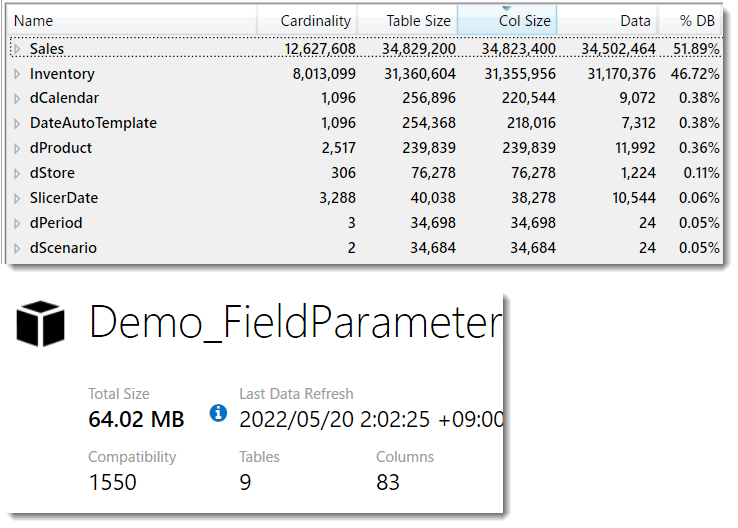
2022年5月のPower BIのアップデートで、フィールド パラメーターという機能が新たに搭載されました。この機能については、海外の人を中心に多くの人がブログやYouTubeで紹介しており、便利だろうな~と思いつつ眺めていたのですが、いざ自分で試してみるとかなり衝撃的だった。今回はこの新機能をNowとBeforeでまとめてみました。
使用データ
データソース:SQLサーバー
データベース名:Contoso Retail DW
ファクト:Sales, Inventory
ディメンション:dProduct, dStore, dCalendar
データ量:Sales(1,300万行)、Inventory(800万行)
期間:3年(日次データ)
データモデル
上記前提を基に構築された最終的なデータモデルは下図の通りになります。
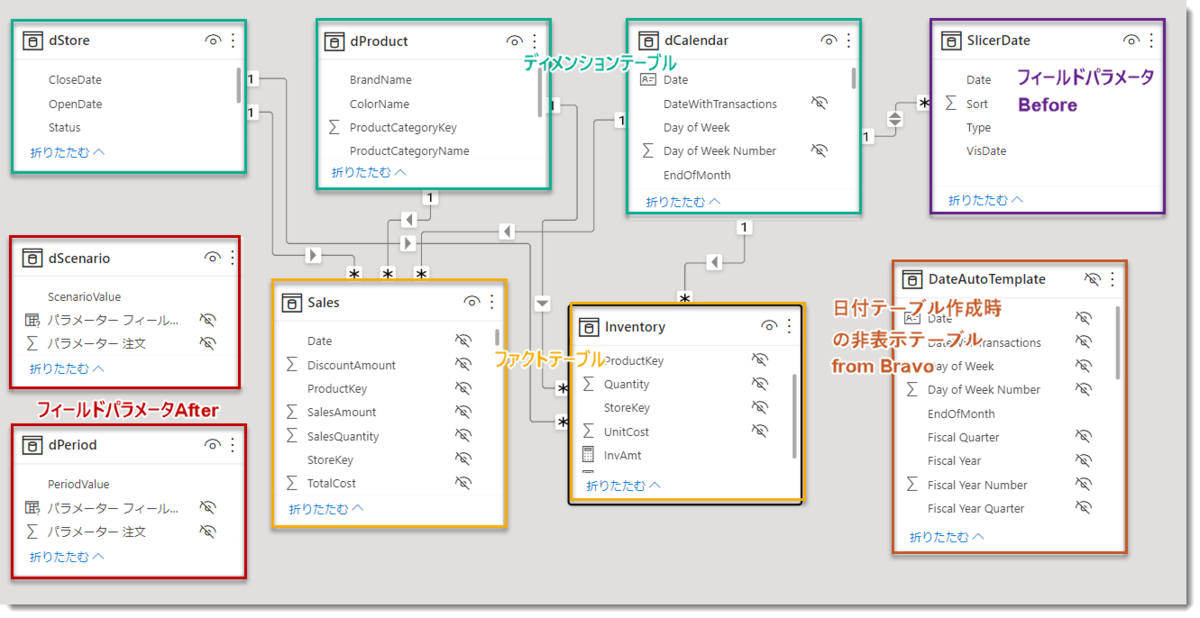
デモ用データモデルはBravoを使用し、dCalendarを構築していますが、Bravoの便利さについては、以前の記事をご参考ください。
今回のデータは主に以下のような特徴があります。
- ファクトテーブルは在庫・売上の2つ
- Bravoを使用してdCalendar及びTime Intelligence関数を自動構築
- フィールド パラメーターは2種類作っており、1つはメジャー別シナリオ、もう一つは時系列の区間別シナリオ(※詳細は後述)
- フィールド パラメーターを使う前の構築手法も紹介
フィールド パラメーター(Now)
まずは簡単に今回登場したフィールド パラメーターですが、端的に概念についていえば、下記公式ドキュメントの冒頭文にあります通り、
分析されるメジャーまたはディメンションを動的に変更
できる機能となります。
図説したほうが分かりやすいと思いますので、例えば以下のようなシナリオがこれに当てはまります。
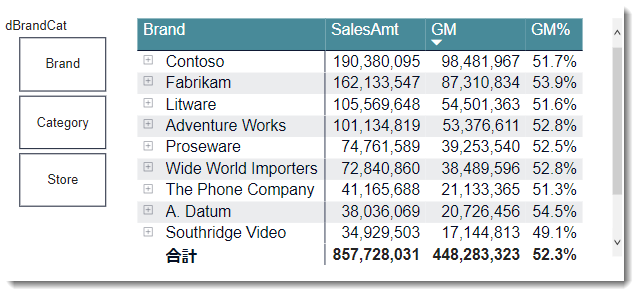
