前回は、#sectionsキーワードを使用してPower Queryにクエリを追加する際に、自動的に集計を行う方法について説明しました。今回は、この手法を活用して各テーブルのメタデータ情報を集計する方法についてご紹介します。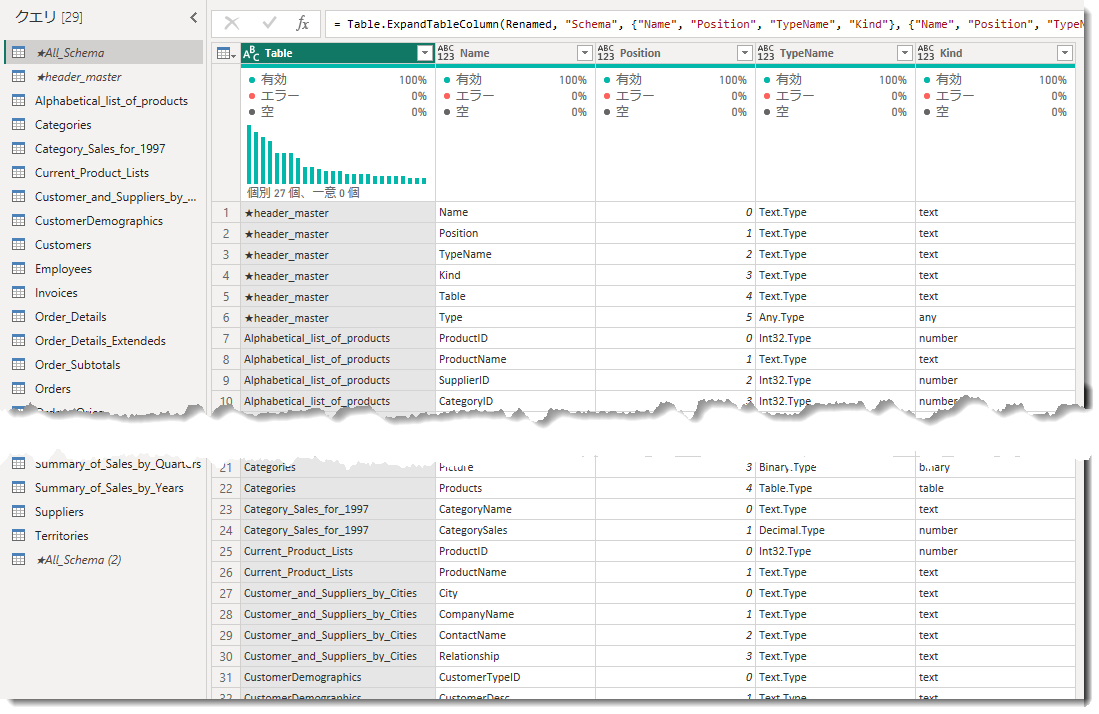
なお、この方法はデータモデリングのシーンにおいて、各テーブルの列の選択やデータ型の変更(特にローカルファイルなどを使用する場合)などの作業に活用することができます。
シナリオ
Power BIのデータモデリングは、スタースキーマに基づくDimテーブルとFactテーブルをリレーションシップで関連付ける作業です。このプロセスにおいて、次の重要なポイントがあります。
これらの中でも、1は不必要な列や行を取り除き、データ量を最適化することが重要であることを強調しています。
そのため、ソースデータの分析(データ内容の詳細検討)において、テーブルと列の情報を制限することが一つの鍵となります。この中で、列は属性とも呼ばれる要素であり、Power BIではTable.Schemaを使用することでこれを簡単に特定できます。
サンプルデータの抽出
今回は、以下のODataフィードをデータソースとして活用します。ODataフィードは、RESTfulなWebサービスを介してデータにアクセスするためのプロトコルであり、異なるデータソースやアプリケーション間でデータを共有・操作するための標準的な手段を提供します。クライアントアプリケーションは、ODataフィードを使用してデータを取得し、必要な操作を行うことができ、異なるシステム間でのデータ連携が簡単になります。
データソース(ODataフィード)
https://services.odata.org/V4/Northwind/Northwind.svc/
なお、Odataフィードについては下記ブログが非常に分かりやすいです。
