前回記事の「PBI合計値の不一致」で使用したデモデータですが、全てPower BI Desktopにある「データの入力」機能を使用したものとなります。
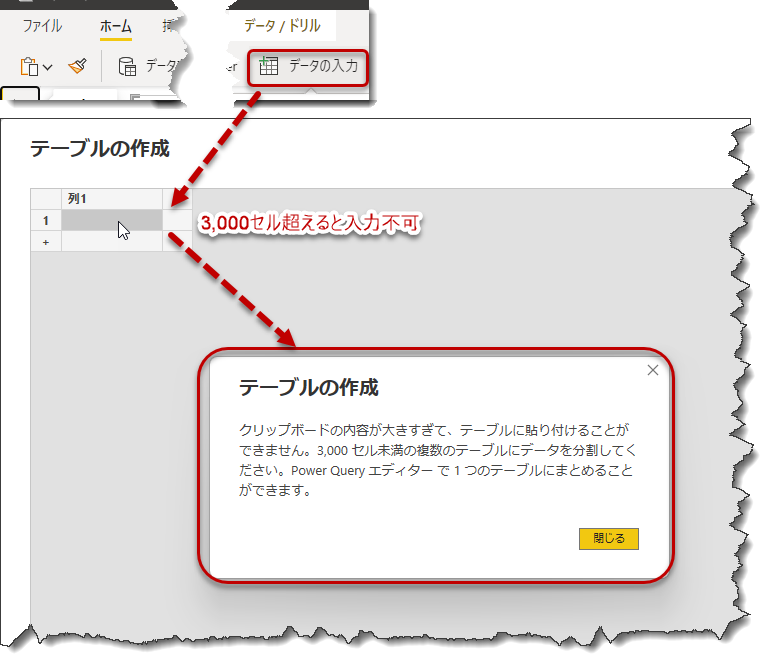
データソースはデータベースやExcel/CSVではなく、Mクエリでマニュアル入力されたものとなります。マニュアル入力する場合、計3,000セルという制限が存在するため、実際のサンプルデータはSQLサーバー(ContosoRetailDW)からDAX Studioを使ってランダムに抽出したものとなります。今回はそのやり方について簡潔に紹介したいと思います。
※ オリジナルデータはサイズが大きいため、今回は10万行にまでデータを減らしたpbixファイルを用意しました。一番下からダウンロードできます。本記事はオリジナルデータをベースに進めていきます。
データソース
作り方を紹介する前に、前提条件として以下のことを認識しておく必要があります。
- SQLサーバーに限らず、データをPower BI Desktopに読み込めるソースであれば何でもOK(サンプルファイルを作るためのデータ量がそこそこあること)
- DAX Studioがインストールされていること
- DAX Studioを使用するため、データモデルにデータが読み込まれた状態となっていること
- DAXクエリを使用してサンプルデータを作っていく
これを前提条件とし、前回記事のデータモデルの完全版からサンプルデータのみを抽出してみます。なお、Power BIで構築されたデータモデルの情報は以下の通りです。