ブランド・カテゴリー別に切り替え
フィールド パラメーターを作ると、今まで切り替えが難しかったBrandとCategoryによる売上を可視化することが非常に容易になりました。
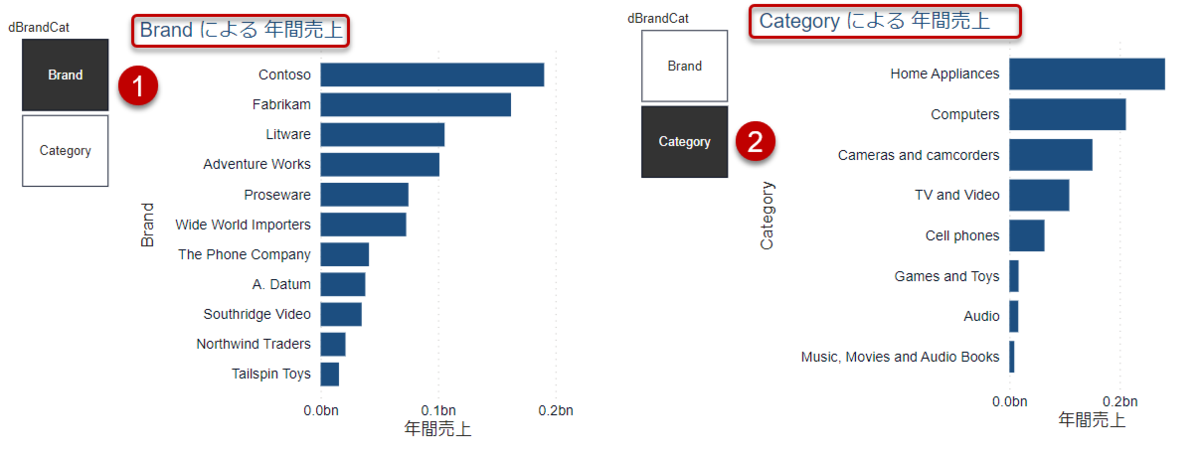
なお、BrandとCategoryは同じディメンションテーブルdProductに入っていますが、以下のように、異なるテーブルからの組み合わせもできるようになり、
あらゆる切り口(ディメンション)から分析結果を表示
することができるようになりました

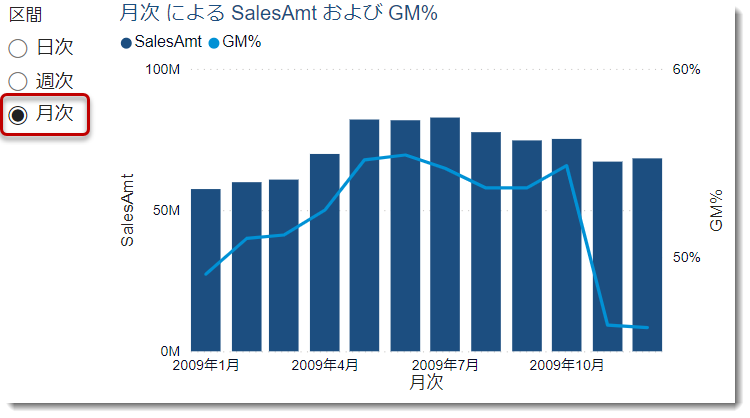
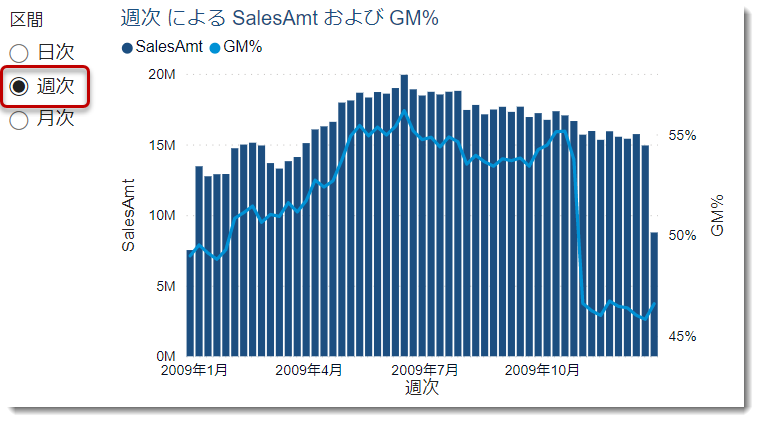
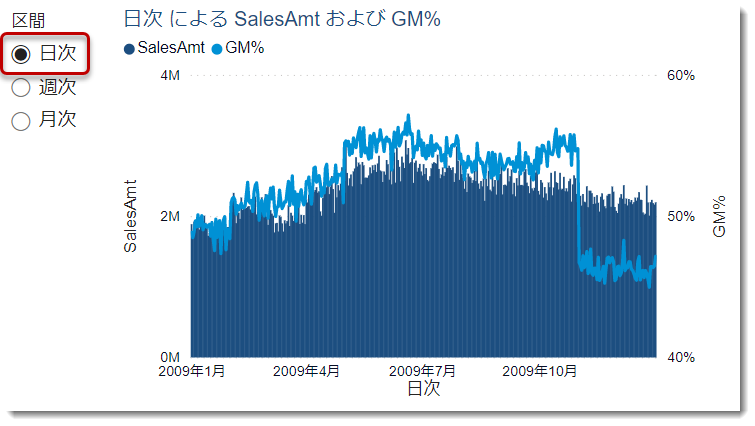
年月・週・日別に切り替え
これにより、時系列の粒度を変更して、短期~長期的なトレンドを把握することが容易になりました。
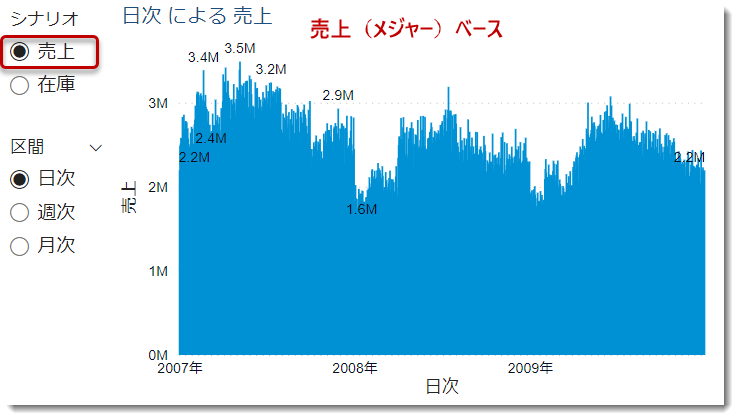
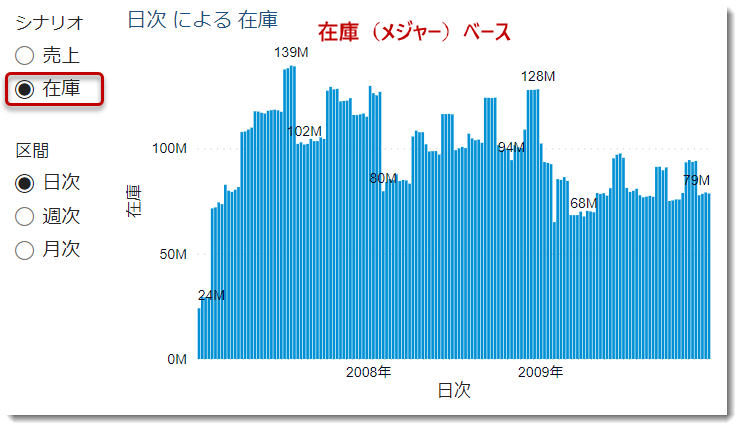
メジャー別に切り替え
マトリックスビジュアル
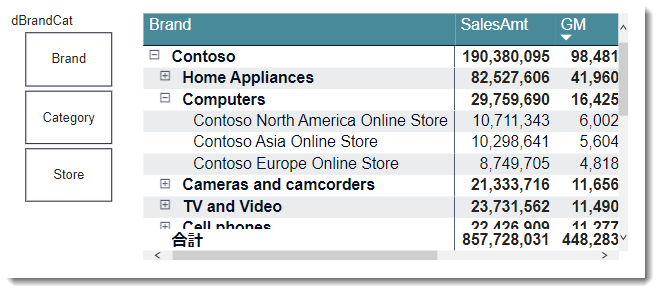
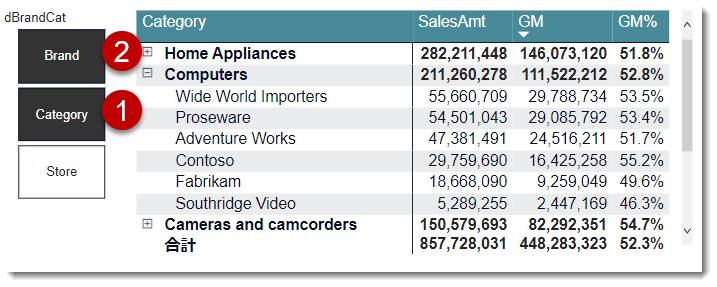
マトリックスビジュアルは階層別に集計値を分析できるのが特徴ですが、dBrandCatを使うと下図のように、+ボタンが付いた状態で階層化されています。
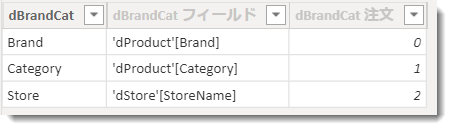
dBrandCatはBrand、Category、Storeという順番で並んでおり、これはフィールド パラメーターのテーブルから確認できます。
+ボタンを広げると、予想通りの結果が返ってきます。
一方、スライサーを1つだけ選んだ場合、上記グラフ(ランキングチャート)でも紹介しました通り、1つの切り口だけの結果を返します。
