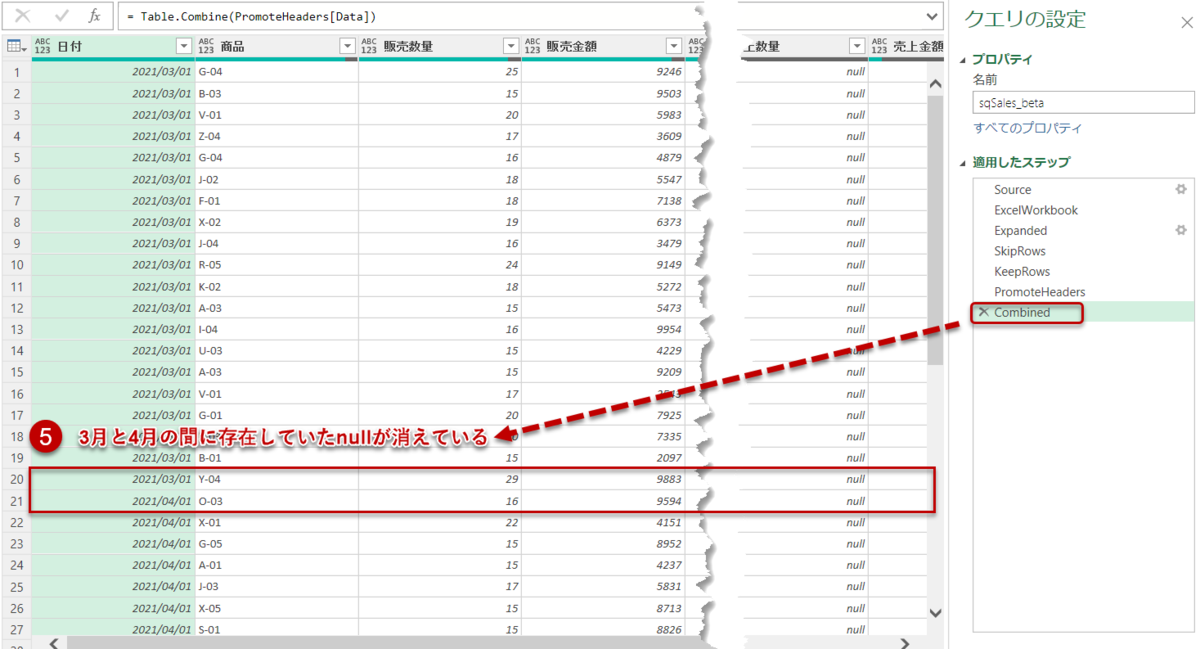
うまくいけば、2021/3/1と2021/4/1の間に存在していたnullが消えているはずです。今回挿入した式は下記の通りですが、同じくTable.TransformColumnsを使用しており、Table.Skipと組み合わせて使った場合(最初のN行をダイナミックに除外)とほぼ同じ書き方となっています。
= Table.TransformColumns(SkipRows, {"Data", each Table.FirstN(_, each _[Column1] <> null)})
この式の意味は、
[Data]列の各行(セル)にあるTable内のデータに対して、[Column1]列にてnullが出現しない限り、行をキープする
になります。Table.Skipの時(前回記事の説明参照)に[Column3]を使用したのはnullが一番上の行からヘッダーまで存在する確率が最も高いと判断したためでしたが、この処理が終わった(適用したステップがSkipRowsとなった)ことにより、直後に挿入されたこの数式では1行目が全てヘッダー列となっています。よって、[Column1]を指定しても[Column3]を指定しても結果は同じになります。
ただし、ここであえて[Column1]を指定したのは理由があり、それは[Column3]が数値列(販売数量)であり、販売数量がnull(文字列ではない空白)となっていた場合、一番下までデータが抽出されなくなってしまうリスクを避けるためです。[Column1]は日付という列になりますので、基本的にこの列でnullが発生することはない、と判断したのも理由の1つです。
これにて、列名を統一するという課題以外はクリアできましたが、もう一度「適用したステップ」を見ると、下記のように2つのクエリをネストさせて1つのクエリにすることも可能です。
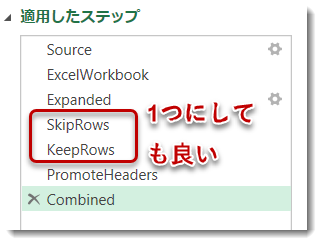
すなわち、
= Table.TransformColumns(Expanded, {"Data", each Table.Skip(_, each _[Column3] = null)})
