Microsoft FabricがGA(一般提供)されてから半年が経ち、統一されたデータ基盤という”切り口”で導入を決めた企業も増えています。しかし、Power BIを本格的に活用したことがない企業も少なくありません。本ブログではこれまでにも日付テーブルについて触れてきましたが、日付テーブルに特化して書いたことはありませんでした。そこで今回は、日付テーブルの重要性について詳しく解説していきたいと思います。
日付テーブルの基本
概念
上図では、dCalendarテーブルとSalesテーブルの年月列を1対多(*)のリレーションシップで結びつけています。これは「スタースキーマ」(その他①、②)と呼ばれる構造で、Power BIにおけるベストプラクティスのモデリング手法です(下図参照)。
売上などの取引実績データで構成されたテーブル(Fact Table)に対し、日付や店舗といったDimensionテーブル(日付マスタ、店舗マスタなど)が1対多のリレーションシップで直接紐づいている状態がスタースキーマです。このうち、日付テーブルでは通常、日付型の列をFactテーブルの同じ型の列とリレーションシップで結びます(例外あり)。こうすることで、Power BIでビジュアル(例: 時系列チャート)を作成する際に、日付テーブル(dCalendar)の列を基準軸として使用できます(下図参照)。 ここで重要なのは、X軸(時系列軸)にSalesテーブルの列を使用していないことです。複数のFactテーブルがある場合に、dCalendarを使用することで一括してフィルタリングできるためです(下図)。
ここで重要なのは、X軸(時系列軸)にSalesテーブルの列を使用していないことです。複数のFactテーブルがある場合に、dCalendarを使用することで一括してフィルタリングできるためです(下図)。 上図は、日付(Dimension)テーブルを使用して、在庫明細、売上明細、仕入明細の3つのFactテーブルを同時にフィルタリングできることを示しています。このように、日付テーブルを利用することで、在庫と売上のデータを組み合わせて、下図のような複合チャートを作成することが可能になります。
上図は、日付(Dimension)テーブルを使用して、在庫明細、売上明細、仕入明細の3つのFactテーブルを同時にフィルタリングできることを示しています。このように、日付テーブルを利用することで、在庫と売上のデータを組み合わせて、下図のような複合チャートを作成することが可能になります。


なぜ日付テーブルが必要か
上記で解説した通り、以下2つが回答となります。
ただし、更に詳細に見ていくと、以下のようなデメリットが存在することになります。
- タイムインテリジェンス計算*1が使用できない
- 複数の日付階層はレポートを読みにくくする
- スタンダードな日付(1/1~12/31)までの計算しかできない(カスタムされた日付計算を行うことができない)
これらのデメリットについては、この後いろいろ詳述していくこととします。
Power BI Desktopの設定
Power BIを初めて使用する場合、真っ先にPower BI Desktopで以下の設定を行う必要があります。特に、日付関連の設定は後の分析やビジュアル化に大きな影響を与えるため、慎重に行う必要があります。
- Power BI Desktopを開く > 「ファイル」