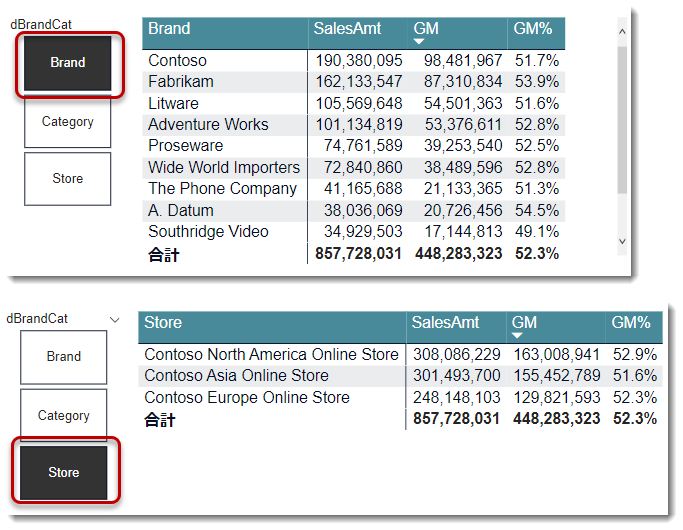
ここで、例えば、下記①~②の順番でスライサー項目を複数選択(Ctrlを押しながらクリック)すると、選んだ順番の切り口が一番トップに出てきます。
同様に、例えば下記のように、Store > Categoryの順番で選択すると、上図とは異なる切り口で分析ができるようになります。

マトリックスは詳細分析に際して効果を発揮しますので、このやり方は覚えておくと便利だと思います。なお、何度も複数選択することがないよう、選択された状態をブックマーク機能で覚えさせておけば、初期化という形で手動でこれを何度も再現する必要がなくなります。
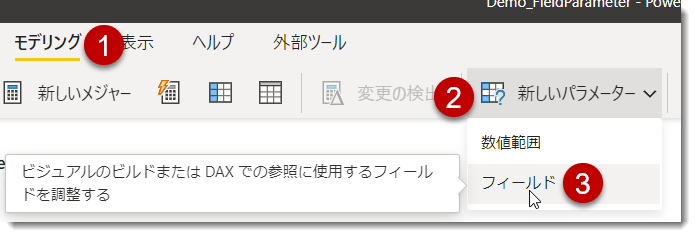
フィールド パラメーターの作り方
上記公式Docsを参考にしたほうが早いかもしれませんが、さくっと構築してみます。
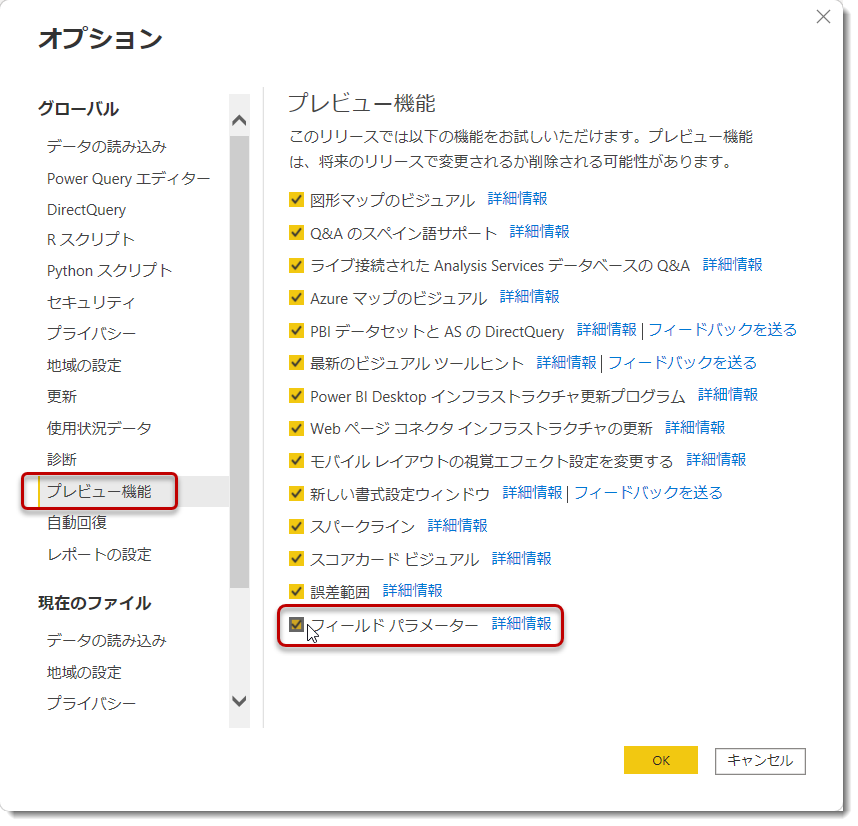
- フィールド パラメーターを有効にします
ファイル > オプションと設定 > プレビュー機能 > フィールド パラメーターに✅
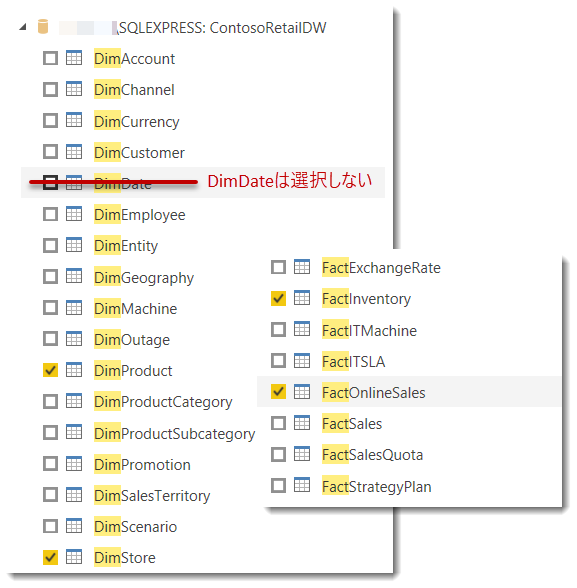
- データソースから対象のデータを取得。なお、DimDate(日付テーブル)も取得できますが、Bravoを使うため、ここでは選択しない
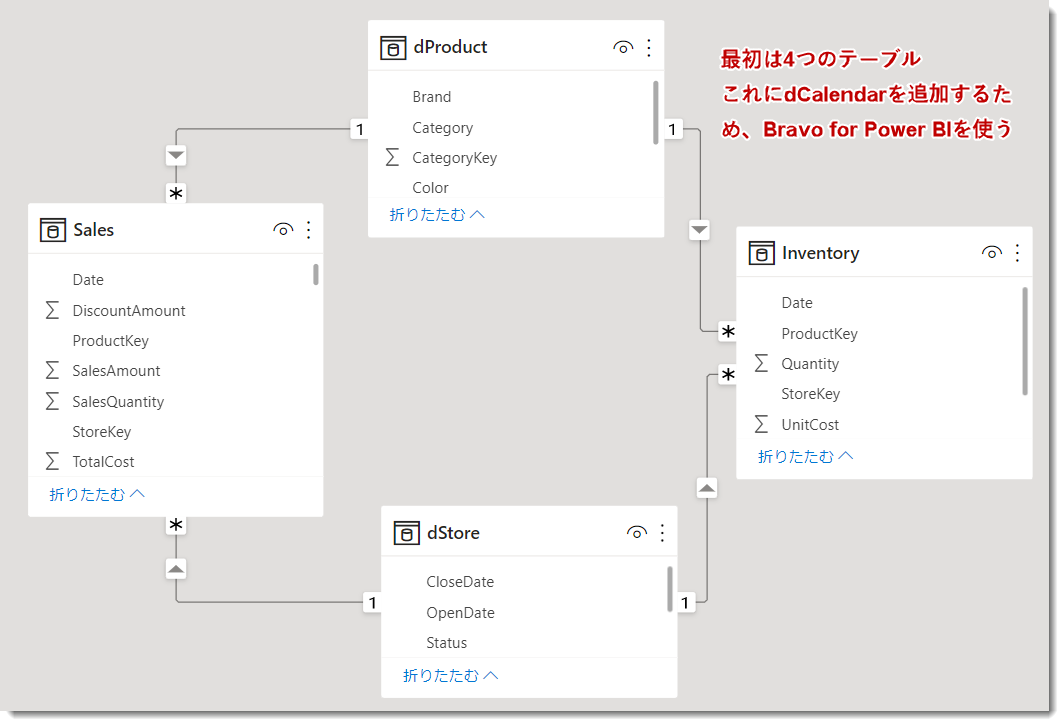
- データを読み込み、データモデルを構築(DimはDimensionを意味しますが、便宜上、dに変更し、DimProduct→dProduct、FactInventory→Inventory等のように名称を変更)
- DAXで以下4つのベースメジャーを作る
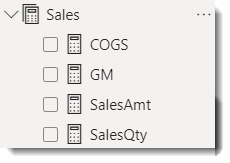
ここでメジャーを作る理由は、Bravoでは自動的にTime Intelligenceメジャーを構築してくれることで、その前提条件がこれらのようなベースメジャーが必要であるわけです。