= Table.TransformColumns(SkipRows, {"Data", each Table.FirstN(_, each _[Column1] <> null)})
を
= Table.TransformColumns(Expanded,
{"Data", each
Table.FirstN(
Table.Skip(_, each _[Column3] = null),
each [Column1] <> null)
}
)
に変更するのです。最初にTable.Skipが機能し、その後データの最後尾にあるnullを除外するためTable.FirstNを使う。eachステートメントが多く出現するため、構文エラーが発生しやすいのですが、2ステップを1ステップにすることができます。ここはもはや好みの問題になりますので、どちらが正しいというのはありません。ちなみに、ステップ数が1つでも2つでも、クエリ自体の抽出パフォーマンスは変わりません。
列名の統一
header_original: 全ての列名を抽出
最後に最もやっかいな問題として残るのが、Table.Combineでうまくデータを過不足なく結合できたのは良いものの、列名が微妙に違っていた場合です。本来であれば、同じ列として、データが入っていなければいけないのに、列名が少し違っただけでPower Queryは違う列と判定し、どちらのデータにもnullが出現してしまいます。以下2つの修正方法がありますが、今回は後者を紹介したいと思います。
- 同じ属性の列が2つ出現した場合、1つ(a)を正(Should-be)として、もう1つ(b)の列に入っているデータをaの列(null値しかないセル)に入れていく。Table.ReplaceValueという関数を使用してnullをbの列にある値で置換し、最後にbの列を削除する
- Table.Combineを使用する前に、列名を全てShould-beの列名に名寄せ(統一)してから結合する
1については別途紹介しますが、これを使用しない理由は主に以下2つ。
- 名寄せが必要な列が複数ある場合、何度もTable.ReplaceValueを使用する必要が生じ、実運用に耐えられない可能性が高い