- オプションと設定 > オプション

- 以下AとBの両方でチェックを外す
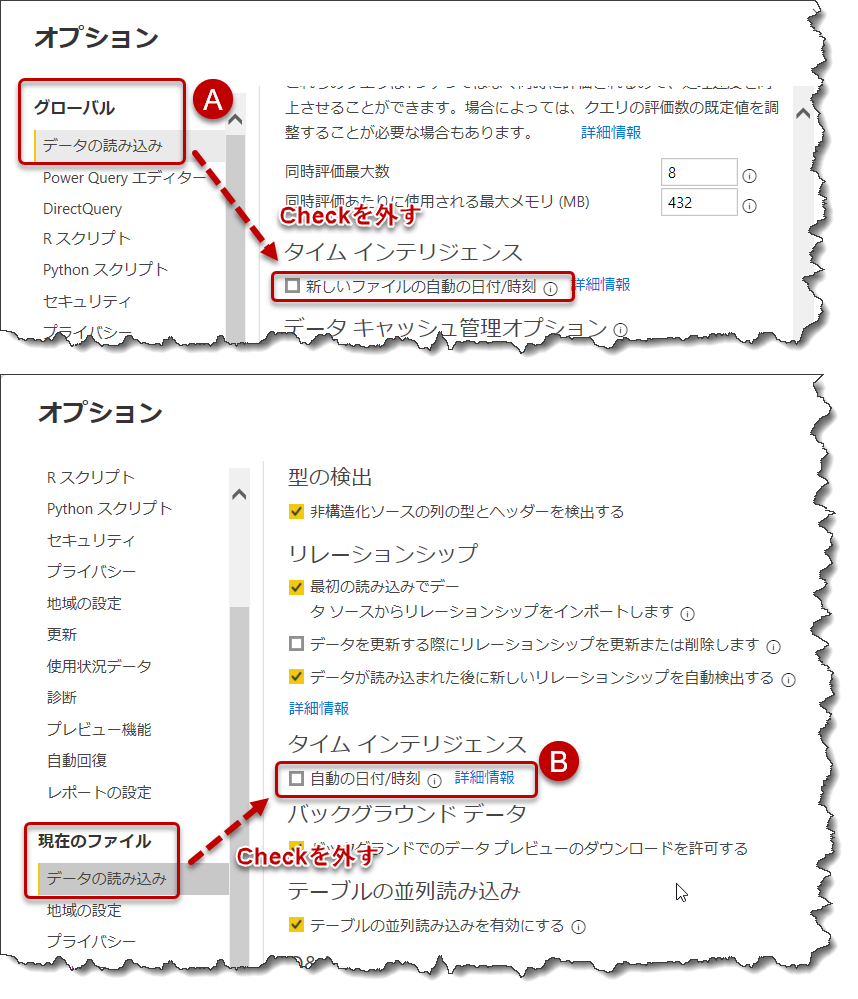
初心者向けのトレーニングなどで、この設定を行っていないケースを時々見かけます。しかし、以下の説明を読むことで、なぜこの設定が重要なのかを理解していただけると思います。
未設定による副作用
上記の設定を行わない場合、主に以下2つの副作用が発生します。なお、今回の説明ではスタースキーマが完成していることを前提としていますが、シングルテーブルで作業を行った場合には、日付テーブル以外でAuto-exists (動画) という副作用が発生する可能性があります*2。
- 「タイム インテリジェンス」の☐をOFFにしなかった場合、日付データがあるテーブルで日付階層が勝手に作られてしまう
- 非表示の日付テーブルが作られてしまい、場合によってはセマンティックモデルのサイズが肥大化する
まず1つ目の副作用ですが、日付型の列がある場合、「日付の階層」が自動的に作成されてしまいます。最初はこれが便利に思えるかもしれません。しかし、実際には多くの場合、この自動生成された階層を使わずにデータを分析することが多く、逆に煩わしさを感じることが多くなります。
なお、階層は同じテーブル内の列同士でしか作成できないことに注意が必要です。
次に2ですが、Power BI Desktopで「オプション」>「データの読み込み」>「タイム インテリジェンス」の設定項目にある?アイコンをクリックすると、説明が表示されます。
こちらが何を意味するか、以下のスモールデータ(サンプルデータ)のセマンティックモデルを例に見ていきます。
各テーブルは以下のような構成になっています。


- DAX Studio*3がインストールされていることを確認
- 設定にある「タイム インテリジェンス」が✅された状態でPower BI Desktopの外部ツールからこれを立ち上げます
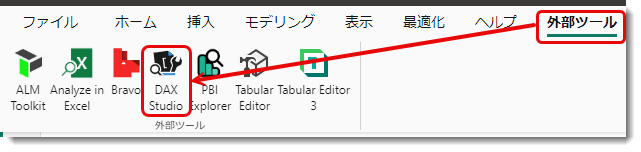
- 左側のMetadataペインより、グレイとなっているLocalDateTableやDateTableTemplateといったテーブルがあることを確認