以下データを取得するやり方となります。
- Power BI DesktopからOData.Feedコネクタで接続
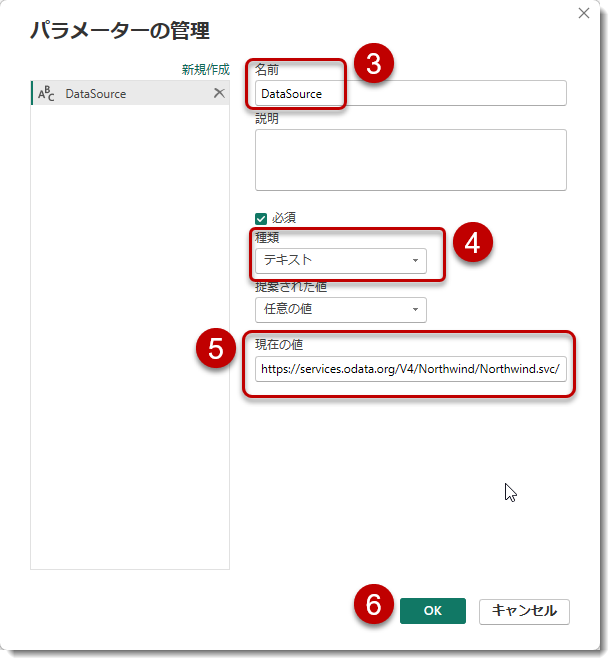
- パラメーターを設定し、ODataフィードのURLを入力

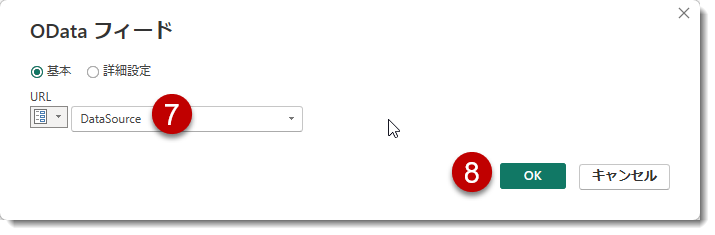
- 設定を確認し、テーブルを全て選択
- 成功すると、全てのクエリを取得できていることを確認できる
- クエリペインにて、右クリック > 新しいクエリ > 空のクエリ > ★All_Schemaという名前のクエリを作成し、「読み込みを有効にする」のチェックを外す
- 数式バーに#sections[Section1]を入力
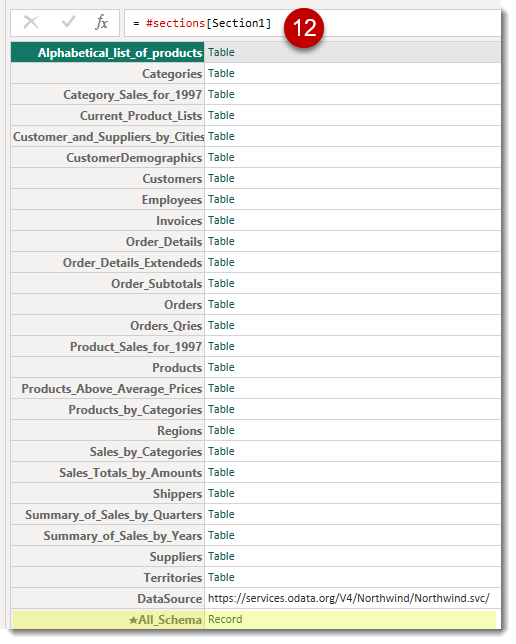
- テーブル化
- ★とSourceという名前を含む行を除外
- Value列に対してTable.Schemaを使ったSchema列を追加
- Name列をTableにリネーム
- Schema列の中身(各テーブルのメタデータ情報)を新しい列に展開
ソースコードと結果は以下の通り。

ODataフィードはデータベースや他のデータソースから抽出されるデータであるため、TypeName(列の型の名前)やKind(列の型の種類)は定義済となっています。従って、抽出されたデータに対して改めてデータ型を指定する必要はありません。
一方、ODataフィードではなく、ExcelやCSV等のローカルファイルからデータを抽出した場合、自分でデータ型を指定する必要があるため、そのやり方については次回以降に解説します。
メタデータ情報を別のクエリとしてコピー