- Table.ReplaceValueを使うと、クエリのパフォーマンスが遅くなる可能性がある
ということで、2について紹介していきますが、まずは各ファイルに存在する列名が何かを特定するため、Table.ColumneNamesという関数を使用して、列名を抽出します。これをやる前、まずはこれまでにやってきたsqSalesクエリのおさらいをしておきます。
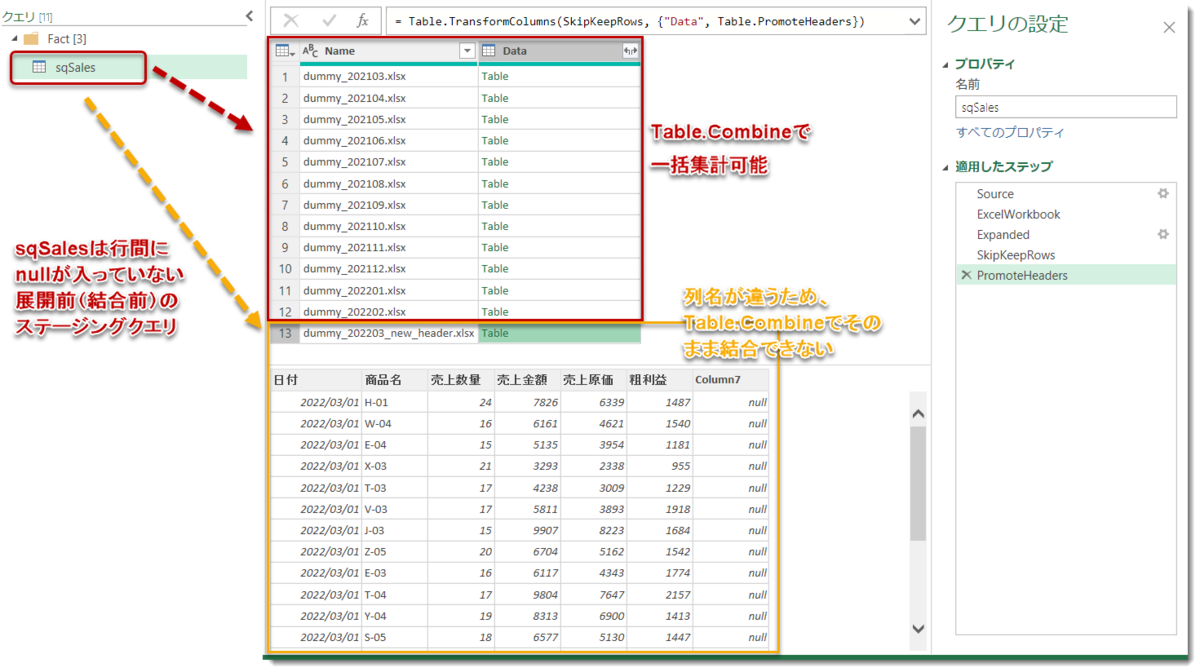
上図の通り、sqSalesは
- 全てのファイルでヘッダーが昇格済み
- Table.Combineで[Data]列を結合できるが、そのまま結合すると[商品]と[商品名]、[販売○○]と[売上○○]がそれぞれ違う列同士で抽出されてしまう
- 粗利益やColumn7といった不要な列まで含まれた状態で結合される
等の特徴があります。列名を統一させるためにはまず、
各ファイルの列名がどのようになっているかを知る
ことからスタートする必要があります。そこで、新たに以下のクエリを作ります。

上記詳細エディタのアウトプットが下図となりますが、すべてのファイルにおけるその時点の列名がすべて抽出されるようになっています。

ここでのポイントは以下の通り。
Table.ColumnNames(テーブル)を使うと、そのテーブル内の列名がリストとして抽出されるようになります。
= Table.AddColumn(Source, "HeaderName", each Table.ColumnNames([Data]))
上の式により、列(HeaderName)が追加され、各ファイルのTable内にある列名が抽出されました。

上の12ファイルは列名が全て同じになっています。

一方で、最後のファイルだけはヘッダー名が先の12ファイルと異なることが分かります。ここで、このHeaderNameという列にある全てのListを全て結合します。
= List.Combine(NameList[HeaderName])
List.Combineのカッコ内はリストが入ることになりますので、NameList[HeaderName]というリスト(=[HeaderName]列をドリルダウンしたもの)が入ることで、リスト同士を結合することができました。