※ 重要:在庫数・在庫高といったメジャーはdCalendarがあって初めて作ることができるため、Bravoのお世話にはなりません - Bravoを立ち上げ、dCalendarを作り、リレーションシップを構築
ここでの留意点として、dCalendarは月曜スタート、かつ、Bravoで自動生成されたDateAutoTemplate(非表示日付テーブル)の中に、Start of Monthという列を追加しておくことです(こちらも詳細は上記ブログに記載済、フィールド パラメーターで必要な列)。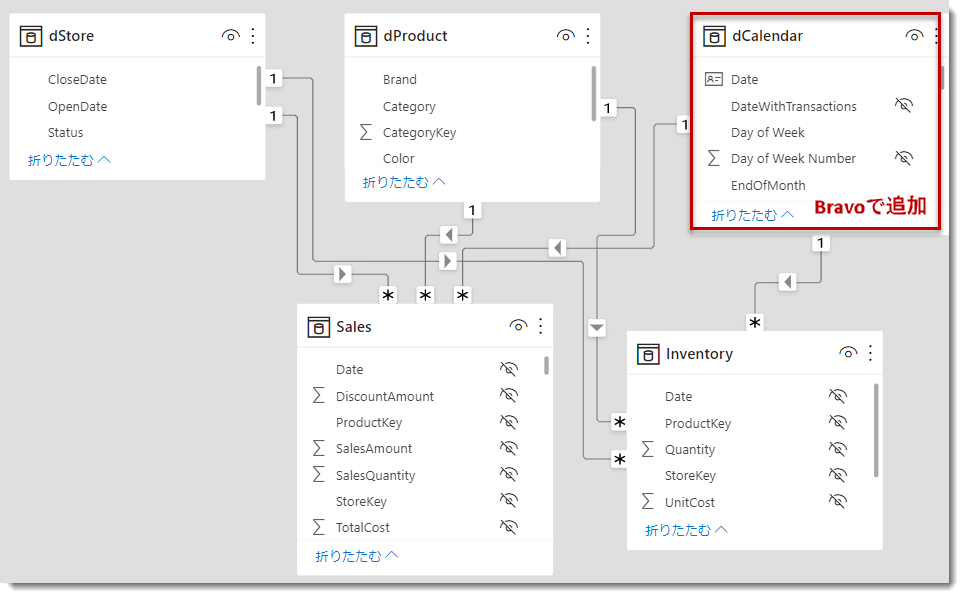
なお、BravoよりdCalendarを追加する方法は下記ブログにて詳細に解説していますので、そちらをご参照ください。
DateAutoTemplateテーブル
- 在庫メジャーを構築
在庫数(InvQty)
在庫高(InvAmt)
- dCalendarにStart of Weekという計算列を追加(下図)
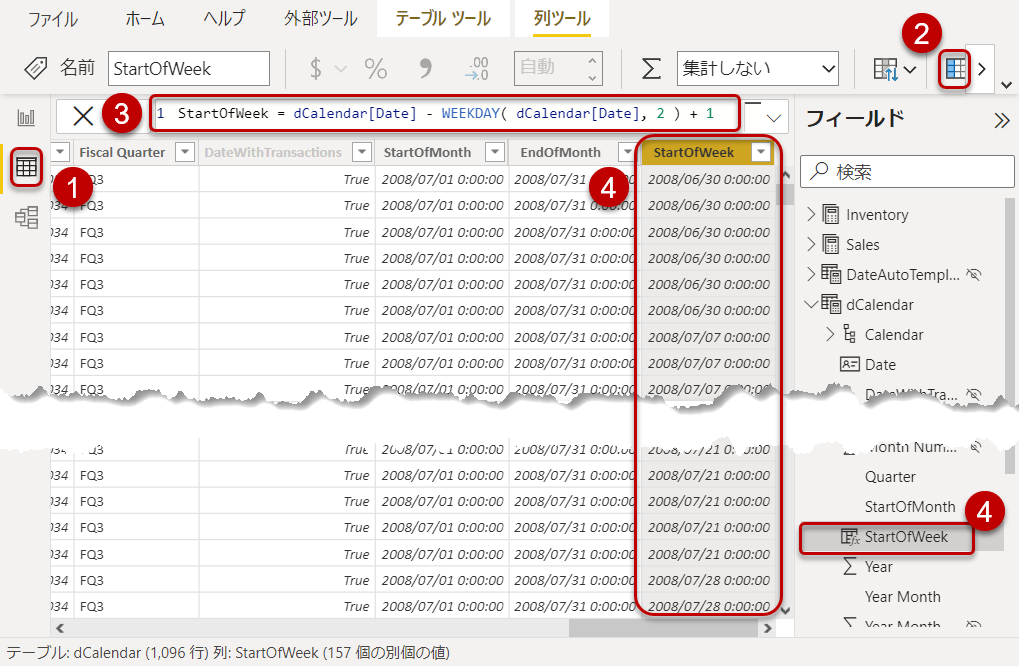
- データモデルが構築できたので、以下のようにフィールド パラメーターを挿入
パラメーターの設定画面が出現しますので、
④ フィールド パラメーターのテーブル名をdPeriodに設定
⑤ dCalendarからStart of Month, Start of Week, Dateを選択
し、作成をクリック
- 計算テーブルが作成され、dPeriodはスライサーとしてレポート内に挿入される

{}はテーブルコンストラクターと言われるもので、テーブルを構築するものとなります。{ (), (), () }のように、{}の中は行(タップル)と言われるもので、DAXで計算テーブルを作る際によく使われる書き方ですので、覚えておくと良いでしょう - このままでは分かりにくいので、以下のように名称を変更