これらのテーブルは非表示の状態になっており、Power BI Desktop上からは確認できません。しかし、DAX Studioを使用することで、Power BI セマンティックモデルのメタデータ情報を確認し、これらの隠されたテーブルの存在を明らかにすることができます。ちなみに、「タイム インテリジェンス」のオプションが無効(☐オフ)になっている場合、これらの非表示テーブルは生成されません。
ここでこれらのテーブルについて少し吟味します。
- 3つのテーブルのうち、日付列は合計5つありますが、dCalendar(Dimテーブル)とSales(Factテーブル)の日付列を紐づけると、Fact側の日付列(今回の例ではPurchaseDate列)のアイコンは消えてしまいます

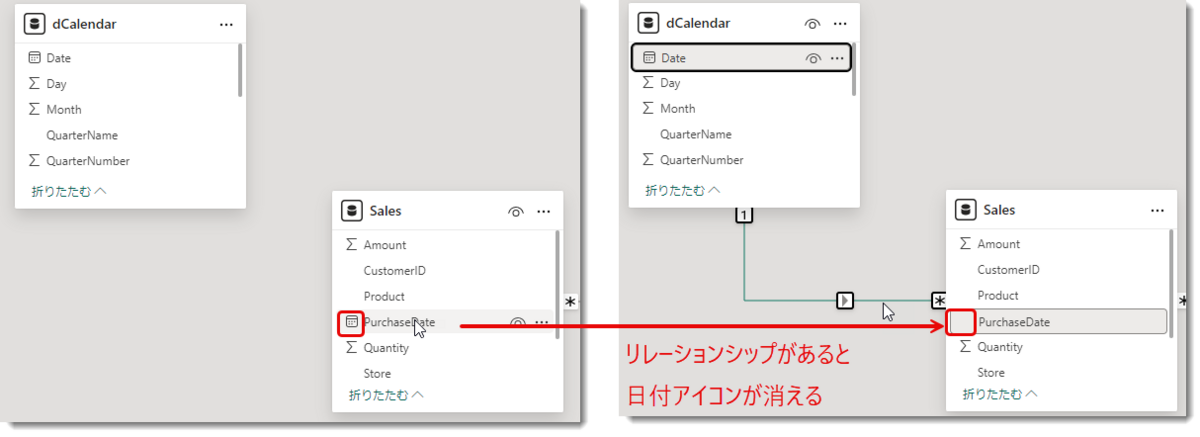
- これにより、DAX Studioで観測できる日付型の列は4つとなり、それぞれの列に1つずつ非表示されたLocalDateTable(日付テーブル)が構築されます

-
これらの非表示テーブルは、下図に示すように、7列の日付マスタとして構築されます。テーブルは、各列の最も古い日付から最新の日付までの期間をカバーし、その期間に含まれる年の1月1日から12月31日までの範囲で自動的に作成されます
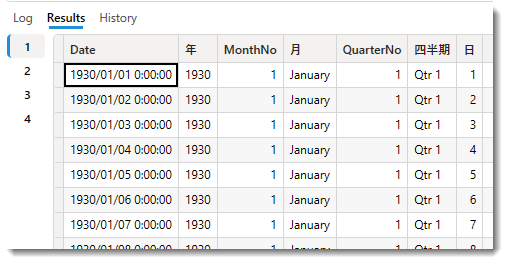

- DAXメジャーや計算列を使用すると、これらの非表示テーブルにアクセスすることが可能です。例えば、下図では、dCustomer[Birthday]列から最も古い年を抽出し、Salesテーブルに計算列を追加しています。この結果、上図に示されたCustomer ID = 1のデータから、1930年という年が抽出されています。

