前回の小ネタ集はPower Queryのショートカットについて紹介しましたが、今回はM関数の中で、非常に便利なものをいくつか紹介します。
最初・最後・真ん中のN列だけを選択する
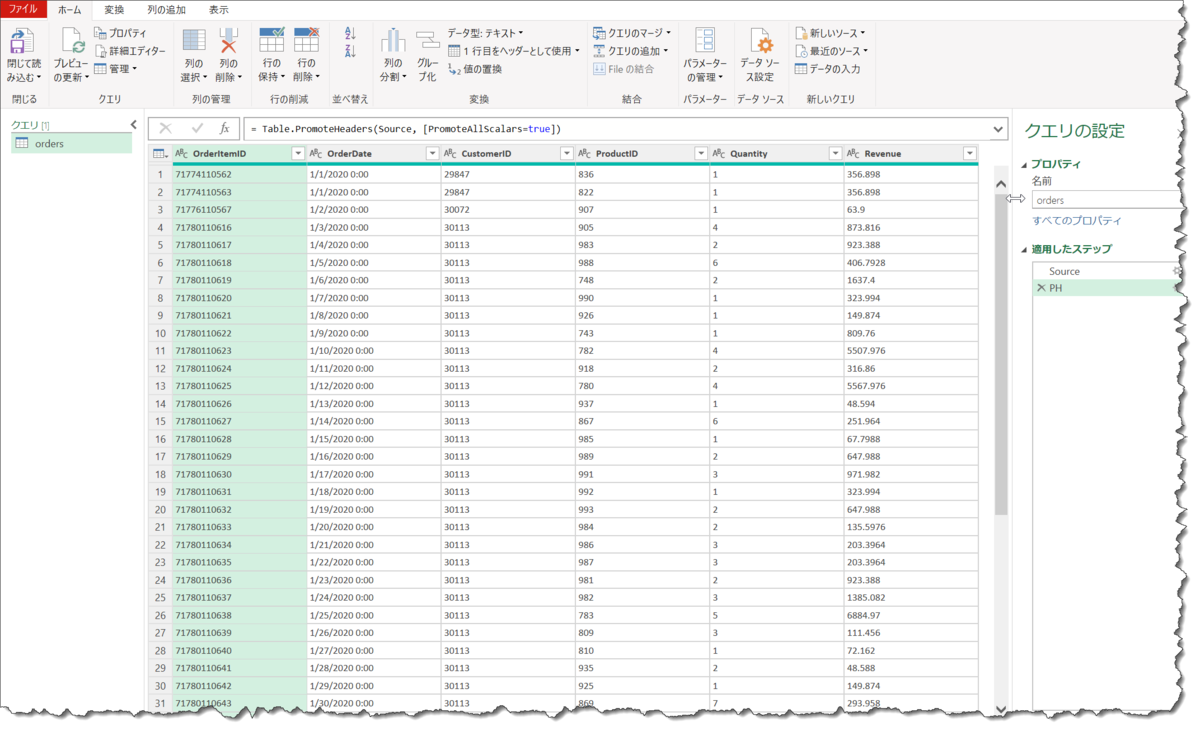
下記のようなクエリがあるとします。
let
Source =
Csv.Document(
Web.Contents(
"https://github.com/MicrosoftLearning/DP-900T00A-Azure-Data-Fundamentals/raw/master/power-bi/orders.csv"),
[Delimiter=",", Columns=6, Encoding=65001, QuoteStyle=QuoteStyle.None]),
PH = Table.PromoteHeaders(Source, [PromoteAllScalars=true])
in
PH
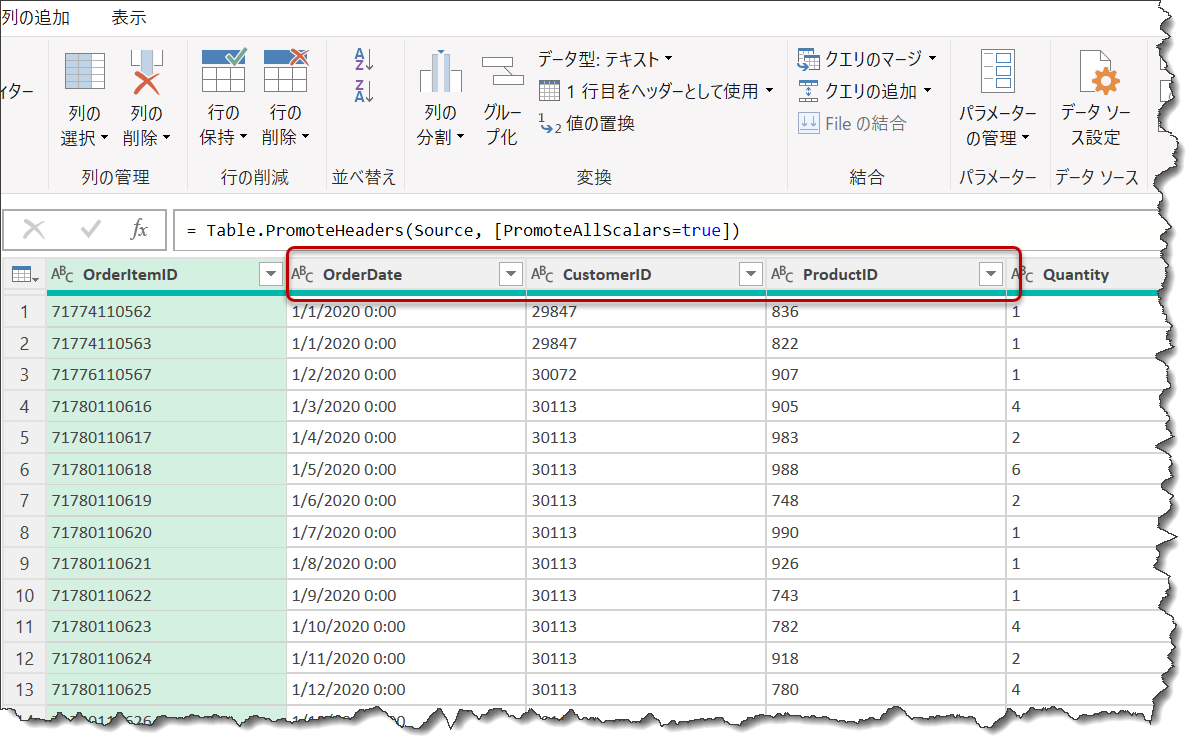
こちらの結果で、最初の4列だけを選択したい場合、通常であれば、以下の赤字のようになります。
let
Source =
Csv.Document(
Web.Contents(
"https://github.com/MicrosoftLearning/DP-900T00A-Azure-Data-Fundamentals/raw/master/power-bi/orders.csv"),
[Delimiter=",", Columns=6, Encoding=65001, QuoteStyle=QuoteStyle.None]),
PH = Table.PromoteHeaders(Source, [PromoteAllScalars=true]),
#"Removed Other Columns" = Table.SelectColumns(PH,{"OrderItemID", "OrderDate", "CustomerID", "ProductID"})
in
#"Removed Other Columns"
この場合、列名が変わってしまった時にエラーが発生してしまいます。そこで、列名に影響されることなく、自動的に最初の4つの列を選択するMクエリを作ります。
let
Source =
Csv.Document(
Web.Contents(
"https://github.com/MicrosoftLearning/DP-900T00A-Azure-Data-Fundamentals/raw/master/power-bi/orders.csv"),
[Delimiter=",", Columns=6, Encoding=65001, QuoteStyle=QuoteStyle.None]),