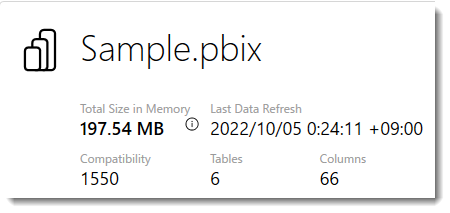
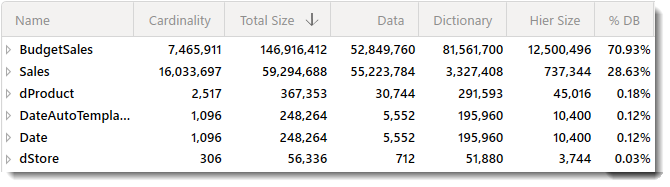
この記事を書くまで気づきませんでしたが、テーブル単位のCardinality(データ濃度)はSalesのほうが高い(1,600万行)ですが、BudgetSalesでは746万行と行数ベースで少ないにも関わらず、データベースのサイズ(% DB)は全体の70.93%とデータモデルのサイズの殆どを占めることが分かりました。
テーブルを広げ中身についてもう少し細かく見ると、BudgetSalesではGrossMarginQuota列とSalesAmountQuota列のCardinality(ユニークレコードとなっている行数)が非常に高くなっていることが判明しました(下図赤枠)。

ユニークなレコードを持つ行数が多いほど、データモデルのサイズは肥大化する
ということを確認できた瞬間でした。最後にリレーションシップですが、前回の記事と同じく以下の通りです。
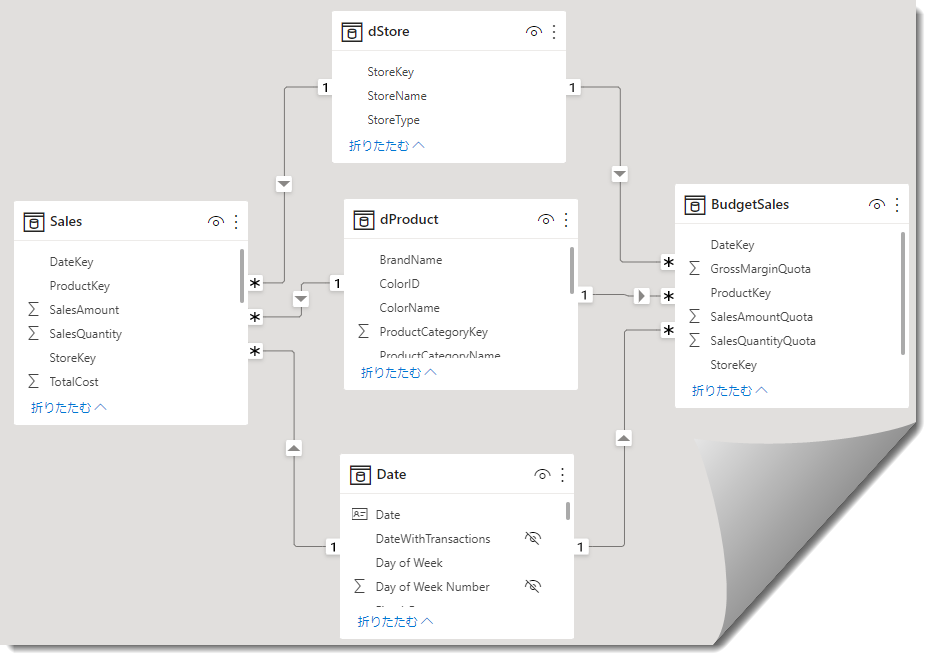
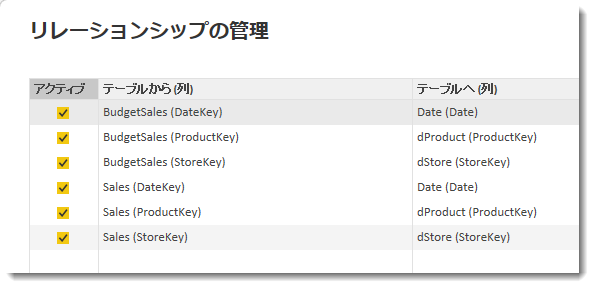
ここで重要なことは、メジャーはあってもなくてもよいのですが、スタースキーマベースのデータモデル(リレーションシップ)が完成していることです。
マスタの抽出
ここからDAX Studioで当該モデルのAnalysis Servicesインスタンスに繋げ、マニュアルで入力ができるデータを抽出していきます。
