Direct LakeはFabricアイテムであるLakehouseやWarehouseを活用しますが、データがDelta Parquet形式*1となります。Power BIサービスに発行されたセマンティックモデルはインポートモードであることが多いですが、今回はこのインポートモードやDirectQueryモードのセマンティックモデルをDirect Lakeへ移行(マイグレーション)するやり方を紹介します。
なお、今回の方法は前回のOneLake Integrationとは異なり、ショートカットを作るのではなく、Dataflow Gen2を使用してDelta Parquetファイルを作成していく方法です。この方法により、リレーションシップやDAXメジャー、セマンティックモデルに関する各種の定義済みプロパティのほぼすべてを復元することが可能です。
ユースケース
Microsoft Fabricを使用するインセンティブの1つはDirect Lakeです。Direct Lakeは、LakehouseやWarehouseにある最新のデータをクエリに必要な最小限のデータをメモリに読み込み(トランスコーディング: Chris Webbによる参照ブログ)ます。これにより、データを全てメモリに読み込むことなく、鮮度の高い情報をPower BIのレポートで可視化できます。本ブログでもDirect Lakeの特徴について解説しており、詳しくはこちらをご参考ください。
マイグレーションするシナリオはいくつかあると思いますが、以下が考えられるでしょう。
- インポートモードでデータの更新に時間が掛かっている
- 鮮度の高いデータを使ってレポートを作りたいが、DirectQueryではレポートのパフォーマンスが悪い
- セマンティックモデルの更新によるFabricのリソースを節約したい
これらの問題に対処するため、Direct Lakeを活用することを考慮できす。Direct Lakeは、DirectQueryのデータ鮮度を保持しつつ、インポートモードに匹敵するクエリパフォーマンスを実現できることが特徴です。これは、Fabricのキラーフィーチャーの1つであり、Power BI単体では得られない利点となります。
マイグレーション
同じチームでBPA(Best Practice Aanlyzer)を開発したMichael Kovalskyがこの手法を教えてくれました。マイグレーションを行うために、まずはいくつか準備が必要となります。
下準備
- Fabricを使用できる環境であること
こちらより、試用版を開始できます。 - OneLake Explorerをインストールしていく
- XMLAエンドポイントを有効*2にする
- データモデル(セマンティックモデル)の編集を可能にする(ワークスペース名は自由、💎アイコンはFabric容量)

他にも留意点はありますが、まずはこれらの設定を行ってください。
ここから下記MichaelのGithubに従って進めていけば良いですが、分かりやすく図説していきます。
- Githubを参照する
GitHub - m-kovalsky/Fabric: Useful code for fabric notebooks
Githubでも解説がありますが、Prerequisites(前提条件)で記載されている3つのうち、2つを上に記載しました。 Lakehouseについては後から作ることも可能ですので、割愛しました。 - notebookをダウンロードします
開いた先の右側のアイコンをクリックして、notebook(Migration to Direct Lake.ipynb)をダウンロード。notebookはデータエンジニアリング(ETL業務)やデータサイエンス等で使用される定義済みコードであり、カスタム関数や繰り返し利用できるコードのようなものと覚えておくと分かりやすいでしょう。
- マイグレーションしたいPower BIセマンティックモデルを確認
ブログではImported_InvSalesという名前のセマンティックモデルとPBIレポートを例に解説をします。なお、このセマンティックモデルでは、インポートされたテーブルとそれを基に作った計算テーブルの2種類があります(下図参照)。後述しますが、計算テーブルはDelta Parquetファイルとして読み込まれません。

- notebookをインポート左下のアイコンを「Data Engineering」に変更し、対象となるワークスペースをクリック > 新規「ノートブックのインポート」

先程ダウンロードしたnotebookをインポートします。

この状態ではまだレイクハウスを設定していないので、レイクハウスをクリックし、Addでレイクハウスを追加します。

どちらかを選択し、レイクハウスを指定。これでそのレイクハウス内にてnotebookを使って様々な処理を行うことができるようになりました。
ここまでの処理はGithubのここ(Instructions)までを説明したものとなります。
詳細ステップ
ここからは、notebookを使用してマイグレーションを行っていきます。コードが多く登場しますが、基本的にはUI操作だけで完了しますので、難しくはありません。以下の手順に従い、notebookを実行し、Dataflow Gen2を活用してマイグレーションを行います。基本的には、notebookに記載された指示に従って操作を行うだけです。
- Semantic Linkをインストール
以下のように、コードセル内に%pip install semantic-linkと入力し、▷をクリック。ステップ2の上に、+コードで挿入できます。
- 最初のコマンドを実行します
分かりやすいよう、各ラインの意味を日本語にしています。Install the latest .whl packageとありますので、.whl package*3をインストールしているのが分かります。
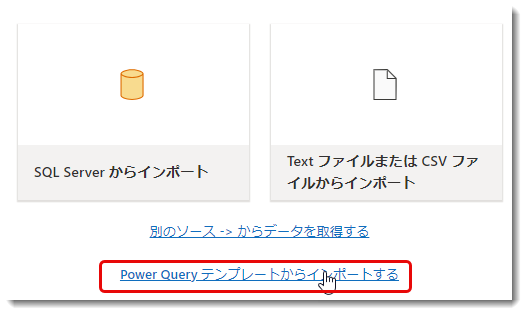
- Power Query Template*4を作成する
次のコードセル*5ではPower Query Templateを指定したLakehouseのFilesの中に作ります。▷をクリックする前に、下図のように、対象となるセマンティックモデルの名前を記入します。
- コードセルの左下に✅(成功)があるのを確認し、Files > ... > 最新の情報に更新、をクリックし、PowerQueryTempalte.pqtが生成されたことを確認(1回で出現しない場合は数回更新ボタンを押してみてください)