PH = Table.PromoteHeaders(Source, [PromoteAllScalars=true]),
SelectColumns = Table.SelectColumns(PH, List.FirstN(Table.ColumnNames(PH), 4))
in
SelectColumns
SelectColumns = Table.SelectColumns(PH, List.FirstN(Table.ColumnNames(PH), 4))
非常にシンプルなコードですが、List.FirstNとTable.ColumnNamesを組み合わせることで、Table.ColumnNamesによって生成された列名のリストに対して、最初のN個(この場合、4つめ)の列を選択(Table.SelectColumns)を行うことになります。
同様に、最後の4列を選択したい場合、List.FirstNをList.LastNに置き換えるだけです。
SelectColumns = Table.SelectColumns(PH, List.LastN(Table.ColumnNames(PH), 4))
一方、2~4番目の列を選択したい場合、どうすれば良いのでしょうか?少し式が難しくなりますが、以下で対応できます。なお、選択したい列は以下の通りです。
SelectColumns =
Table.SelectColumns(PH, List.Transform({2..4}, each Table.ColumnNames(PH){_ -1}))
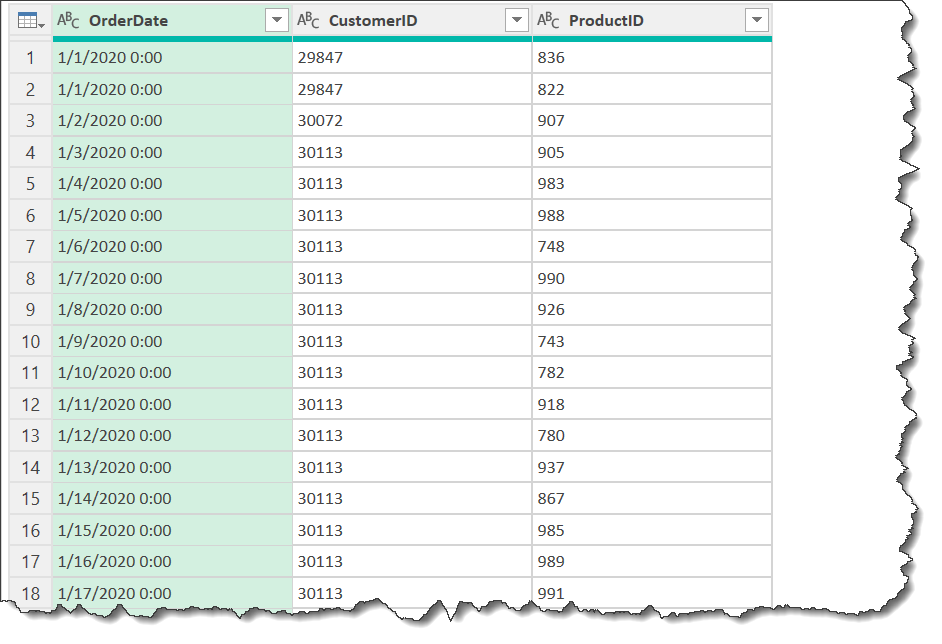
無事2~4列目までの列を取得できました。
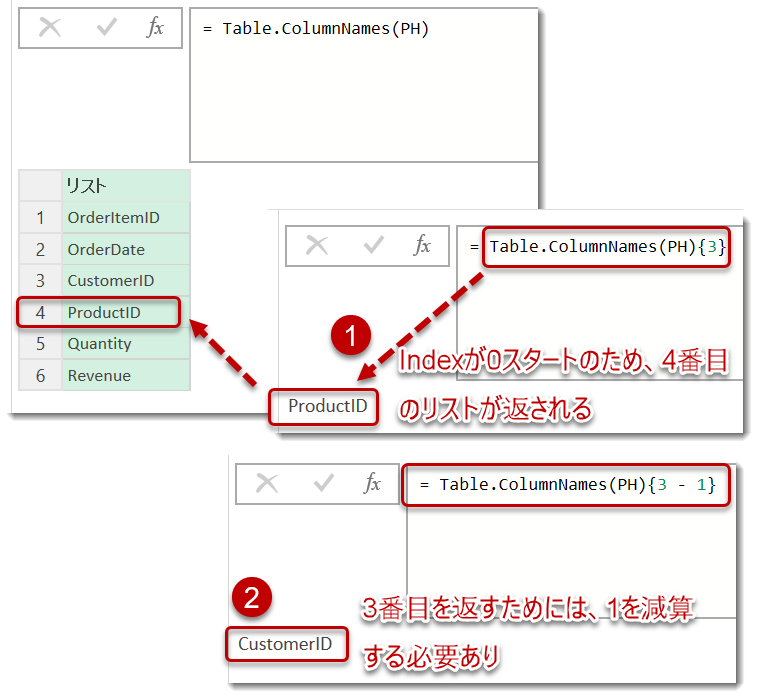
Table.ColumnNamesで列のリストを生成し、その中で3番目のリストを取得するため、相対ポジションで対象リストを取得しています。List.Transformはこのリスト内の2~4番({2..4})目までのリストに対して処理を行う(=選択)を行っていることになります。ちなみに、こちらのやり方がしっくりこない方は、以下の書き方でも同じことを実現できます。
SelectColumns = Table.SelectColumns(PH, List.Range(Table.ColumnNames(PH), 1, 3))
List.Rangeを用いて、1(=2列名)から右へ3つ分のリストを取得し、同じように列を選択することができます。こちらのほうが圧倒的に分かりやすいので、このようなニーズがある場合、List.Rangeを使ったほうが無難かもしれません(ただし、List.Rangeにおける1は、0スタートIndexであることに留意する必要あり)。
そして、同じ概念を使用すれば、例えば、1、3、5列目だけを選ぶことも可能になります。