NAMEOF等のDAX関数については、SQLBI等から詳細が出ると思いますので、詳細は省きますが、DAX Guideからその概要を知ることができます。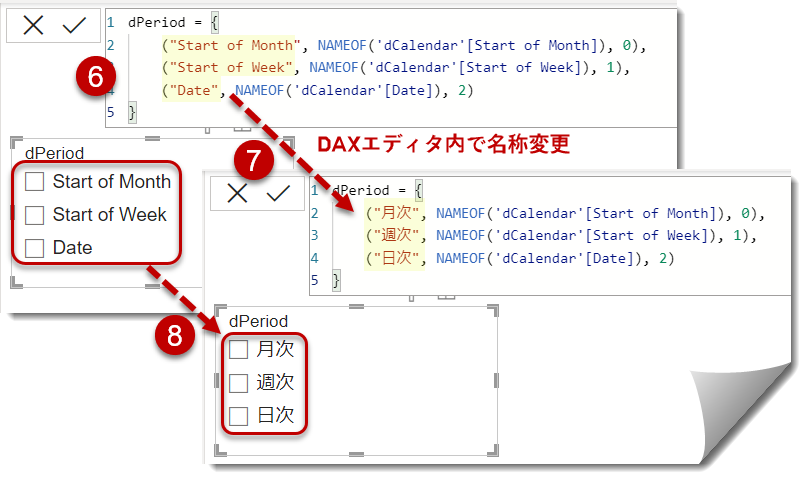
ちなみに、データビューから見ると、dPeriodをソートする列が[dPeriod 注文]という列名(非表示)で出現していますが、オリジナルの英語がOrderとなっていますので、翻訳ミスとなります(この辺は新機能が登場する際のご愛敬ですので、そのうち直ると思います)。

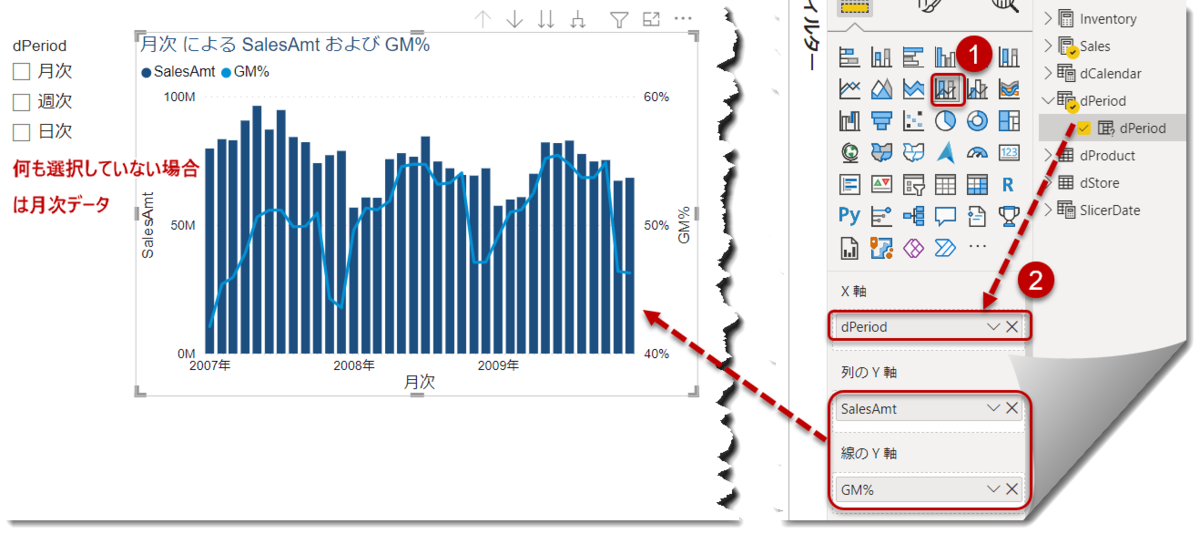
- ここから、以下のようにチャートを作る(例はコンボチャート)
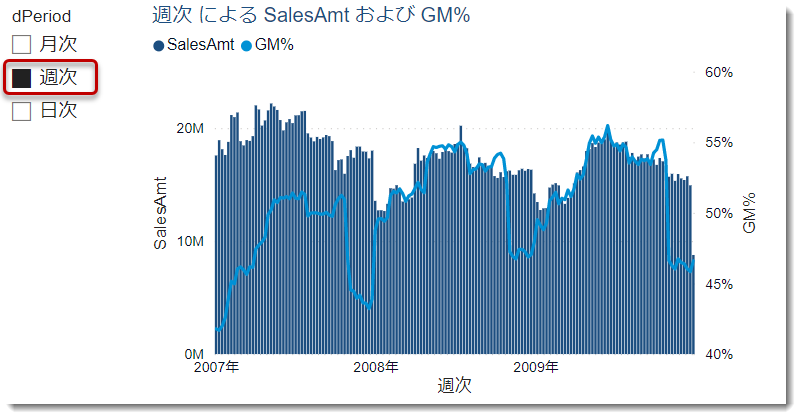
- 週次をクリックすると週ベースで表示される
- 同じく、日次にすると更に細かく表示される
今回のデータは3年分の量となりますので、日次ベースのデータはもっと年月で絞って、もっと短い期間で使用したりしたほうが良いと思います(下図)。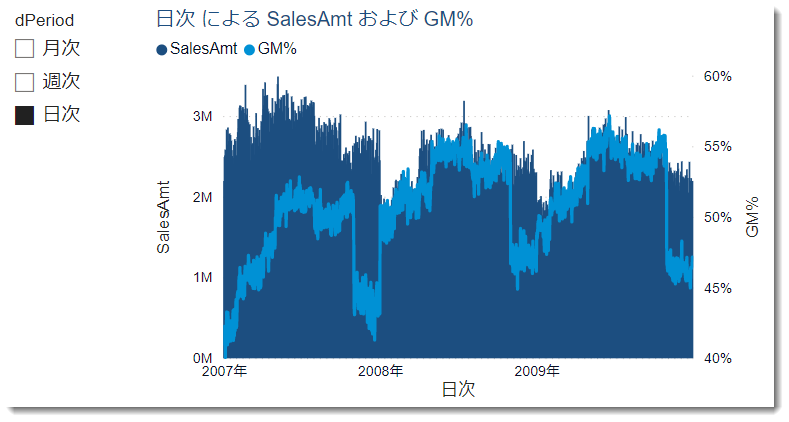
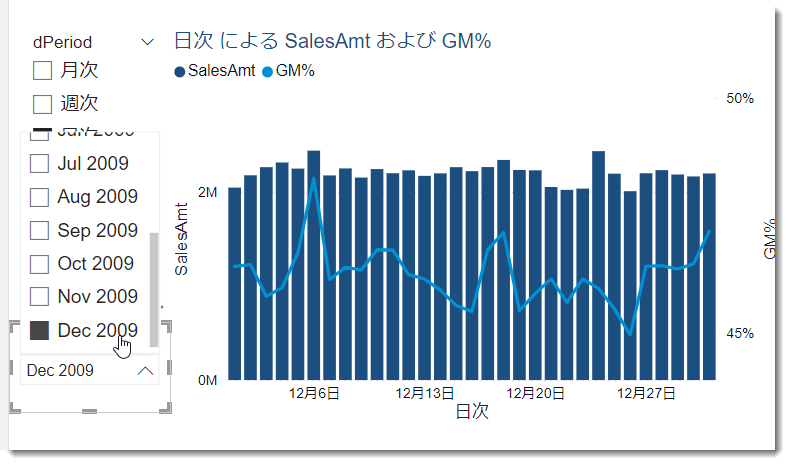
- その他の切り口でフィールド パラメーターでスライサーを追加していく
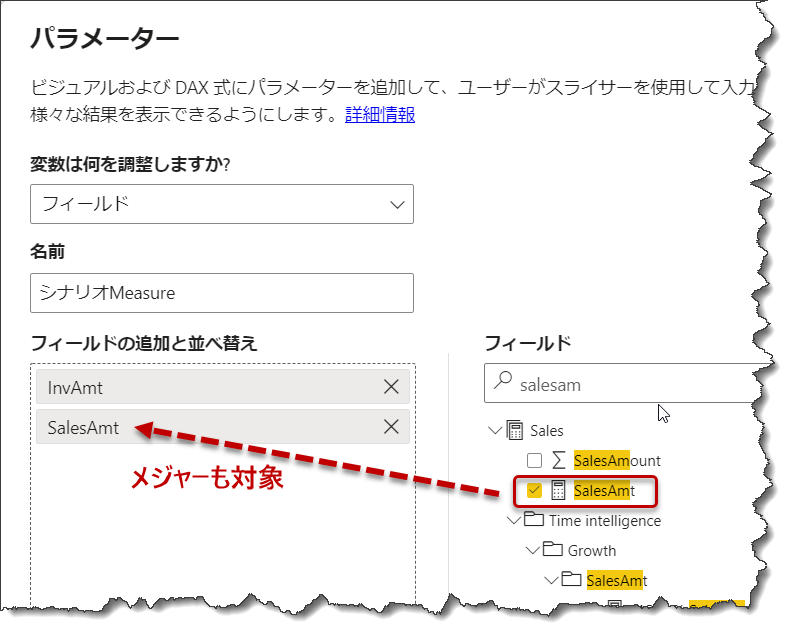
フィールド パラメーターは作るごとに、テーブルが1つ増えますので、作りすぎに注意ですが、パラメーターに項目を追加する際、
列だけでなく、メジャーも対象になる
ということを認識しておいたほうが良いと思います(下図)。
解説が長くなりましたが、慣れると5分程度でフィールド パラメーターを作って、様々な切り口で分析を行うことができるようになります。現在ニーズはなくとも、Power BIでレポートをどんどん作っていくと、今後必ずどこかのタイミングで出てくるトピックになると思いますので、覚えておいて損はないと思います。