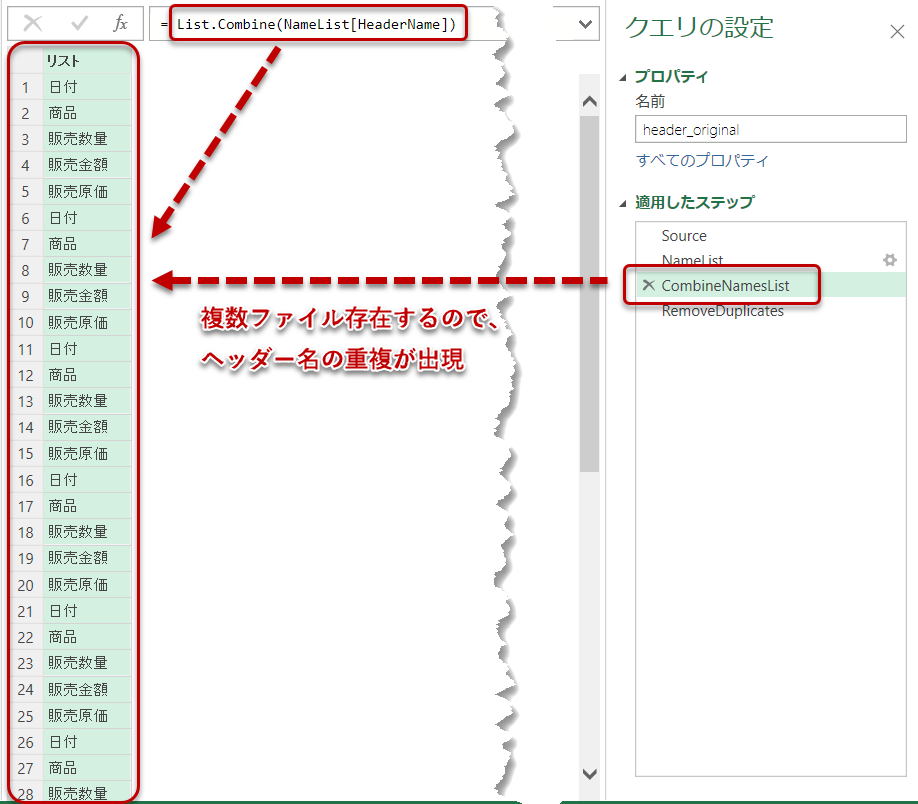
結合した結果は上図の通りですが、List.Distinctという式を使って、この生成されたリスト内から重複を削除していきます。
= List.Distinct(CombineNamesList)

これにより、5列だと思われていたヘッダー名が実は他にも多く存在し、実は11個の異なる名前で存在していたことが分かったわけです。なお、ListはTableのように列名を持っておらず、Listの中には数字やテキストのほか、ListやRecord等も格納可能となっています。
今回の例では各セルにListが入っており、NameList[HeaderName]もListであることから、リストのリストという状態で結合→重複削除というプロセスを経ています。リストは1つのリストによって表現されるため、例えば[商品名]というキーワードがどのファイルから抽出されたかをここで判定することはできません。どうしても知りたい場合、NameListというステップに戻ってセル内をクリックしながら見ていくしかありません。
ここまでの作業により、header_originalというリストを作ることができました。
※追記
上記
= List.Combine(NameList[HeaderName])から
= List.Distinct(CombineNamesList)
の部分を以下List.Unionだけで実現できます。
= List.Union(CombineNamesList)
この場合、List.Distinctが必要なくなりますので、コードがシンプルになります。
header_after: ヘッダー名変更用リスト
header_originalが元々の列名を見るためのヘルパークエリである一方、header_afterという名前のヘルパークエリも作る必要があります。これを作る理由は、header_originalの列名をheader_afterに名前を変更するためです。名前の変更はTable.RenameColumnsという関数を使用しますが、後ほど解説します。