SelectColumns =
Table.SelectColumns(PH, List.Transform({1,3,5}, each Table.ColumnNames(PH){_ -1}))
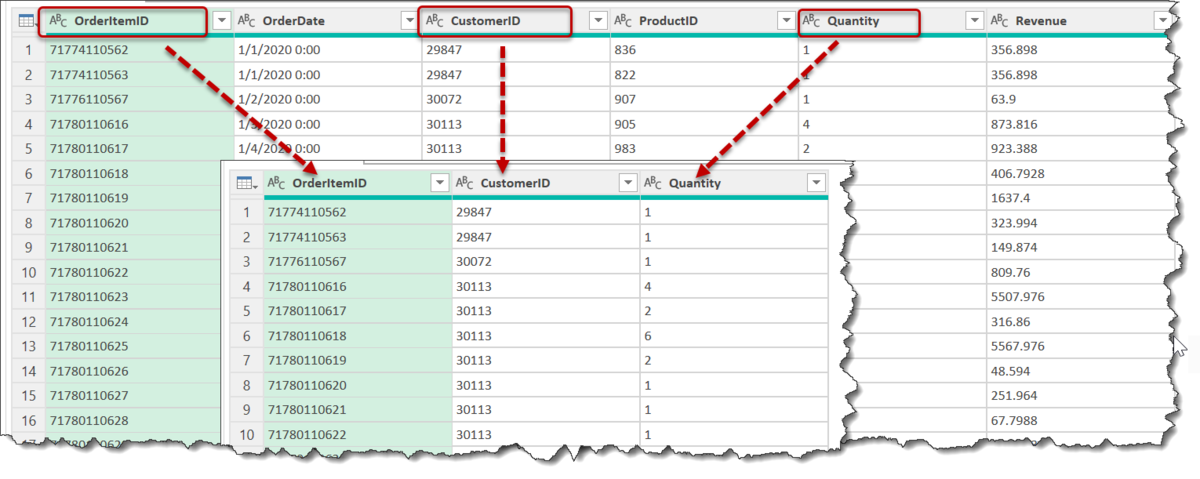
最後の列名を変更
列名を変更する場合もダイナミックに行うことができます。今回の例でいえば、例えば以下のコードになります。
let
Source =
Csv.Document(
Web.Contents(
"https://github.com/MicrosoftLearning/DP-900T00A-Azure-Data-Fundamentals/raw/master/power-bi/orders.csv"),
[Delimiter=",", Columns=6, Encoding=65001, QuoteStyle=QuoteStyle.None]),
PH = Table.PromoteHeaders(Source, [PromoteAllScalars=true]),
Renamed = Table.RenameColumns(PH,{{"Revenue", "SalesAmount"}, {"Quantity", "SalesQuantity"}})
in
Renamed
名前の変更にはTable.RenameColumnsを使用しますが、リストのリストにする必要があります。すなわち、{{"Revenue", "SalesAmount"}, {"Quantity", "SalesQuantity"}}の部分がこれに当たりますが、リストの中にリストが入っており、2番目のリストにはBeforeとAfterの文字列が格納されています。
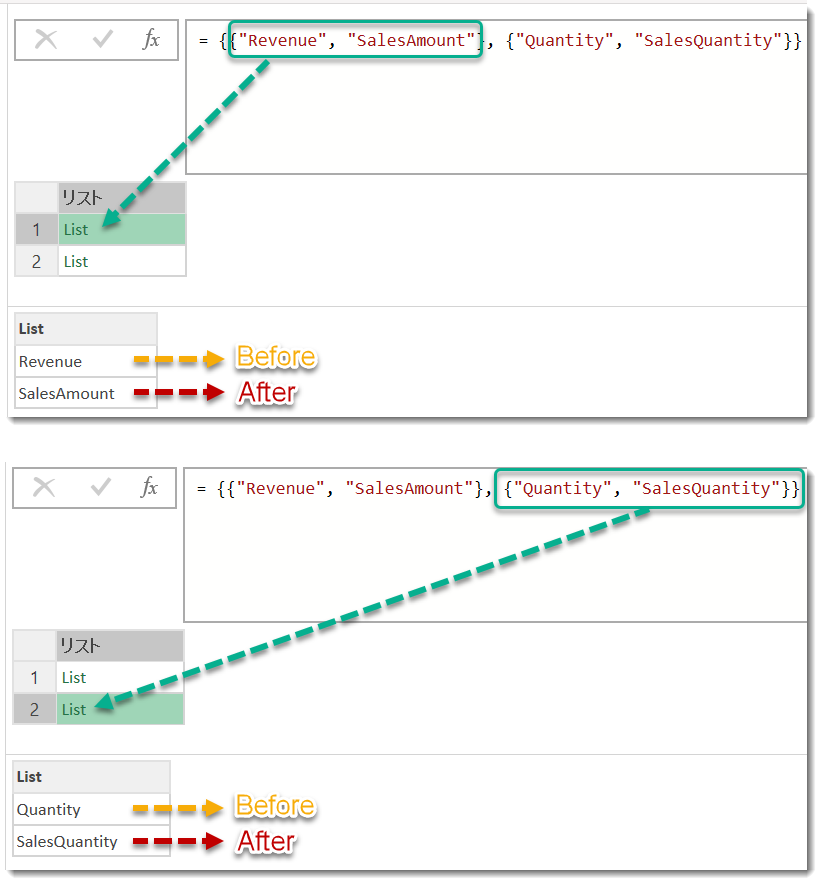
Table.RenameColumnsはこのような構文で列名をリネームしますが、この例では列名をハードコーディング(1つずつ指定)して名前を変更していますので、例えば将来的にBeforeの名前が少し変わったりすると、このステップでエラーが発生してしまいます。
そこでダイナミックに、列の順番が変わらないという前提で最後の2つの列名を変更してみると、以下のような構文になります。
let
Source =
Csv.Document(
Web.Contents(
"https://github.com/MicrosoftLearning/DP-900T00A-Azure-Data-Fundamentals/raw/master/power-bi/orders.csv"),
[Delimiter=",", Columns=6, Encoding=65001, QuoteStyle=QuoteStyle.None]),