確かに便利な機能ではありますが、この機能を実際に使用している人を見かけることはほとんどありません。加えて、この機能を無効にする(✅を外す)ことが重要ですので、ここでの情報はあくまで参考としてご覧ください。
さて、周り道してしまいましたが、ここから2番目の「セマンティックモデルのサイズが肥大化する」について見ていきます。DAX StudioのAdvancedタブからView Metricsを選択すると、VertiPaq Analyzerからセマンティックモデルのメタデータ情報を確認することができます。
LocalDateTableがモデル全体で使用するメモリの大部分を占めていることがわかります。例えば、LocalDateTableの% DBの値が85.45%(Total Size ÷ 全体のTotal Size)となっており、モデル全体のメモリ使用量の大半をこの非表示テーブルが占めていることが示されています。
Power BIでは、インポートされたデータがメモリに格納されます。メモリ使用量を最小限に抑えることは、セマンティックモデルのパフォーマンスを向上させる上で非常に重要です。
Summaryタブを確認してみると、ほとんどデータ量がないセマンティックモデルでありながら、2.81MBのメモリを使用していることがわかります(pbixは371KB)。これらの不要なメモリ使用を抑えることで、モデルの効率を高めることができます。

ここから「タイム インテリジェンス」のチェックを外し(☐オフ)、DAX Studioで再びView Metricsをクリックし、VertiPaq Analyzerの結果を確認してみましょう。結果は以下の通り。

元のデータ量が小さかったことも影響し、ファイルサイズは実に94%(pbixは371KB → 88KB)も減少しました。このような大幅な削減は驚くべきものですが、実際の運用環境でも、同様に劇的な効果が得られることがあります。
なぜこのようなことが起こったのでしょうか。それは、Power BIが自動で生成する非表示の日付テーブルが、すべてのテーブルの日付列に対して最小値と最大値を基準に構築されるためです。具体的には、今回の例では「Birthday」列に1930年という日付が含まれていたため、その影響で1930年1月1日から2023年12月31日までの全ての日付がカバーされる非表示の日付テーブル(3.4万行×7列のテーブル)が作成されていました。
Power BIの公式ドキュメントでも独自の日付テーブルを構築することを推奨していますが、その背景には、これまでに説明したような理由があります。
なお、日付テーブルを作ることはPower BIにおけるタイムインテリジェンス計算を可能にするものですが、下記SQLBIの記事も併せてご参照ください。
呼び方
日本語では、「日付テーブル」または「カレンダーテーブル」と呼ばれますが、個人的には「日付テーブル」の方がしっくりきます。英語では「Date table」が一般的な呼び方です。また、「日付マスタ」と表現した場合でも同じになります。
テーブルのネーミング規則
データモデルの中で、今回の例では日付テーブルを「dCalendar」としています。テーブルのネーミング(命名)は日本語でも英語のどちらでも構いませんが、日本語 or 英語で命名するメリット・デメリットについては、下記記事をご参考下さい。
上記の命名ルールをご覧いただくとわかるように、テーブル名は基本的にすべて英語名にすることをお勧めします。そして、実はもう一つ注意すべき点があります。FabricのDataflow Gen2を使用する場合、特定の落とし穴が存在するからです。