ここで詳細エディタを立ち上げてクエリを見ると、非常にシンプルなものになっていることが分かります。
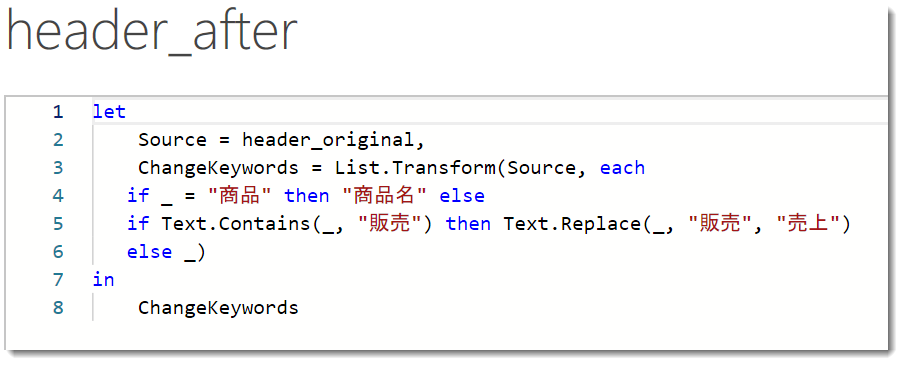
結果ですが、originalに対して、afterは商品→商品名、販売数量→売上数量、販売金額→売上金額、販売原価→売上原価へとそれぞれ変更されています。
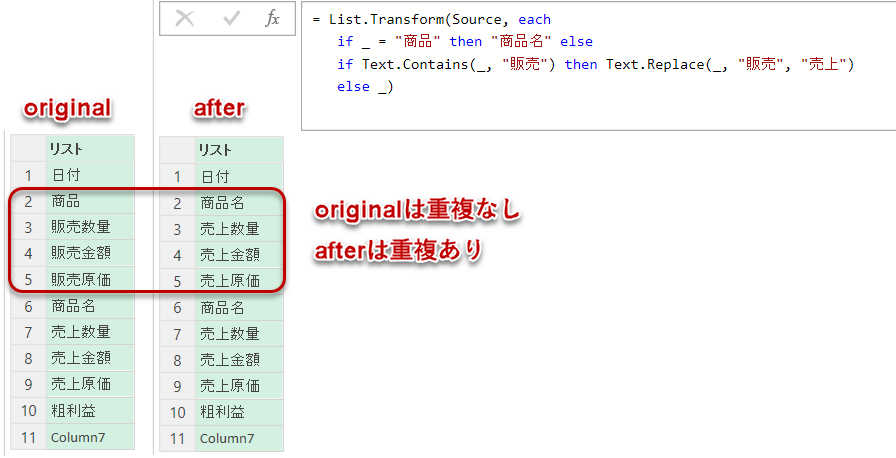
構文を見ると、まずSource = header_originalとなっているのが分かります。これは、header_originalというヘルパークエリを参照し、新しいheader_afterというヘルパークエリを作るための構文です。やり方は非常にシンプルで、header_originalを右クリックし、参照をクリックするだけ。
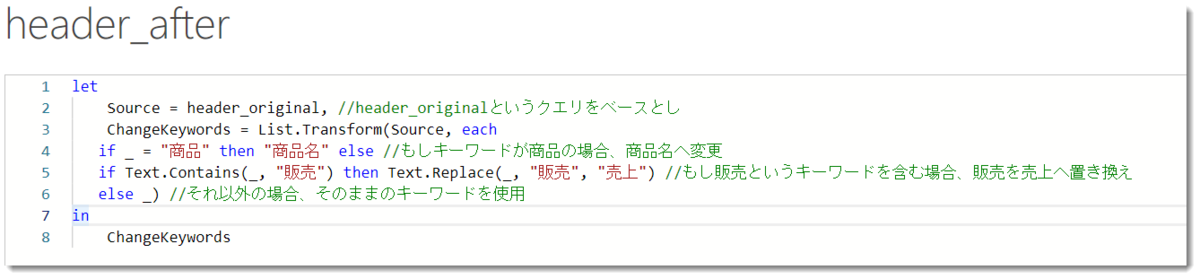
この後、以下の式を数式バーに入力します。
= List.Transform(Source, each
if _ = "商品" then "商品名" else
if Text.Contains(_, "販売") then Text.Replace(_, "販売", "売上") else _)
Table.TransformColumnsは前回の記事にて紹介しましたが、Tableというキーワードから分かる通り、テーブルの列に対して処理を行うものです。一方、今回のクエリはListとなっていますが、使用する関数はList.Transformとなります。Table.TransformColumnsである程度、その仕組みについて理解していると思いますので、上記M式を読み解くのはそれほど難しいものではないはずです。
List.TransformはSource、つまり、header_originalを参照した結果に対して、それぞれ処理を行っていきます(each = それぞれ)。_(アンダースコアはそれぞれのキーワード)で、"商品"というキーワードとイコールであれば、"商品名"へ名称を変更し、それ以外にもし"販売”というキーワードが含まれていた場合、”販売を売上へ置換”し、それ以外はそのままのキーワードを使用する