PH = Table.PromoteHeaders(Source, [PromoteAllScalars=true]),
Renamed =
Table.RenameColumns(PH,
List.Zip(
{List.LastN(Table.ColumnNames(PH), 2), //最後の2列
{"SalesQuantity", "SalesAmount"}} //リネームしたい名称
)
)
in
Renamed
最後の2つのList.LastN(Table.ColumnNames(PH), 2)と{"SalesQuantity", "SalesAmount"}がポイントとなりますが、前者は上記にて紹介した最後の2列を指定する方法、後者はリネーム後の名称となります。この式をそのまま使った場合、下図の通り、リネームするための条件が整っていません。
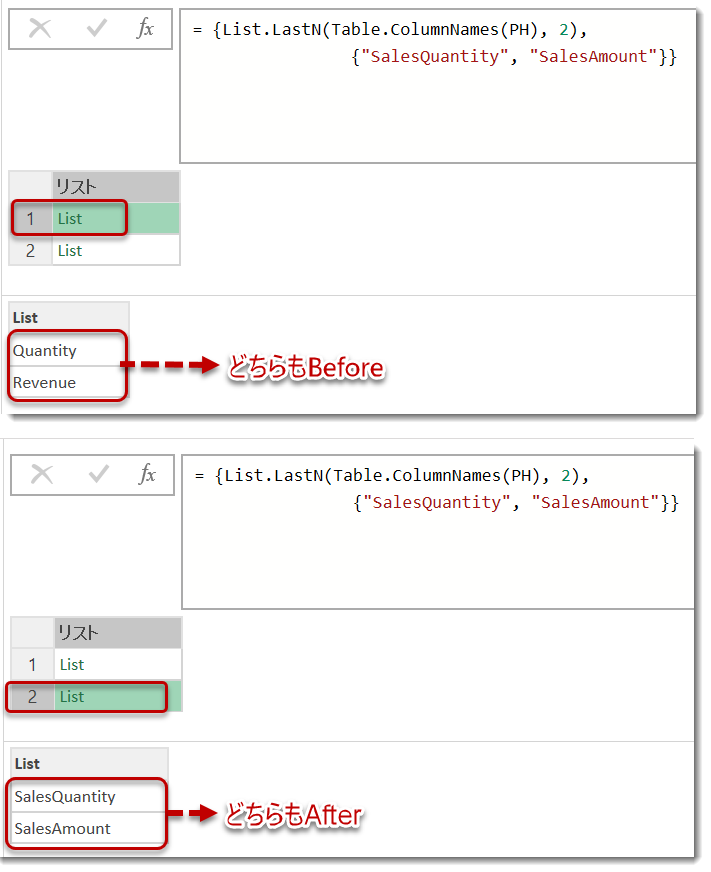
List.Zipはこの状況下にあるリストを入れ替えるための関数であり、こちらの関数で括ってあげれば期待する結果を返す(=オリジナルの列名に関係なく、リネームが可能)ことができます。
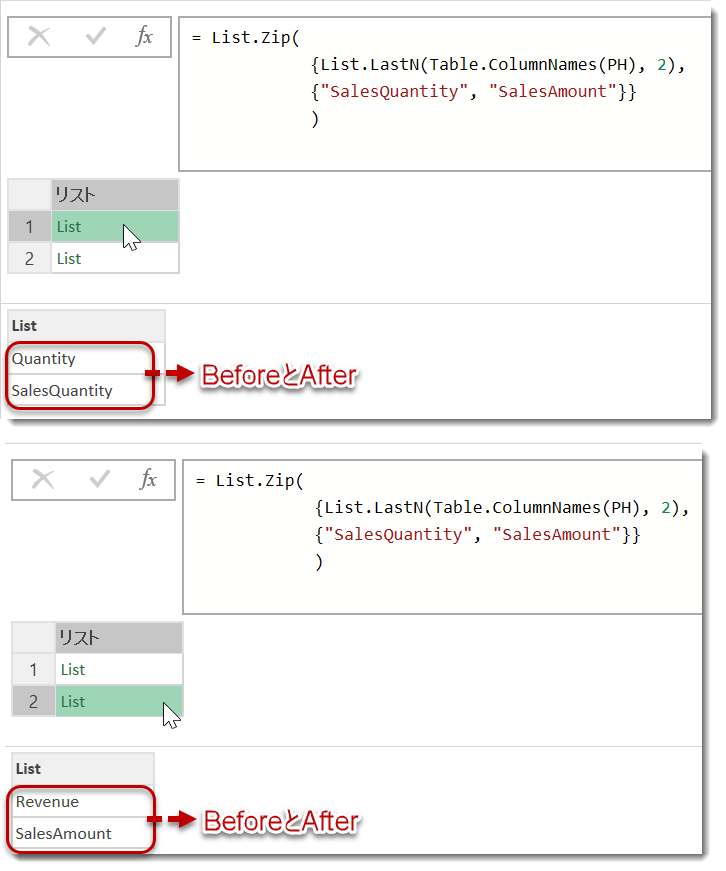
Table + List関数を組み合わせて使う事例は多くあり、UIによる操作ではなく、マニュアルで構文を変更できると一気に自由度が拡大できるかと思います。
A列の条件でB列を追加
最後に紹介するのは、例えばA列(英語)をB列(日本語)で追加する場合のやり方です。具体的な例として、Lookup(Dimension)テーブルに列を追加するのが分かりやすいですが、下図のようになります。
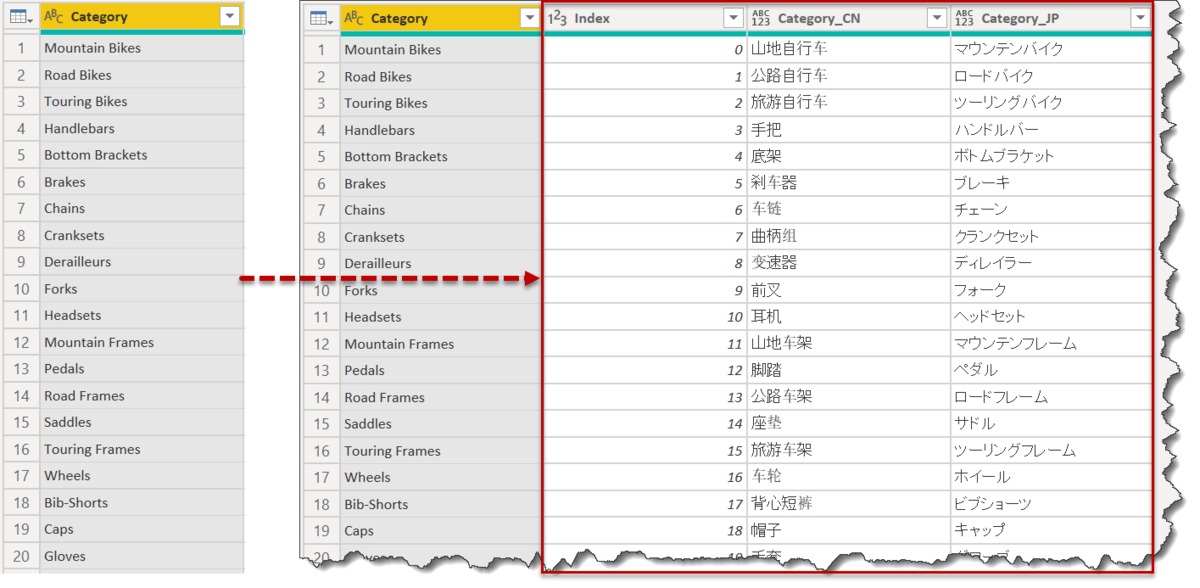
Categoryの横に、Category_CN、Category_JPといった中国語・日本語に翻訳された列を追加したい事例です。この場合、2つの作業が必要となります。
- 翻訳
- 列を横に追加
まず1の翻訳ですが、DeepLやGoogle翻訳といったツールで翻訳していきます。そして、翻訳後の結果をExcel内に張り付けておきます。
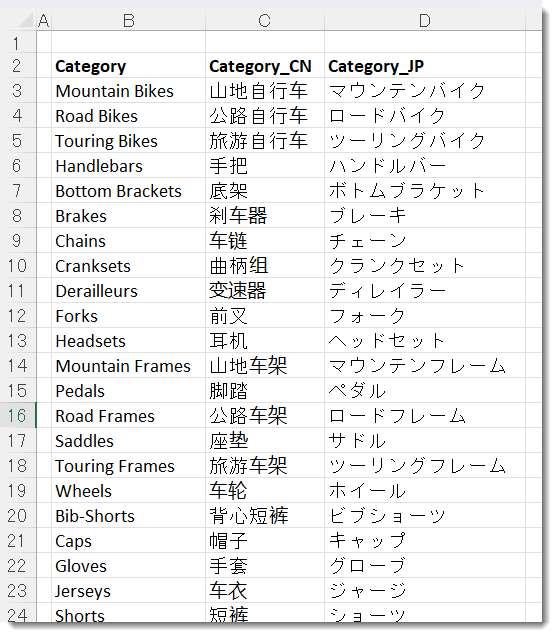
いよいよ本題の2ですが、ここではいくつかのやり方があります。
クエリを作ってマージ
Power BIのクエリエディタを立ち上げ、「データの入力」(下図)で新たにテーブルを作り、元のクエリへマージする方法。この方法は最もわかりやすく、パフォーマンスも良い可能性があります。
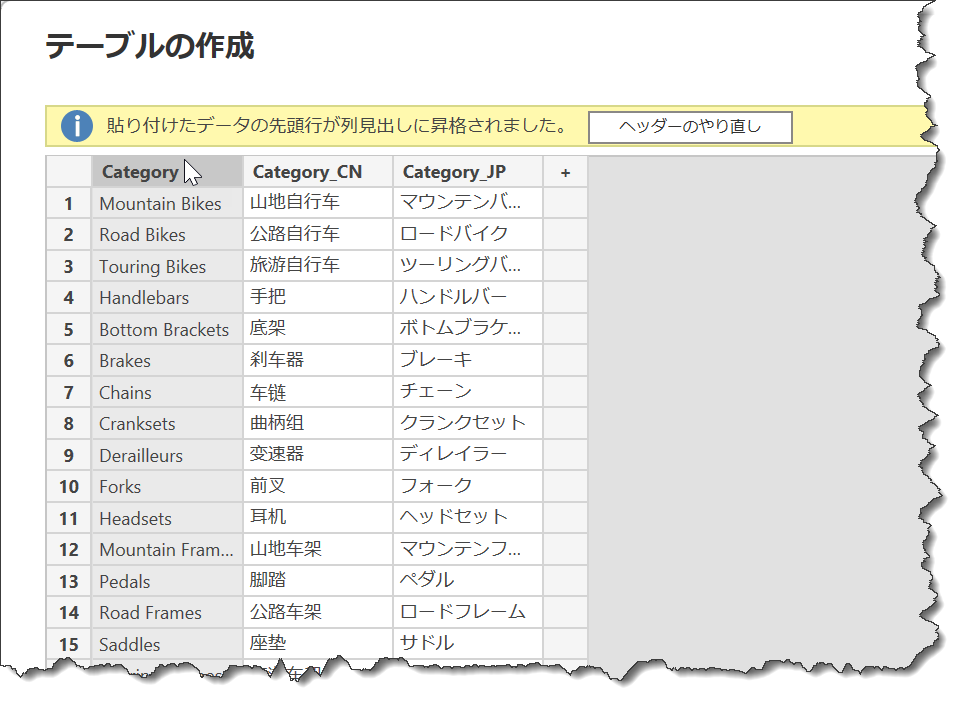
Table.fromColumn / Table.ToColumns使用
let