Dataflow Gen2のクエリでは右クリック > 「ステージングを有効にする」という項目があり、この項目に✅が入っていない場合、英数字のテキストは斜体(イタリック)になります。これにより、当該クエリでステージングを行うかどうかを判断でき、作業効率が向上します。ただし、日本語や中国語(韓国語は未確認)では、文字のフォントに変化がないため、ステータスを判別することができません。これはFabricのデータ統合(Data Integration: Data Factory)チームへ報告済で優先順位の低い改善ポイントの1つですが、アルファベット以外の言語を使用する場合に発生する問題です。
なお、ステージングをONまたはOFFにする判断*4は、以下の公式ブログを参照してください。
日付テーブルの作り方
データベース(DB)を管理している場合、日付テーブルは基本的にDBソース側で作成することをお勧めします。これにより、データの一貫性やパフォーマンスが向上するからです。
日付テーブルのデータ粒度については、通常は日次ベースで作成するのが最良とされています。これは、より詳細な分析やタイムインテリジェンス機能を最大限に活用できるためです。しかし、業務要件に応じて月次ベースで作成しても特に問題はありません。月次ベースの粒度でも多くのビジネスニーズに対応できます。
詳細については、以下の「Power BIで月次分析をさらにスマートに①」で詳しく解説していますので、ぜひご参照ください。
一方で、DAXを使用して計算テーブルとして日付テーブルを作成することも可能です。この方法については、こちらの記事を参考にすると良いでしょう。
ただし、DAXで計算テーブルを作成する際にはいくつかの注意点があります。特に、FabricのPower BIで新たに登場したDirect Lakeモードは、計算列*5や計算テーブル*6に対応していません。そのため、Direct Lakeモードを使用する場合、DAXによる計算テーブルは適用できないことを理解しておく必要があります。
計算列及び計算テーブルのDirect Lakeへの搭載について、製品チーム(Analysis Services)は慎重になっています。理由として、計算列や計算テーブルは、すでに実体化されたデータに基づいて作成されるものです。一方、Direct Lakeのコンセプトは、メタデータの更新を通じて「リフレーミング」*7を行うというものです。リフレーミングでは、セマンティック・モデルの更新が瞬時に行われますが、計算列・計算テーブルの生成はその後に行われます。そのため、リフレーミングの完了から計算列・計算テーブルが作成されるまでに数分かかることがあり、エンドユーザーはその間待つ必要があります(2024年6月時点、搭載予定日は不明)。
なお、今回のテーマとかけ離れますが、リフレーミングに関する解説動画は以下が分かりやすいです。
最後に
今回はかなりマニアックな部分まで日付テーブルについて見てきました。次回はより実践的な部分に踏み込んで事例ベースで話をしていきたいと思います。
おまけ: テーブルのネーミング規則の背景
dCalendarやdProduct等のネーミング規則は、Excel Power Pivotを熱心に使っていた時代の経験が影響しています。当時、ExcelIsFunというYouTubeチャンネルを通じて、Excel BIについて多くを学びました。このチャンネルの運営者であるMikeさんは、Excelのプロフェッショナルであり、大学でビジネスアナリティクスの教授も務めています。彼はYouTubeに多くの教育動画を投稿しており、最近では登録者数が100万人を超えるなど、業界で非常に有名な存在です。彼が「DimCalendar」や「DimProduct」を「dCalendar」、「dProduct」と略して記述していたのに影響を受け、私もこのルールに従うようになりました。
ちなみに、5年前にMikeさんとやり取りをしたことがあり、その際、私がした質問を基にYouTube動画を作成してくれたのは、特に印象深い思い出です*8。
*1:YTD, MTD、前年同期等
*2:数字結果が間違って算出される可能性がある仕様i-iであり、最大限の注意が必要。セマンティックモデルをスタースキーマで構築すれば発生しないため、常にベストプラクティスを心掛けることが肝要
*3:Power BI セマンティックモデルの詳細なメタデータ情報、クエリパフォーマンス等を計測可能なツール
*4:簡単にまとめると、複雑な変換についてはステージングしたほうが良く、ジョインやメモリ消費を大量に必要としない場合はステージングを有効にしないほうが良い
*5:データモデルのテーブルに追加する列のこと
*6:DAXを使ってデータモデルに既に存在するテーブル(あるいはその列)からデータモデルに追加して使用するためのテーブル
*7:Direct Lakeのセマンティックモデルをその時点の最新のスナップショットに更新すること
*8:MAT(Moving Annual Total)数値をPower QueryでProductとMonthで作れないか、という相談だったのですが、カスタム関数で実現されていました(実際のPower BI世界ではメモリ消費が半端ないため、基本的にNG)。このリクエストは各Productに対してPower Queryで在庫回転期間を月別に計算できないかを模索していた時期であり、良き学習体験となっています