このように、フィールド パラメーターは非常に便利でパワフルな分析を可能にしますが、これを以前実現しようと思ったら、結構大変な準備が必要でした。もはやニーズはないのですが、ご参考のため、以前のやり方も紹介しておきます。
以前のやり方(Before)
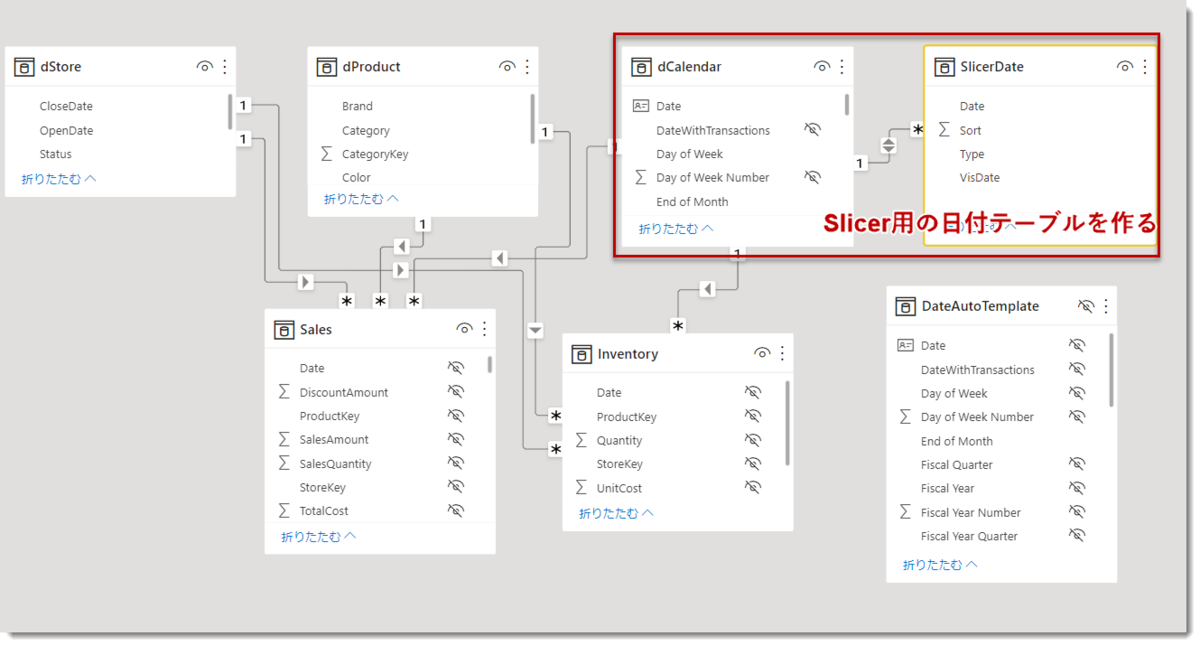
上記、「月次 > 週次 > 日次」別にボタンで切り替えたい場合のやり方を紹介します。まずは、スライサー用の日付テーブルを作り、dCalendarとリレーションシップを構築します。
SlicerDateという計算テーブルですが、以下のDAXで作ります。
SlicerDate(計算テーブル)
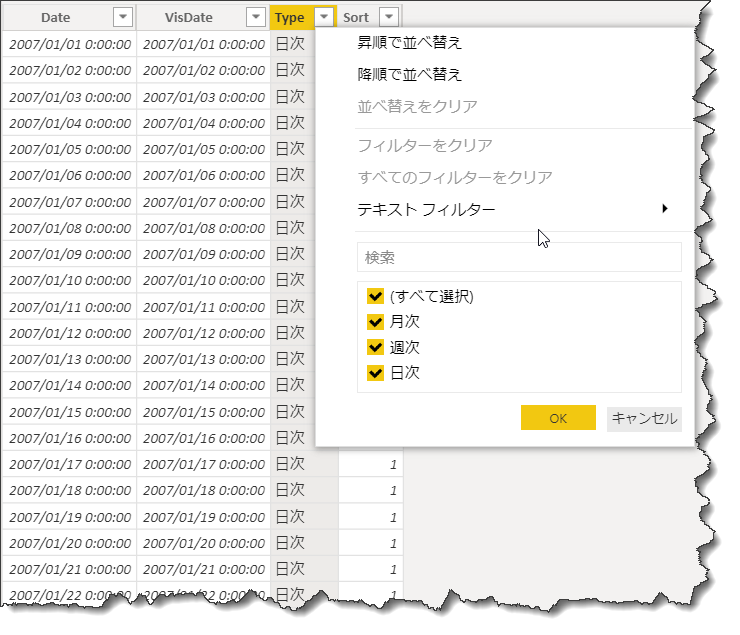
ポイントは、Typeという列で、「月次 > 週次 > 日次」という粒度で切り替えができるよう、3つの変数(_daily, _weekly, _monthly)を合体させた計算テーブルを作ることです。この後、dCalendarとリレーションを構築しますが、下図の通り、
双方向、かつ、SlicerDate(*)-dCalendar(1)
というリレーションシップで設定してあげる必要があります。

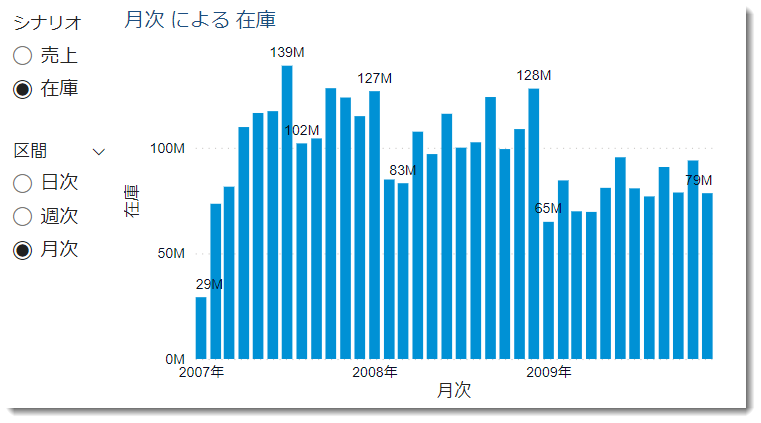
Power BIのデータモデリングのベストプラクティスに反するモデル構築ですが、例外の1つとして考えてください。ここまで準備できれば、あとは可視化するだけ。下図のように、SlicerDateのVisDateをX軸にドラッグ&ドロップし、SalesAmt(売上高)をY軸に持っていき、同じくSlicerDateにあるTypeをSlicerとして設定すると、月次売上が可視化できるようになります。
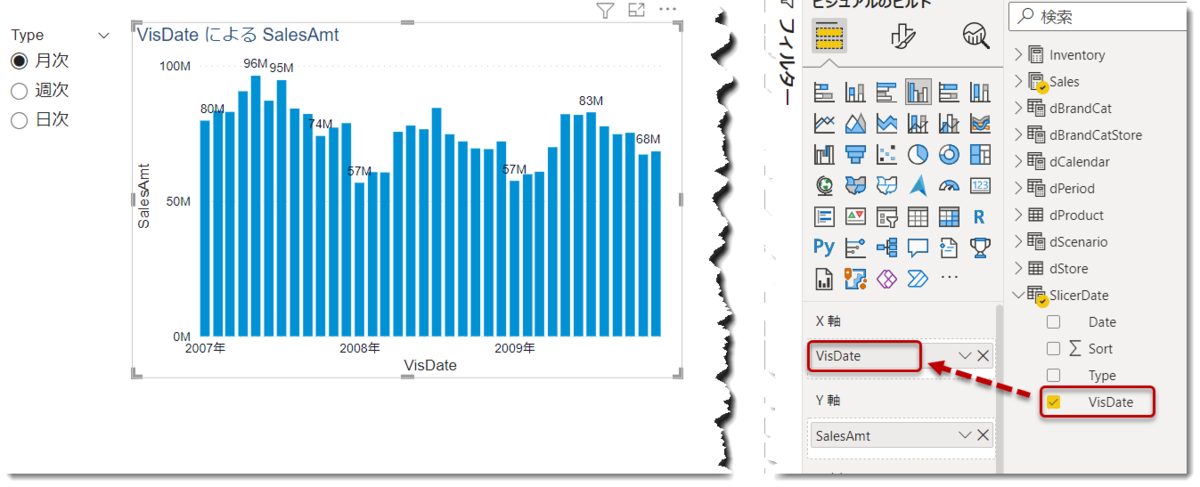
Type = 週次を選択すると、週当たりの売上。

Type = 日次を選択すると、1日あたりの売上。

このように、以前は難解なDAX式を含む計算テーブルを作り、X軸にdCalendar[Date]ではなく、VisDate[Date]を入れる必要がありました。