Source = Table.Distinct(dProduct[[Category]]),
//dProductクエリのCategory列から重複削除
AddIndex = Table.AddIndexColumn(Source, "Index", 0, 1, Int64.Type),
//インデックス列の追加(ソート用)
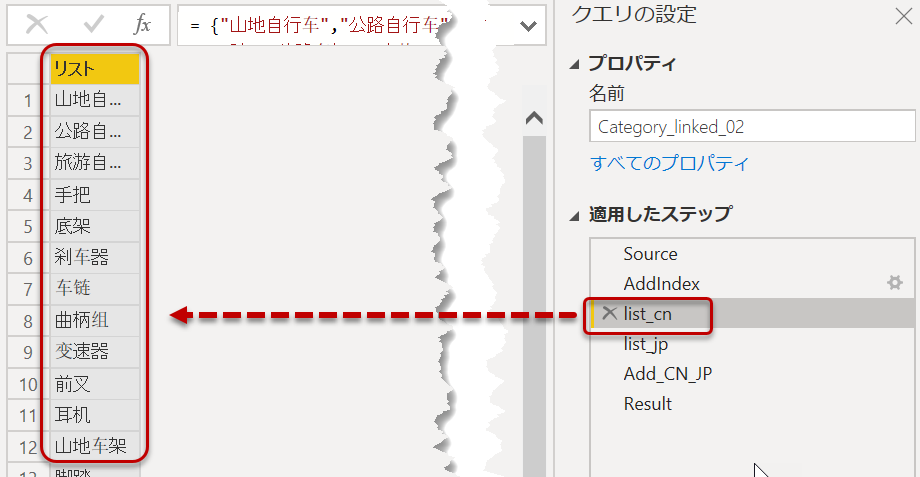
list_cn = {"山地自行车","公路自行车","旅游自行车","手把","底架","刹车器","车链","曲柄组","变速器","前叉","耳机","山地车架","脚踏","公路车架","座垫","旅游车架","车轮","背心短裤","帽子","手套","车衣","短裤","袜子","紧身衣","马甲","自行车架","自行车支架","瓶子和笼子","清洁器","挡泥板","头盔","补水包","车灯","锁具","储物箱","水泵","轮胎和管子"},
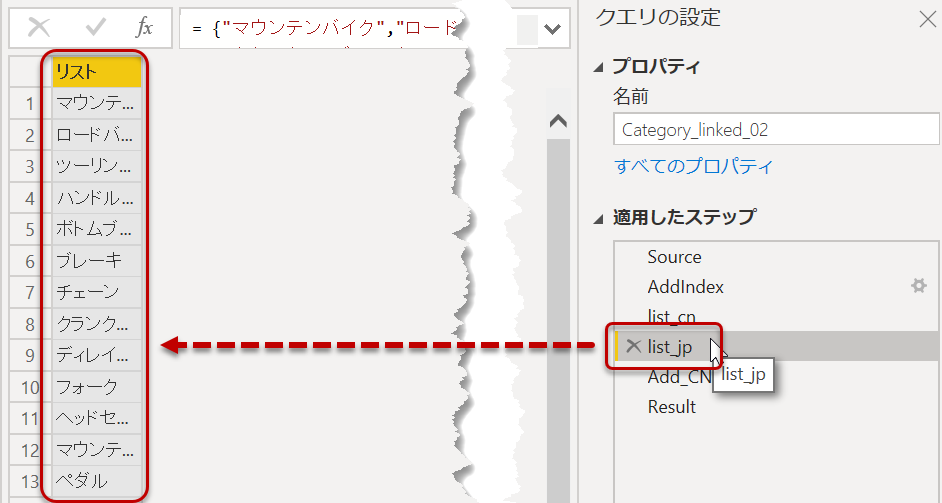
list_jp = {"マウンテンバイク","ロードバイク","ツーリングバイク","ハンドルバー","ボトムブラケット","ブレーキ","チェーン","クランクセット","ディレイラー","フォーク","ヘッドセット","マウンテンフレーム","ペダル","ロードフレーム","サドル","ツーリングフレーム","ホイール","ビブショーツ","キャップ","グローブ","ジャージ","ショーツ","ソックス","タイツ","ベスト","バイクラック","バイクスタンド","ボトル・ケージ","クリーナー","フェンダー","ヘルメット","ハイドレーションパック","ライト","ロック","パニア","ポンプ","タイヤ&チューブ"},
//cn(中国語)とjp(日本語)の翻訳リスト。作り方は下記ARRAYTOTEXTとTRANSPOSE関数を使用
Add_CN_JP = Table.ToColumns(AddIndex) & List.Combine( { {list_cn}, {list_jp} } ),
//AddIndexステップのテーブルをリスト化(Table.ToColumns)し、それとlist_cn、list_jpのリストを合体させる
Result = Table.FromColumns( Add_CN_JP, {"Name", "Sort", "Name_CN", "Name_JP"} )
//Table.FromColumnsより、リストのリストからテーブルを作り、各列名を付ける。
in
Result
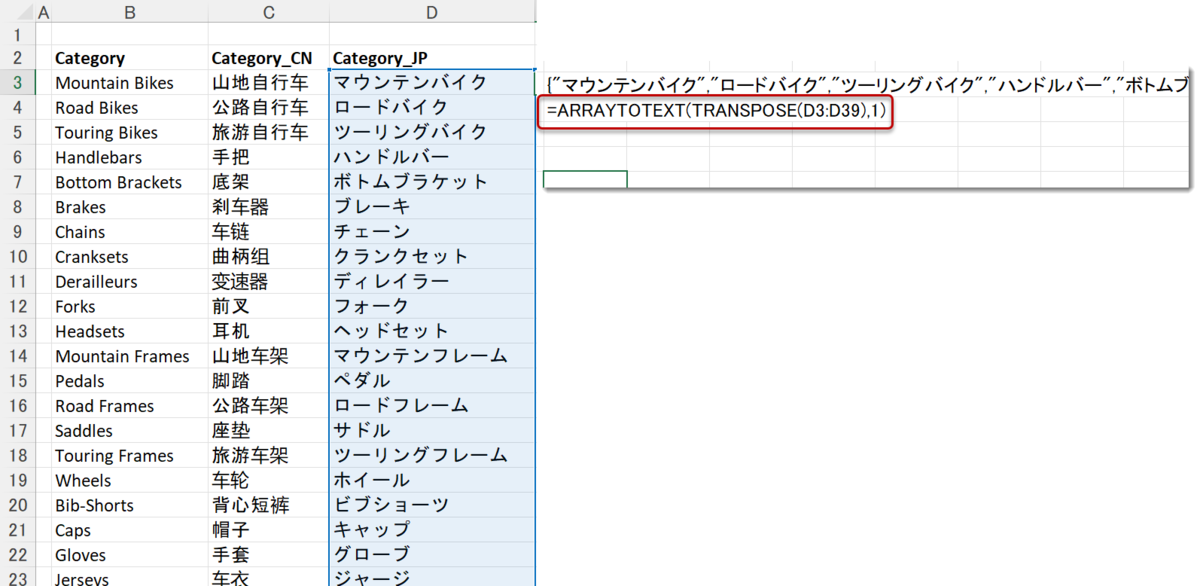
なお、list_cnとlist_jpはそのまま手動で作ろうとすると非常に時間がかかってしまうため、以下のExcel式でリスト化させるとよいでしょう。