というのが解釈ですが、説明が長くなり、かつどの部分に対する説明なのか分かりづらいので、通常このように説明が必要なケースは下図の通り、//を付けてコメントとしてソースコードに残しておきます。
これで、header_afterが出来上がったので、あとはTable.TransformColumnsとTable.RenameColumnsを組み合わせてTable.Combineを行う前に、Table内で列名を変更してあげるだけです。列名の変更はTable.RenameColumnsを使いますが、その挙動について確認してみます。
renamed_slow: originalとafterをリスト化
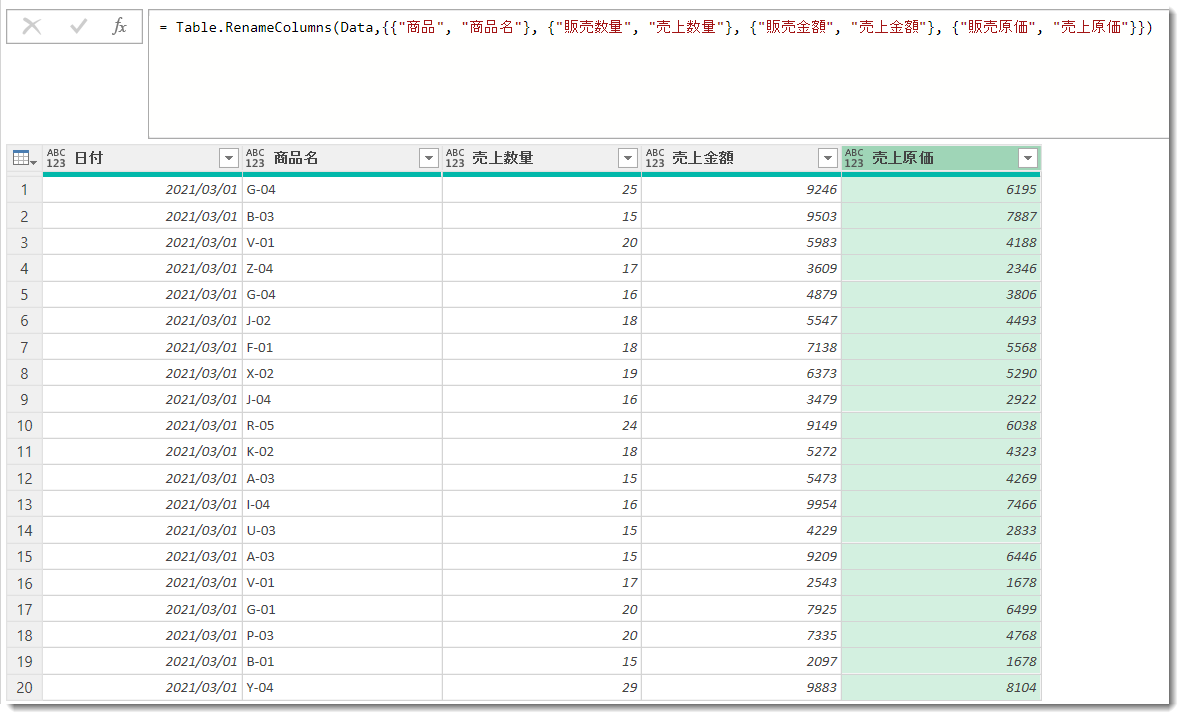
Power Queryで列名を変更する場合、数式バーでは例えば以下のような構文になります。
= Table.RenameColumns(Data,
{
{"商品", "商品名"},
{"販売数量", "売上数量"},
{"販売金額", "売上金額"},
{"販売原価", "売上原価"}
})
{}はListを意味しており、例えば={1..10}と入力すると、1~10までのリストが生成されます。上式は{}の中にさらに{}が入った状態ですので、”リストのリスト”ということになります。{"商品", "商品名"}を見ていくと分かりますが、
{"Before", "After"}
という構文になっています。Table.RenameColumnsですので、
BeforeをAfterの名称にRenameする
という処理が行われます。
ここで、これと同じスタイルでheader_originalとheader_afterを組み合わせてみます。”リストのリスト”ですので、新しい空白のクエリを作成し、以下のように記述します。
= {header_ogrinal, header_after}
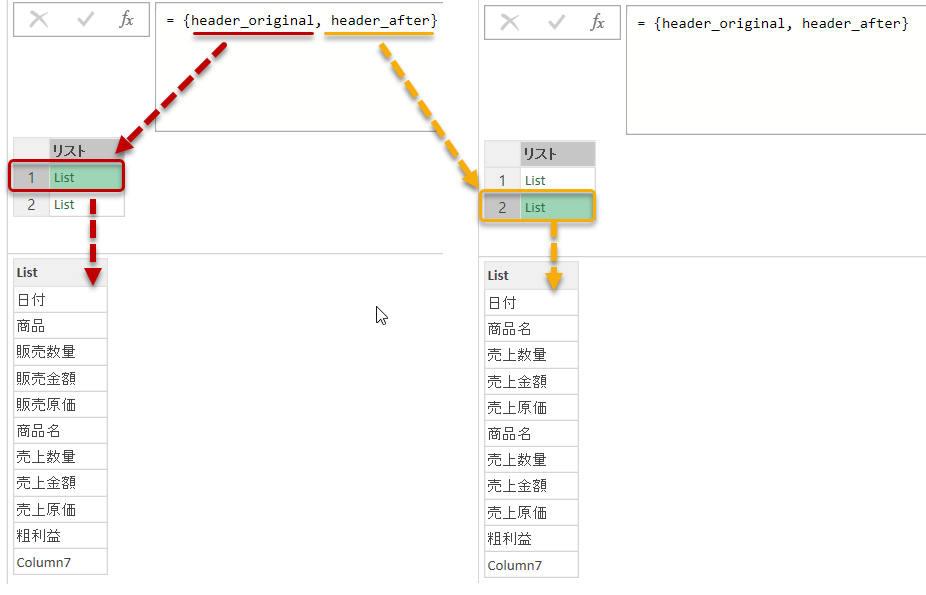
すると、上記のように、リストの中にそれぞれのリストが格納された状態となりました。しかし、このリストは書き換えると
{
{ "日付", "商品", "販売数量", "販売金額", "販売原価", "商品名", "売上数量", "売上金額", "売上原価", "粗利益", "Column7"},