なお、この構築法にはいくつか問題がありますが、主に以下3つが考えられます。
- タイトルが自動的に変化しない
- Time Intelligence関数が使用できない
- パフォーマンス上の懸念
1については以下のように、Nowは選択したPeriodの項目名が選択項目に合わせてダイナミックに変更されています。
Now(フィールド パラメーター)
Before(タイトルやX軸の名前は変化なし)
2はもっと深刻で、通常とは異なるデータモデルを構築してしまったがゆえに、本来であれば可視化が簡単な年次総計売上(MAT SalesAmt)といったメジャーが計算できなくなってしまいます。
Now(フィールド パラメーター)時のMAT SalesAmt
Before時のMAT SalesAmt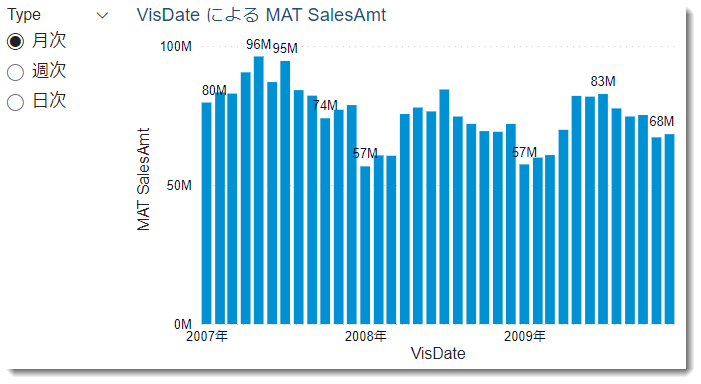
ご覧の通り、Beforeではデータモデルが変わってしまったため、Time Intelligence関数が使えず、MAT SalesAmtは月次売上と同じ結果となって算出されています。DAXをもう少し深く見ていけば複雑な式で正しいMAT SalesAmtを正しく定義することも可能かもしれませんが、シンプルなものを敢えて複雑にしてまで時間を掛ける必要があるかどうか、以前はこの部分におけるトレードオフが重要でした。
最後3のパフォーマンスですが、以下詳細を解説しています。
クエリパフォーマンス
BeforeとNowの紹介をしてきましたが、パフォーマンスについて見てみたいと思います。Beforeではデータモデルが複雑になること(時系列のケース)や、メジャー別に結果を見た場合にかなりの準備(下記解説する書式設定等)が必要となりますが、以下のようなケースを考えてみます。
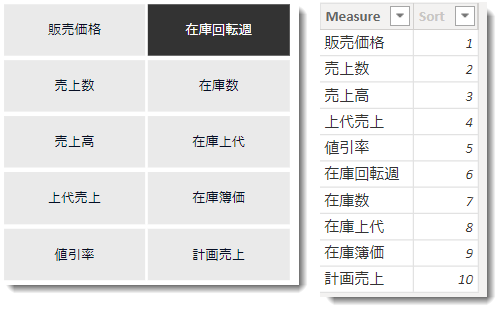
これらの指標は全てメジャーをベースとしており、以下のDAX式で1つのメジャーを算出しています。
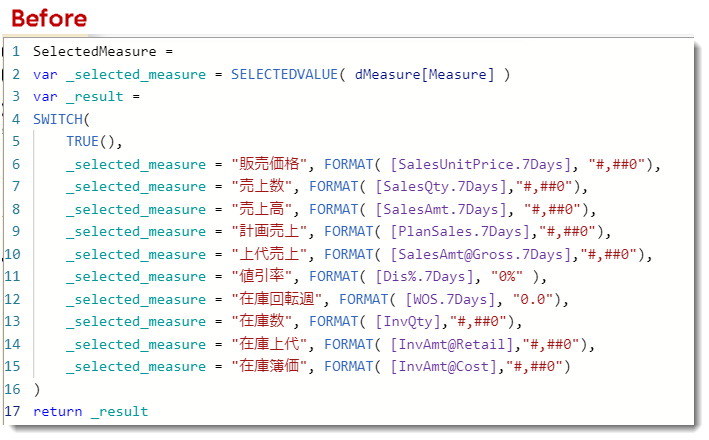