=ARRAYTOTEXT(TRANSPOSE(D3:D39),1)
リスト化した結果をステップ名として指定したげれば、後で参照させることができるようになります(下図)。
Add_CN_JPのステップでは、全ての列をリストのリストとして結合しています。Table.ToColumnsという関数が、テーブルにある全ての列をリストのリストへ変換するためのM言語であり、こちらを使用します。
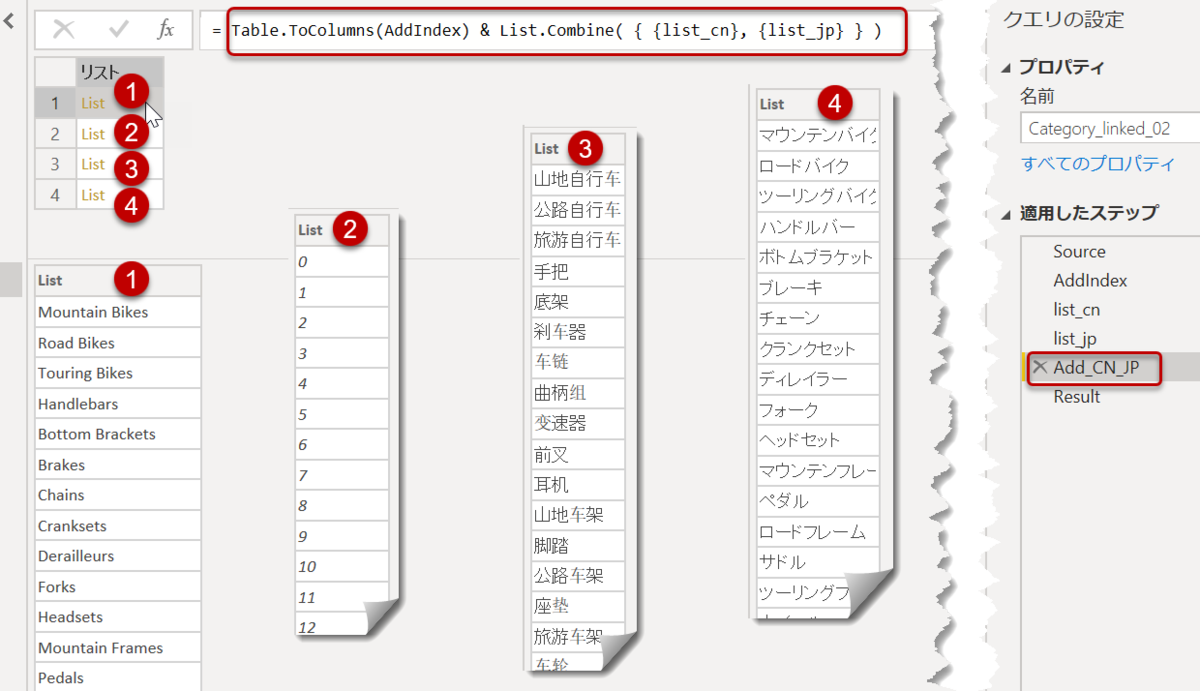
最後のResultでこのリストのリストを再度Table.FromColumns(Table.ToColumnsの逆)で戻してあげます。ただし、全ての列名が失われるので、もう一度マニュアルで指定してあげる必要があります。

このやり方は列名を再度指定しなおさないといけないというデメリットがありますが、列数が少ない場合には便利なやり方の1つかと思います。
Table.FromRows / Table.Transpose / Table.Combineを使用
このやり方はテーブル同士を結合する際に使用するTable.Combineを使用することになります。これを使用するためには、list_cnとlist_jpをそれぞれリストではなく、テーブルとして持つ必要があります。
let
Source = Table.Distinct(dProduct[[Category]]),
//dProductクエリのCategory列から重複削除
AddIndex = Table.AddIndexColumn(Source, "Index", 0, 1, Int64.Type),
//インデックス列の追加(ソート用)
list_cn = Table.FromRows( {{"山地自行车","公路自行车","旅游自行车","手把","底架","刹车器","车链","曲柄组","变速器","前叉","耳机","山地车架","脚踏","公路车架","座垫","旅游车架","车轮","背心短裤","帽子","手套","车衣","短裤","袜子","紧身衣","马甲","自行车架","自行车支架","瓶子和笼子","清洁器","挡泥板","头盔","补水包","车灯","锁具","储物箱","水泵","轮胎和管子"}}),
list_jp = Table.FromRows({{"マウンテンバイク","ロードバイク","ツーリングバイク","ハンドルバー","ボトムブラケット","ブレーキ","チェーン","クランクセット","ディレイラー","フォーク","ヘッドセット","マウンテンフレーム","ペダル","ロードフレーム","サドル","ツーリングフレーム","ホイール","ビブショーツ","キャップ","グローブ","ジャージ","ショーツ","ソックス","タイツ","ベスト","バイクラック","バイクスタンド","ボトル・ケージ","クリーナー","フェンダー","ヘルメット","ハイドレーションパック","ライト","ロック","パニア","ポンプ","タイヤ&チューブ"}}),