- (当該データモデルが入っているPower BI Desktopより)外部ツール > DAX Studio

- Advanced > View Metrics > TablesよりdProductを広げます
これでdProductの列のカーディナリティを確認できるようになりましたが、ProductKeyとProductNameがテーブルのカーディナリティと同じ2,517となっていることが分かります
列のカーディナリティがテーブルのそれと同じということは、その列はユニークなレコードで構成されていることを意味し、PrimaryKey(主キー)である可能性が高いことを意味します。よって、1列で2,517行もあること、そして他の列全てを含めると11列ありますので、単純計算すると2,517行×11列=27,687セルも存在することになり、2,999セルまでしかマニュアルで入力ができない「データの入力」を使用できないことになります。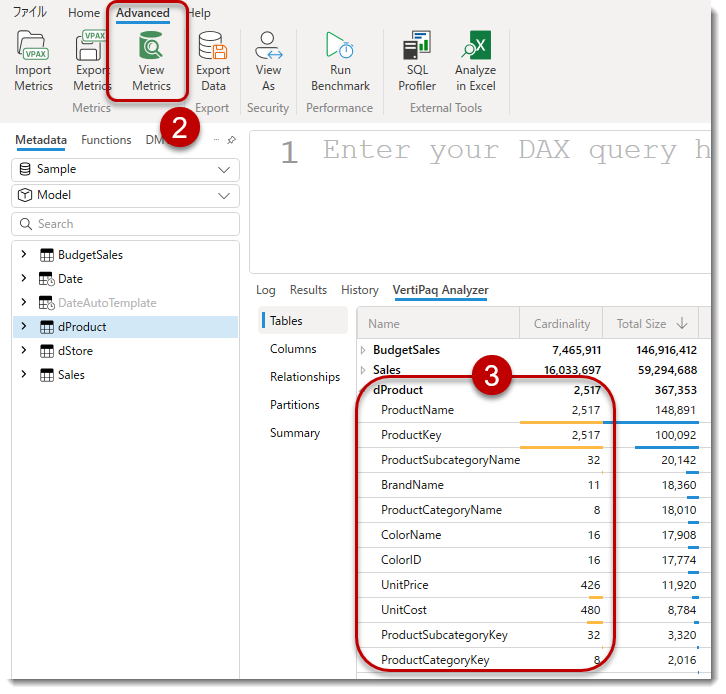
-
ProductCategoryName(製品カテゴリー名)からComputersのみを抽出
実はデモでは製品カテゴリー名のComputersしか使っておらず、列も4列のみでした(下図)。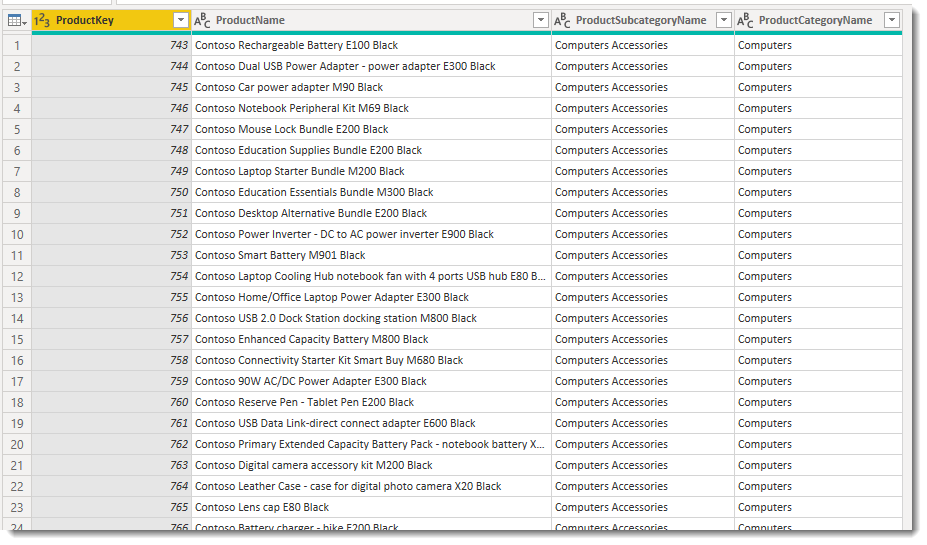
これを抽出するため、DAX Studioに戻り、以下の構文を記述し、F5を押します。
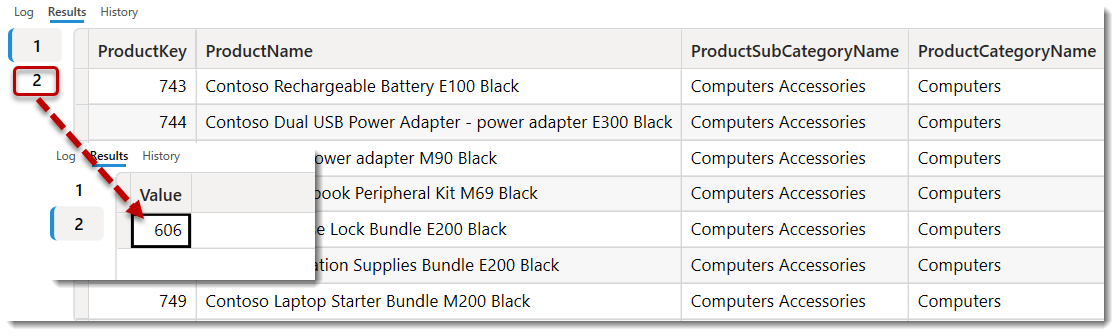