- OneLake Explorerから対象のワークスペースを右クリックし、Sync from OneLakeをクリック

フォルダの中に入り、対象のレイクハウス > Files > PowerQueryTemplate.pqtをダウンロードした状態にする(下図)

-
Data Factory > 対象ワークスペース > 新規 > データフロー (Gen2)の順番に選択

-
名前を変更し、PowerQueryTemplate.pqtをインポート


-
「接続の構成」をクリック(資格情報の設定)
今回データソースはDatafloe Gen1だったため、そのまま「接続」をクリック。
Power QueryテーブルがDataflow Gen2側で取得できていることを確認。
なお、ここまで何をやってきたことをまとめると以下の通りになります。- 説明割愛
-
Power BI DesktopからPower BIサービスへImported_InvSales.pbixを発行
-
セマンティックモデルのオリジナルデータはDataflow Gen1をソースとしている
-
- 説明済
- notebookを使用し、発行済のセマンティックモデルのETL部分(Power Query)をPower QueryテンプレートとしてレイクハウスのFilesに保存
- Dataflow Gen2でそのテンプレートを読み込み、Dataflow Gen1をソースとしたクエリを上図の通り生成
- 説明割愛
-
各テーブルの読み込み先を指定
現時点での制限は、Power Queryテンプレートを使用する際に、テーブルのロード先がまだ指定されていないことです。


🔎ボックスでワークスペースの一部を入力し、テーブル名を指定します(レイクハウス名だと検索できない)。なお、レイクハウスに既に同じテーブル名が存在していた場合は名前を変更する必要があります。また、その存在していたテーブルを削除した直後では、「テーブルが存在する」というメッセージが出現する可能性があるため、少し時間を置いて指定するとうまく行きます。
列マッピングを行い、「設定の保存」を押します。これで1つのテーブルが完了ですが、レイクハウスへ持っていきたい全てのテーブルに対してこれを行います(=セマンティックモデルに必要なテーブル全て)。 -
レイクハウスへロードする全てのテーブルに対して、「ステージングクエリを有効にする」のチェックをオフにし、「公開」をクリック


なお、非常に混乱しがちですが、Dataflow Gen2では、「ステージングを有効にする」をチェックオフの状態にしても、データが「データ同期先」にロードされないわけではないことに注意することが重要です。この設定は、データがステージングされるか or されないかを制御するものであり、このインパクトについては下記ブログに詳細が記述されています。
Data Factory Spotlight: Dataflow Gen2 | Blog de Microsoft Fabric | Microsoft Fabric
-
公開すると、Dataflow Gen2が更新されます
対象となるレイクハウスへDelta ParquetファイルをソースであるDataflow Gen1からデータを取得して、ステージングクエリを作らずに「データ同期先」へDelta Parquetテーブルとしてロードされます。
- レイクハウスでデータがロードされていることを確認

ここでSQL 分析エンドポイントへ行き、セマンティックモデル (ディフォルト)のダイアグラムを見ると、以下のようにリレーションシップも何もない状態のテーブルが複数出現していることを確認できます。 なお、△のアイコンは既知の問題(詳細は画像参照)で、開発側による修正を待っている状態です。
なお、△のアイコンは既知の問題(詳細は画像参照)で、開発側による修正を待っている状態です。 - notebookに戻り、以下の順番に従って進めていきます。


成功すると上図のように、各テーブルに対して処理が行われますが、エラーが発生する場合(セッション切れ等)は、もう一度セッションを開始して、冒頭からコードセルの中身を実行してください。 - ワークスペースに戻り、指定した名前で新しいセマンティックモデルが作られていることを確認。

これでセマンティックモデルは合計3つ(下図)存在することになりますが、aはレイクハウスを作った際に自動生成されたセマンティックモデル(ディフォルト)、bはインポートモードのセマンティックモデル、そしてcがImported_InvSalesのメタデータ情報を抽出し、delta_InvSalesとして作られたカスタムのセマンティックモデルとなります。このdelta_InvSalesが今回のメインとなります。
- delta_InvSalesを開き、中身を確認

上図より、インポートモードで作られたリレーションシップやDAXメジャー等が復元された状態となっていることを確認できます。前述の通り、dWarehouseテーブルは計算テーブルにつき、Direct Lakeではサポートされておらず、テーブルとして読み込まれません。
ただし、Michaelによると、下図の通り、ベータ版では計算テーブルをDelta Parquetテーブルとして生成できるようになるという。計算テーブルまで抽出できると更に便利になるので、今後に期待したいところです。
- Imported_InvSalesのリネージ(系列)を確認します