//Table.FromRowsでテーブルとして読み込む
Appended = Table.Combine({ Table.Transpose( AddIndex ), list_cn, list_jp } ),
//オリジナルテーブルをTransposeし、結合する
Transposed = Table.Transpose(Appended),
//Transpose Backし、従来の列数に戻す
Reamed = Table.RenameColumns(Transposed,{{"Column1", "Name"}, {"Column2", "Sort"}, {"Column3", "Name_CN"}, {"Column4", "Name_JP"}})
//列名を全て再指定する
in
Reamed
ポイントはTable.FromRows({{...}})で横長いテーブルを作ることです。ステップ名list_cnとlist_jpはもはやリストではないですが、以下のようにTable.FromRows関数を使用(中身はリストのリストということで、{}を2つ入れる)することで、横に伸びるテーブルを返してくれます。
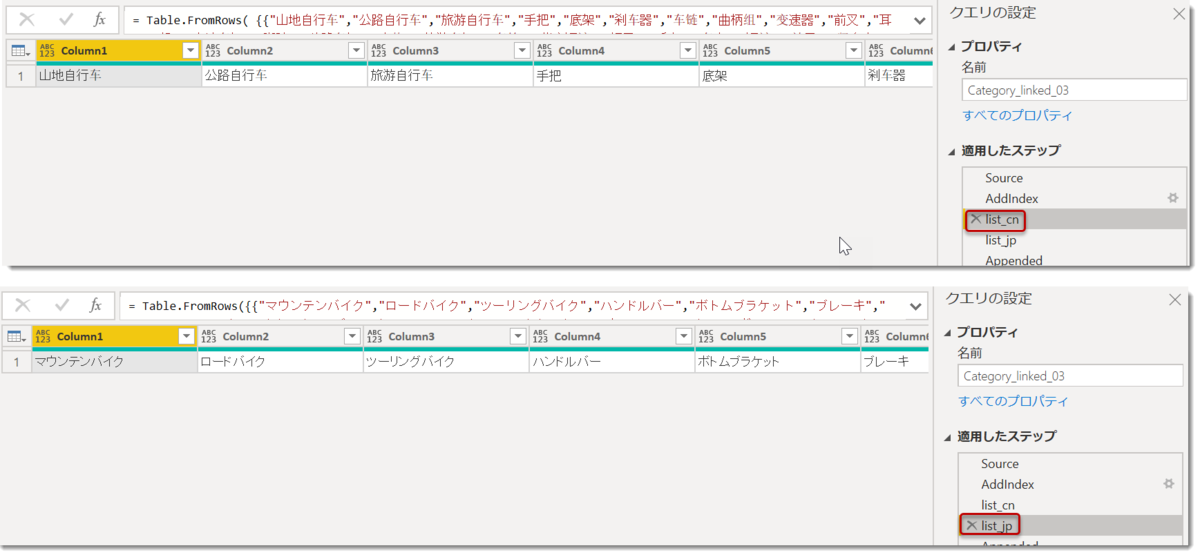
最初のクエリとこの2つのクエリを結合することで、横に長いクエリを作ることができました。
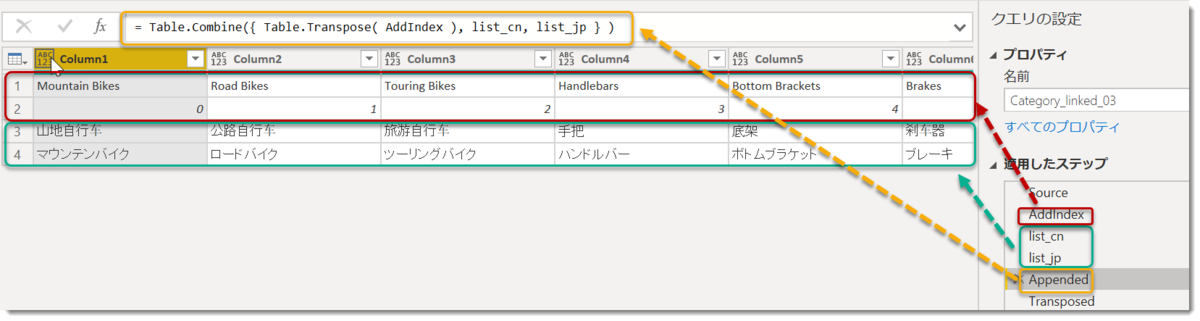
最後はこれをTable.Transposeで縦と横を入れ替え、名前を付ければ終了。
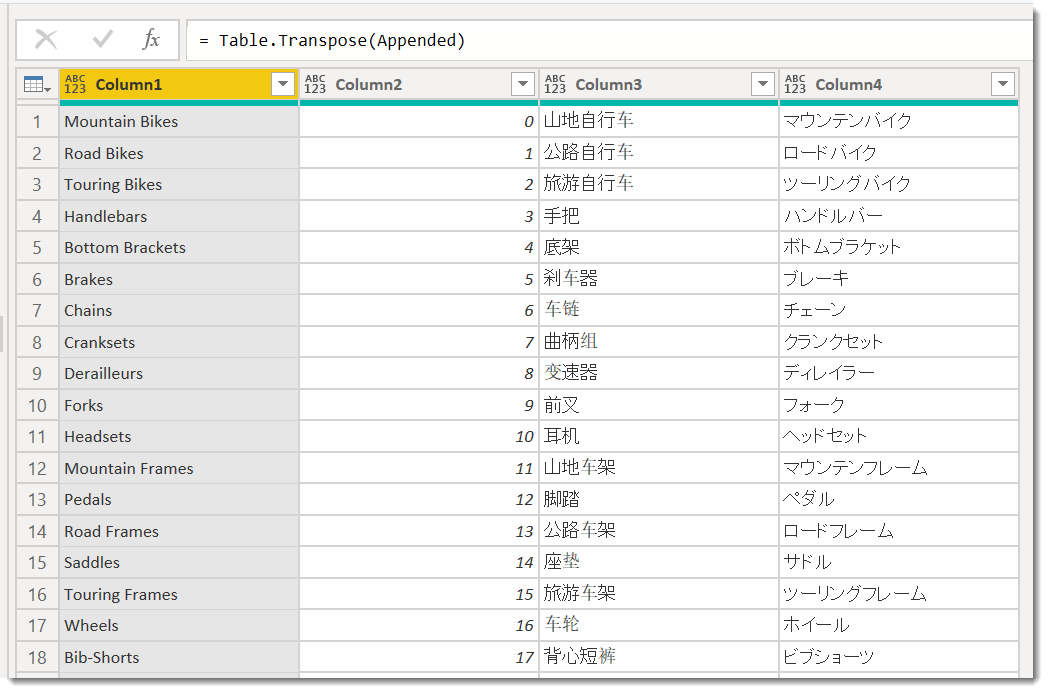
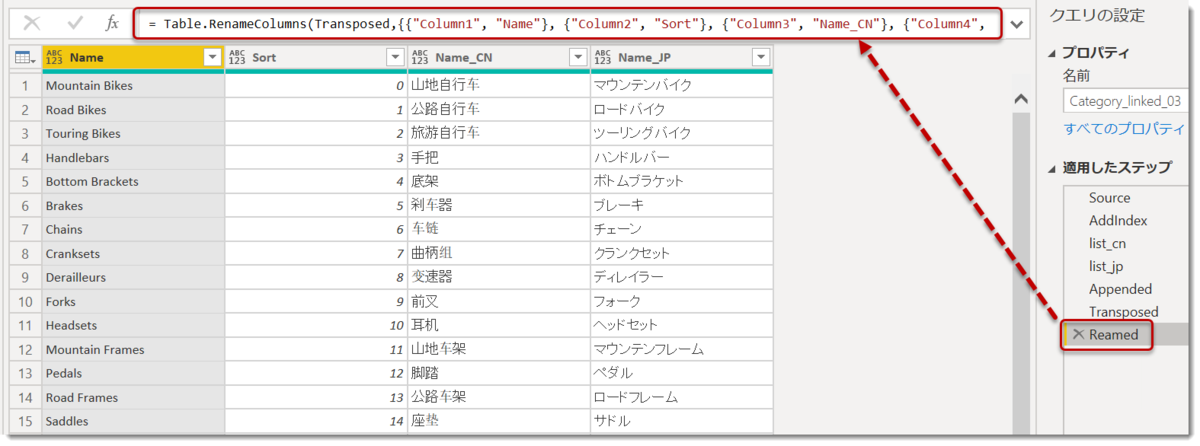
このやり方は列名を再度指定しなおさないといけないというデメリットに加え、Transposeが発生するため、データ量が多い場合、パフォーマンスが遅くなる可能性があります。とはいえ、事例の前提がLookupテーブルであることや大量データを想定していないことから、このやり方でも十分使えると思います。
Index列を利用
最後は少し特殊(少しクリエイティブ)なやり方となります。
let
Source = Table.Distinct(dProduct[[Category]]),
AddIndex = Table.AddIndexColumn(Source, "Index", 0, 1, Int64.Type),