抽出されたテーブルを少し眺めてみます。Kindで絞ってみると、binaryやrecord、tableといった列タイプが存在することが分かりました。これらのデータはそのままでは使用することはできないため、新たな行や列へと展開する必要があります。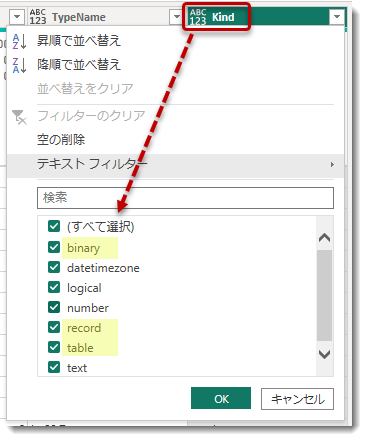
不必要な場合は、フィルターを使用して外すことができますが、今回は新たに★header_masterというクエリを作成します。★All_Schemaクエリは5列204行というデータ量(5列 × 204行 = 1,020セル)ですので、「データの入力」の制限*1を下回っています。そのため、以下のように新しいクエリを作成できます。
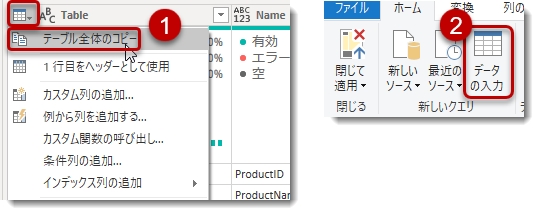
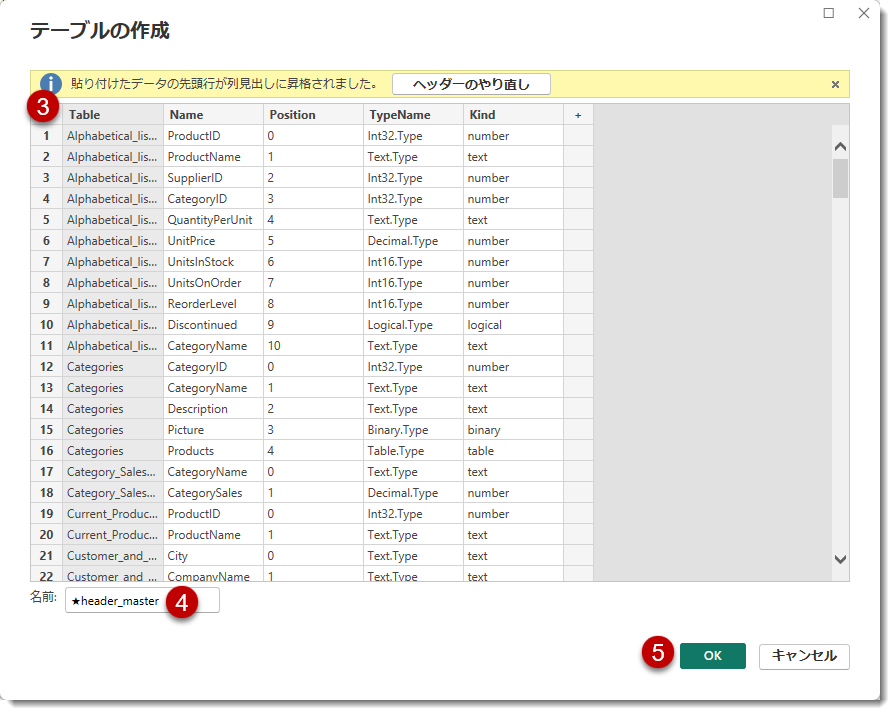
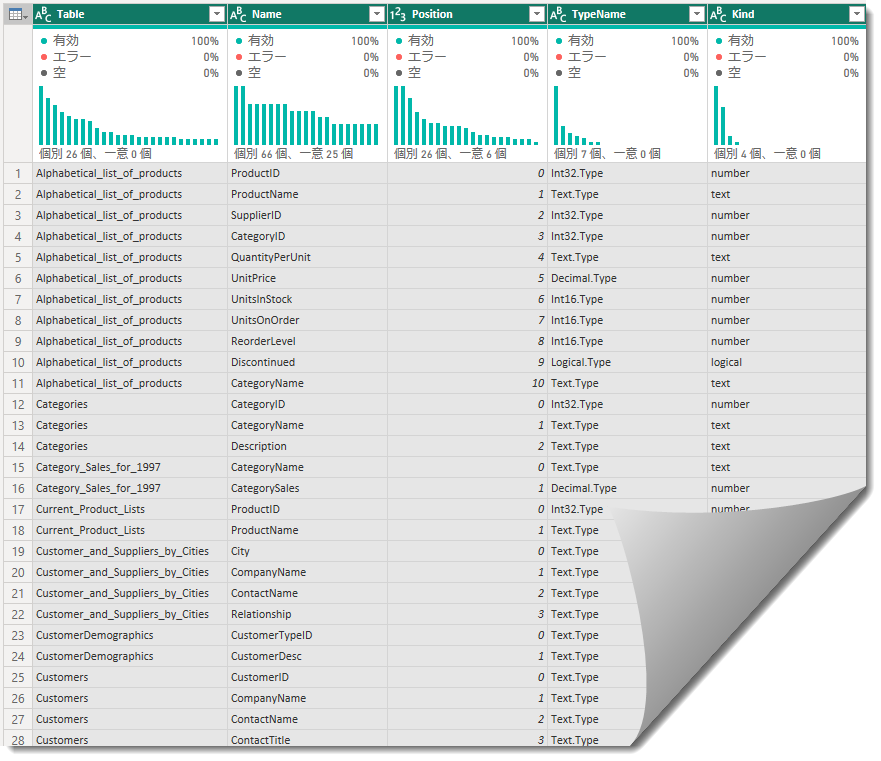
このクエリを作成した理由は前回記事にて言及した”落とし穴”が関係しており、★All_Schemaをヘルパーテーブル*2としてそのまま使用した場合、Power BI Desktopはデータを読み込むことができません。更に、モデリングに必要な列をヘルパーテーブルで定義した列名から選択できないため、どちらにせよ、★header_masterクエリを作る必要があります。
カスタム関数
今回のやり方をカスタム関数にすることで、除外キーワード(2つまで)を入力して一発でテーブルスキーマ情報を取得できるようにしました。以下のソースコードでfnGetSchemaという名前のカスタム関数を作ることができます。
最後に
データモデリングにおけるメタデータ情報はテーブル定義書*3に相当します。Power BIにおけるモデリングのベストプラクティスは、前述の1~3の方法として述べられていますが、今回の手法は必要な列やデータ型などの情報を取得するために便利なアプローチの1つとなります。