Imported_InvSalesレポートはこの後、delta_InvSales(セマンティックモデル)にRebind(参照先変更)されるため、念の為、以下のようにレポートを複製します。

これでインポートモードのレポートを残しつつ、Imported_InvSalesレポートの参照先をdelta_InvSales(セマンティックモデル)に変更できます。
- notebookに戻り、Rebind all...のコードセルをRunしますが、下記のコードをそのまま走らせてはいけません(※重要)
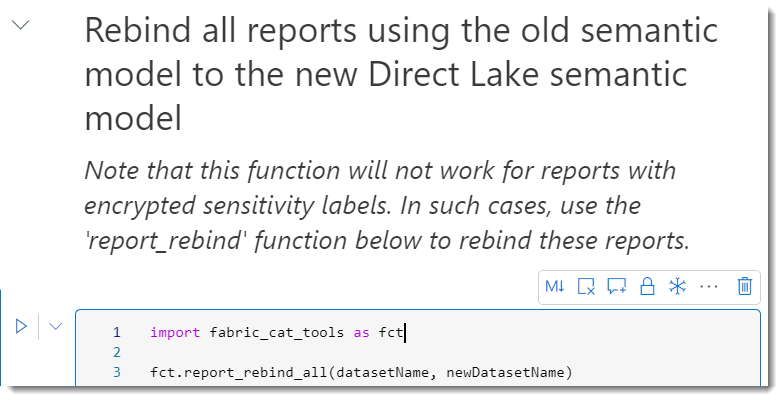
こちら、秘密度ラベルが入っているレポートについてはこちらの技が使えないと書いてありますが、上記コードを走らせると、せっかく複製したレポートまでもがdelta_InvSales(セマンティックモデル)にRebindされてしまいます。 - 従って、代わりに下記のコードセル内のreportNameにImported_InvSalesを指定し、Runをクリックします。

これにより、下図の通り、指定したレポートだけが参照先が変わります。
- 結果チェック
Imported_InvSalesレポートを開くと、計算テーブルがあるレポートではエラーが発生し、参照セマンティックモデルではDirect Lakeになっていることを確認できます。これはこのビジュアルでは計算テーブルが使用されていることが原因で、想定の範囲内となります。
ジョブのモニタリング
ここまでミスなくやってきましたが、どのようなジョブを実行したかを監視するため、下記監視ハブを利用すると良いでしょう。エラーが発生したジョブを特定しやすくなります。

最後に
今回のやり方は慣れれば非常に簡単ですが、今後いずれ、FabricのUIベースで実現できるようになるかもしれません(Fabricのリーダーシップによるリクエスト)。Michaelはエンジニアチームと密接にコラボしており、これに向けていくつかの課題解決をしながら進めているようです。
バグなどまだ存在すると思いますので、もし見つけたら下記Githubへ報告してあげてください。
計算テーブルを作るやり方もMichaelによってブログで紹介されてので、下記より確認できます。
https://www.elegantbi.com/post/direct-lake-migration
*1:Delta Parquetファイルは、Apache Parquetフォーマットを基盤としたDelta Lakeのファイル形式です。Delta Lakeは、データのバージョニング、トランザクション管理、ACIDトランザクションのサポートなどの機能を提供するデータレイクテクノロジーです。Delta Parquetファイルは、これらの機能を利用して、高速で拡張性のあるデータレイクを構築することができます。Parquetフォーマットは、列指向のデータストレージ形式であり、高い圧縮率と効率的なデータ処理を実現します。Delta Parquetファイルは、このParquetフォーマットにデータレイクの追加機能を提供し、大規模なデータセットの管理や分析を容易にします。
*2:XMLA(XML for Analysis)エンドポイントは、Power BIサービスで提供される機能の一つ。XMLAは、データの分析やクエリを行うための業界標準のプロトコルです。XMLAエンドポイントを有効にすると、Power BIセマンティックモデルはTabularモデルとしてアクセスできるようになり、より高度な分析や柔軟なクエリが可能になります
*3:.whlファイルはPythonのパッケージの配布形式の一つであり、Wheel(ホイール)と呼ばれます。Wheelは、Pythonプロジェクトを簡単に配布およびインストールするためのバイナリ形式のパッケージフォーマットです。通常、.whlファイルは、ソースコードからビルドされたPythonのパッケージを含んでいます。一般的に、.whlファイルはPythonのパッケージマネージャーであるpipを使用してインストールされます。pipは、.whl形式のパッケージを自動的にダウンロードしてインストールすることができます。
*4:データの抽出元や処理の流れを定義したテンプレート。Excel Power Queryやデータフローから作ることができます。
*5:コードセルは、セル(セクション)ごとにコードを記述し、そのコードを実行するための領域です。通常、セルごとに独立したコードを記述し、そのセルを実行することでコードを実行します。