これに対して、Nowのフィールド パラメーターはご紹介した通り、簡単に作ることができ、パラメーターの設定を行えば下記のように計算テーブルが作られます。

マトリックスビジュアルを作り、Power BIのパフォーマンス アナライザーからパフォーマンスを見ると、以下のようになりました。

本来はこれらのクエリをコピーし、DAX Studioでクエリのパフォーマンスチェックを行うのですが、DAX Studioがまだフィールド パラメーターに対応していないのか、エラーが発生してしまうため、今回は上記の結果だけで見ることにしました。
※どうやらエラーではなく、フィールド パラメーターで作った項目で算出された結果をパフォーマンス アナライザーを計測すると、下図のように、強制的に2つのクエリが作られるようです(表示用のフィールドクエリが余計に作られる)。
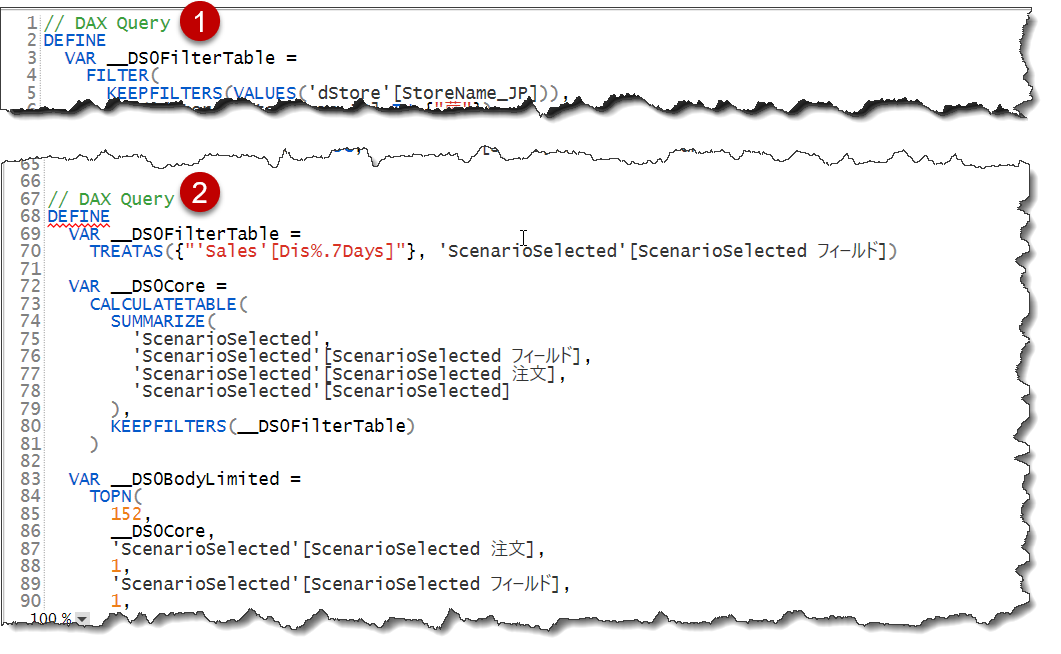
どうやら2段階に分けてクエリが作られ、最終的にビジュアルに結果が反映されるようです。そして、パフォーマンスについて結果から言いますと、やはりフィールド パラメーター(Now)のほうが圧倒的にパフォーマンスが高いようです。なお、Beforeのやり方では、FORMAT関数を使用しないと正しい書式として表示できないのもマイナスポイントの1つとなります。CALCULATION GROUPSを使えば、FormatStringをダイナミックに設定できるのですが、今回のブログの範疇を超えますので、説明は省きます。
興味ある方は、以下SQLBIが詳細に解説したものがありますので、ご参考下さい。
そして、フィールド パラメーターについての詳細がSQLBIから出ましたので、こちらも共有しておきます。
まとめ
- フィールド パラメーターはあらゆる切り口から分析を可能にする
- Time Intelligence関数も問題なく使用可能(Beforeではかなり厄介)
- パフォーマンスの向上等、試せばいろんな使い道が見つかる可能性を秘めている