AddCN = Table.AddColumn(AddIndex, "Category_CN", each {"山地自行车","公路自行车","旅游自行车","手把","底架","刹车器","车链","曲柄组","变速器","前叉","耳机","山地车架","脚踏","公路车架","座垫","旅游车架","车轮","背心短裤","帽子","手套","车衣","短裤","袜子","紧身衣","马甲","自行车架","自行车支架","瓶子和笼子","清洁器","挡泥板","头盔","补水包","车灯","锁具","储物箱","水泵","轮胎和管子"}
{[Index]}),
//リスト({..})を全ての行に追加し、Index列の数字を参照してリスト内の値を取得
AddJP = Table.AddColumn(AddCN, "Category_JP", each {"マウンテンバイク","ロードバイク","ツーリングバイク","ハンドルバー","ボトムブラケット","ブレーキ","チェーン","クランクセット","ディレイラー","フォーク","ヘッドセット","マウンテンフレーム","ペダル","ロードフレーム","サドル","ツーリングフレーム","ホイール","ビブショーツ","キャップ","グローブ","ジャージ","ショーツ","ソックス","タイツ","ベスト","バイクラック","バイクスタンド","ボトル・ケージ","クリーナー","フェンダー","ヘルメット","ハイドレーションパック","ライト","ロック","パニア","ポンプ","タイヤ&チューブ"}
{[Index]})
//同上
in
AddJP
このやり方の最大の特徴は{...}{[Index]}です。{[Index]}を入れなかった場合の追加された列は以下のようになります。
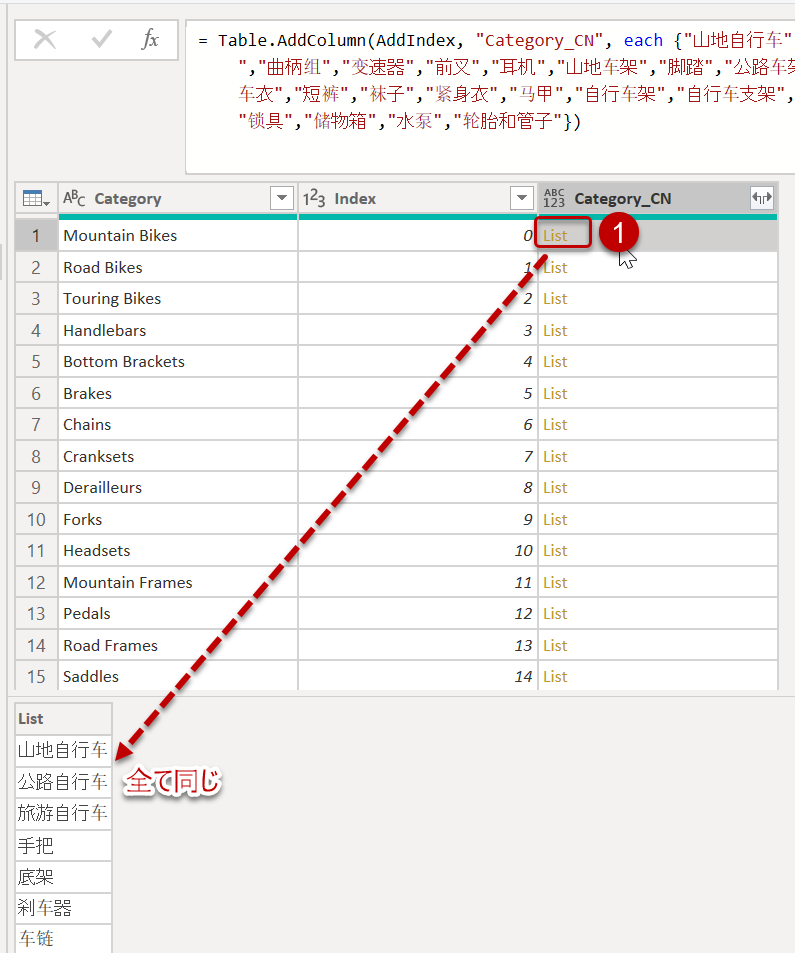
①のセルには{..}の中に入っている全ての項目が入っています。同様に、②のセルにも①と同じ項目が全て入っています。
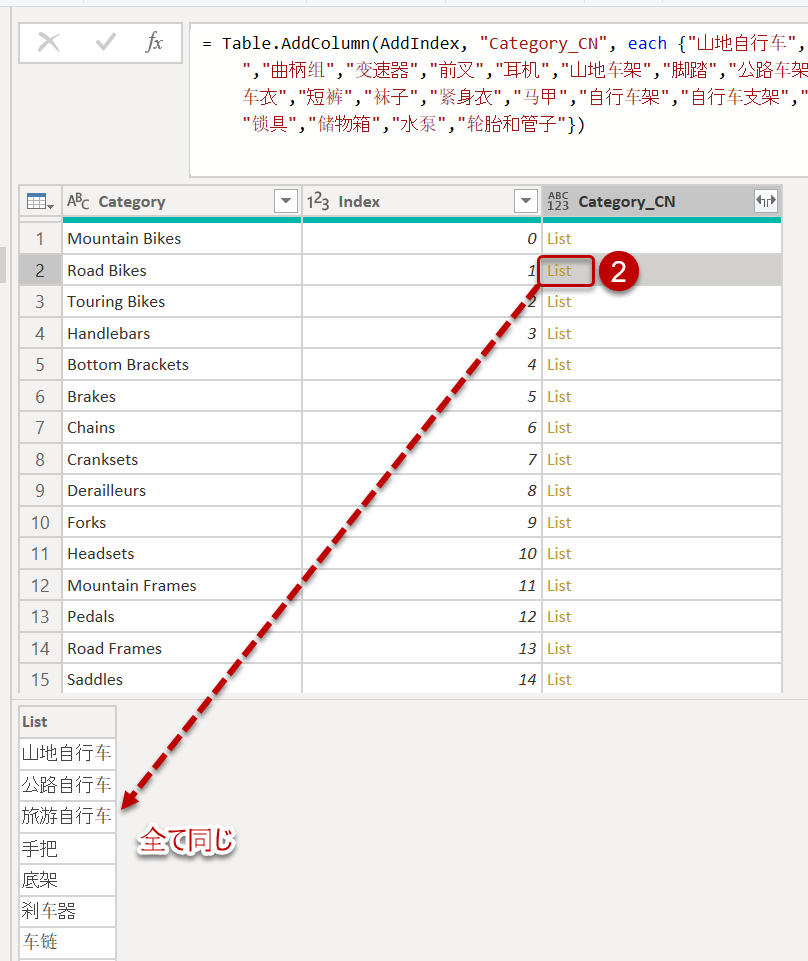
全てのセル内にリストで指定された全ての値が入っていますが、リストを参照する場合、{リスト}{順番}という書き方を行うことで、{リスト}{0}(リスト内の最初の値)、{リスト}{1}(リスト内の2番目の値)のように、それぞれの行から正しく項目を取得してくることが可能となります。
その結果、{リスト}{[Index]}と記載した場合、Index列内の数字を行数として参照を行うため、下図の通り、抽出したい項目をリスト内から取得することが可能となります。
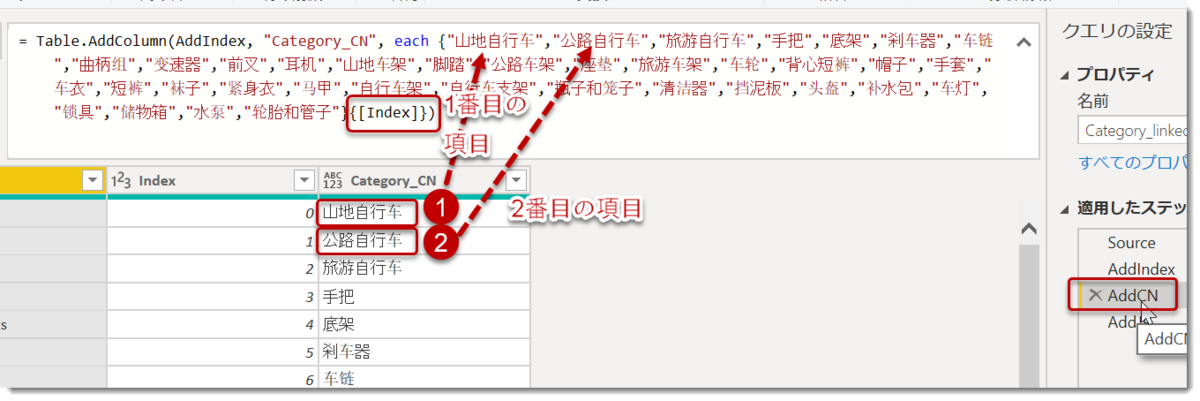
こちらのやり方はKagataさんの昔のツイートを参考にしたものとなります。
リスト内の値を各行で抽出するサンプルクエリは以下よりダウンロードできます。
https://bit.ly/3Jl1QXn