{ "日付", "商品名", "売上数量", "売上金額", "売上原価", "商品名", "売上数量", "売上金額", "売上原価", "粗利益", "Column7"}
}
というリストになっていますので、Table.RenameColumnsで使用するためにはこれをBeforeとAfterの2つずつのリスト×複数に変更してあげる必要があります。そこで重宝されるのがList.Zipという関数になります。
= List.Zip(Source)
※ Source = { header_original, header_after }
結果的に詳細エディタで結果を見ると、以下の通りになります。
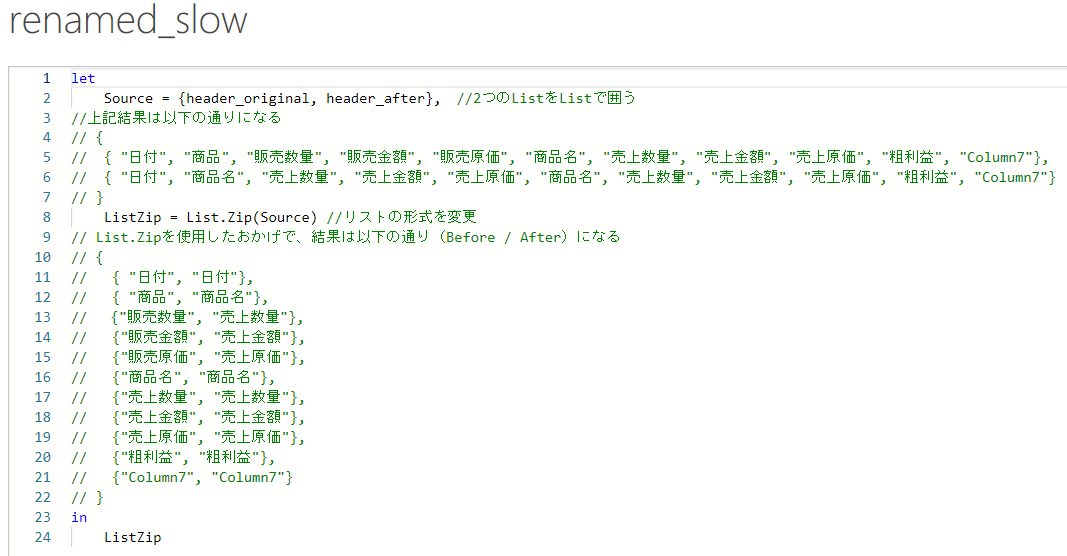
念の為、完成したクエリ(renamed_slow)を見ると、以下のリストが生成されます。
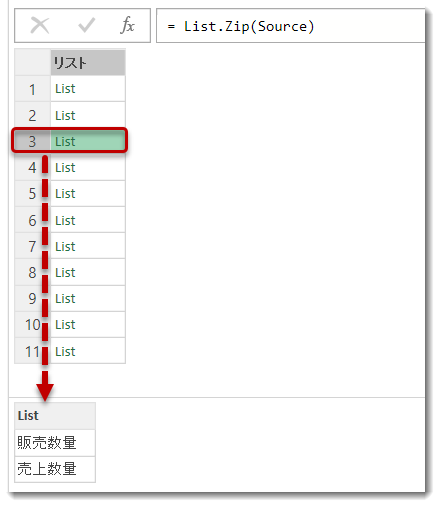
出来上がり
いよいよ終盤です。sqSalesを参照する新たなクエリを作り、以下の関数を入力します。
= Table.TransformColumns(Source, {"Data", each Table.RenameColumns(_, renamed_slow )})
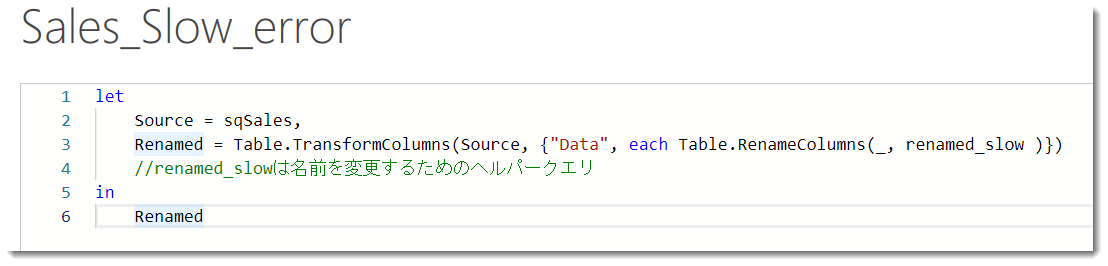
ここでもTable.TransformColumnsを使って、[Data]列の各セル内のTableの中の列名に対する処理(=名前の変更)を行っています。そして結論から言いますと、この書き方ではエラーが発生してしまいます。なぜなら、Table.RenameColumnsを使った場合、そのTableに存在しない列名がheader_originalにあった場合、エラーが発生することになるためです(下図参照)。この書き方が通用するのは、{header_original, header_after}のうち、header_originalにおいて、1つでも不明な列が存在しない場合のみとなります。
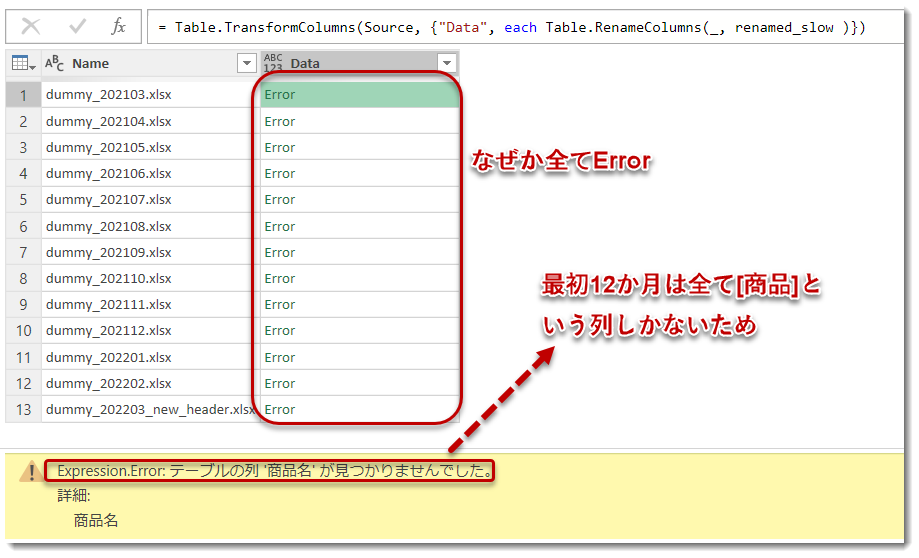
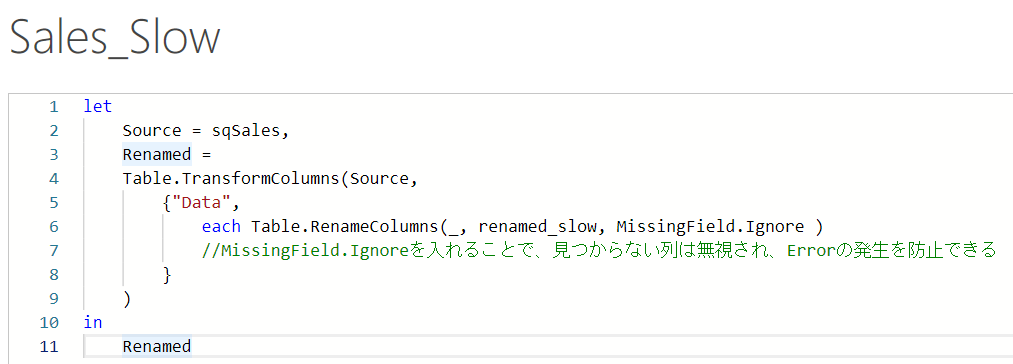
ではどうすればよいか。答えはTable.RenameColumnsの第3のパラメータにMissigField.Ignoreというステートメントを入れればOKです(下図)。このステートメントは不明な列が存在した場合、それは無視する = エラーステートメントを返さない、処理を行ってくれますので、非常に使い勝手が良いです。
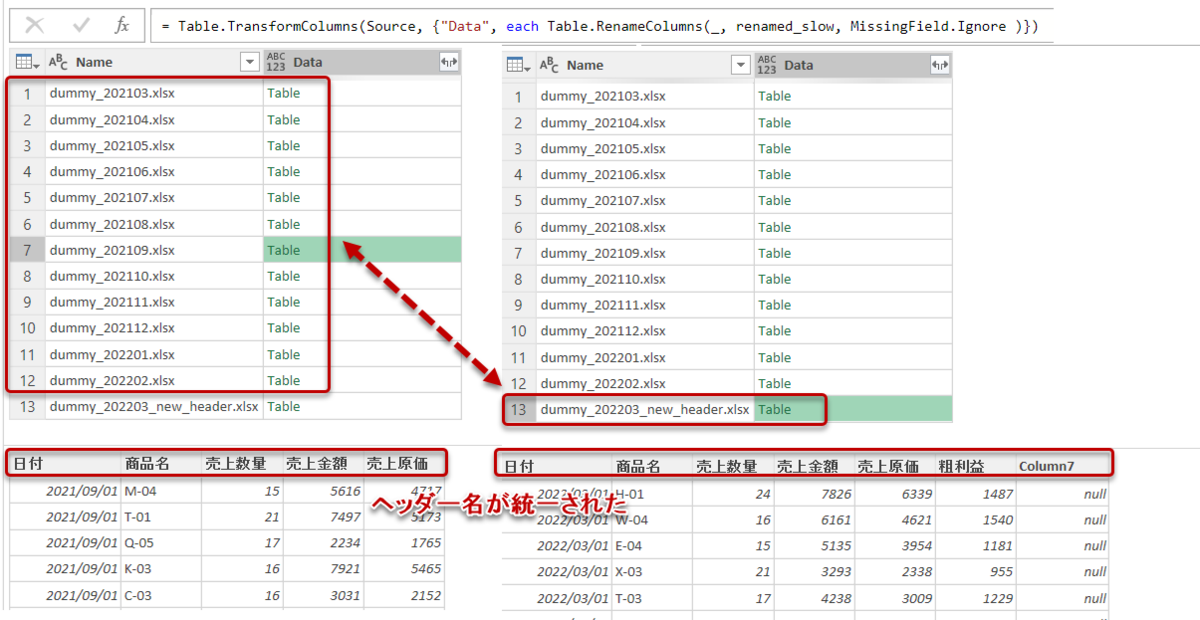
これでようやくTable.Combineを使って、全てのファイルを結合できるようになります。下図はこれを実施したクエリ(Sales_Slow)ですが、[粗利益]と[Column7]が出現していること以外、全ての列が正しく結合できていることが分かります。
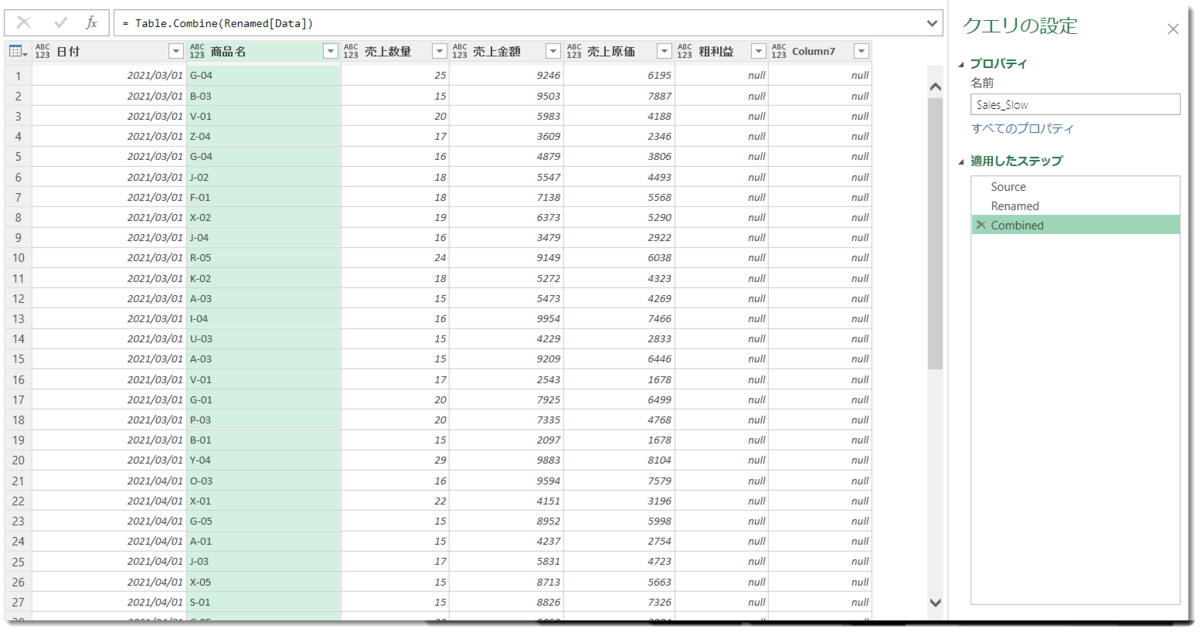
右の2つの列は書式が変更された際、副産物として出現したものですが、最初の12個のファイルではこの2つの列は登場していないため、全ての行にnullが入った状態となります。そしてこの2つの列は余計な列ですので、通常データを展開する前 or 展開した後に削除したほうがよさそうです。
次回(最終回)について
ここまで話をしてきて、不思議に思う方もいると思います。すなわち、クエリ名に意図的にslowというキーワードを付けていることです。これは何も不思議なことではないのですが、実際に上記クエリをご自身で作ってみれば分かりますが、データ量が非常に小さいデモ用データであっても、Table.RenameColumnsのステップ、あるいはそのステップを含むクエリが遅いのです。
これは、数式バーに上記の数式を入力した後、クエリが変更される際、Excelの右下に読み込み情報が表示され、結果が返ってくる前に数秒もかかっていることから判断できます。
![]()
ここにきて、最後の話はクエリのパフォーマンス問題についてとなります。また、列名を削除する場合、Table.RemoveColumnsではなく、Table.SelectColumnsを使ったほうが良い話もしていきます。