EVALUATEはDAX Studioでテーブルクエリを表示するために必要なステートメントで、EVALUATE + テーブル名(or列名)でテーブルを表示させることができます。今回の場合、EVALUATEが2つありますので、返されたクエリも上図の通り、2つとなります。
1つめのEVALUATEは、CALCULATETABLEを使用し、dProduct[ProductCategoryName] = Computersと、Computersという項目でフィルターを行い、その後SELECTCOLUMNSを使って必要な列だけを選択した結果となります。
2つめのEVALUATEはこのテーブルの行数をカウントしたものであり、上図によると合計606行(全2,517行のうち)あることが分かりました。これにより、604行 × 4列 = 2,424となりましたので、Power BIの「データの入力」へマニュアルでインプットすることができそうです。 - DAX Studioからこの結果をコピー
① 最初のEVALUATEのDAX構文をハイライト
② Homeを選択
③ この部分のアイコンを選択
④ Clipboardを選択
⑤ Runをクリック
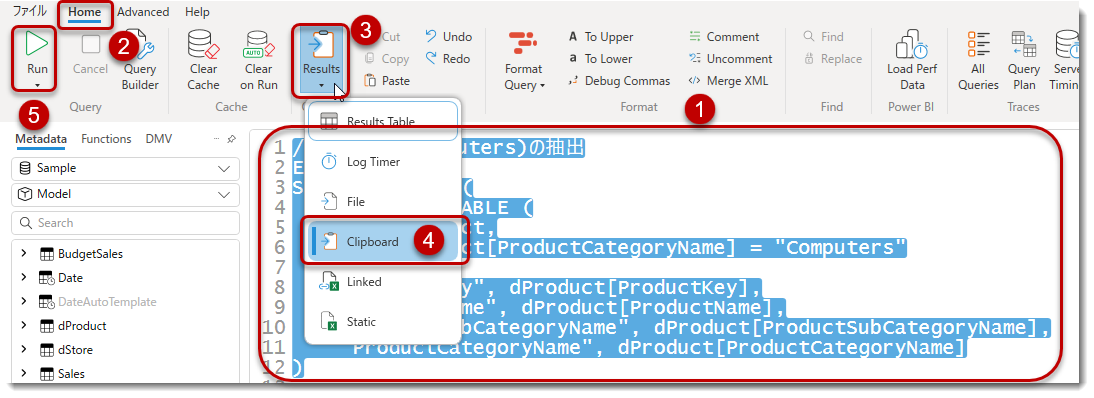
これでこのDAXクエリで生成されたデータをクリップボードにコピーすることができました。 - Power BI Desktopを新たに立ち上げ、以下のように実行
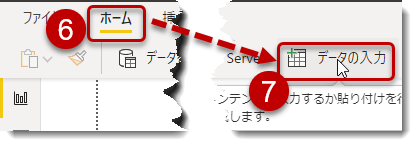
⑥ ホームより
⑦ データの入力をクリック
⑧ Ctrl + Vで張り付け
⑨ クエリ名を変更
⑩ 読み込みをクリック
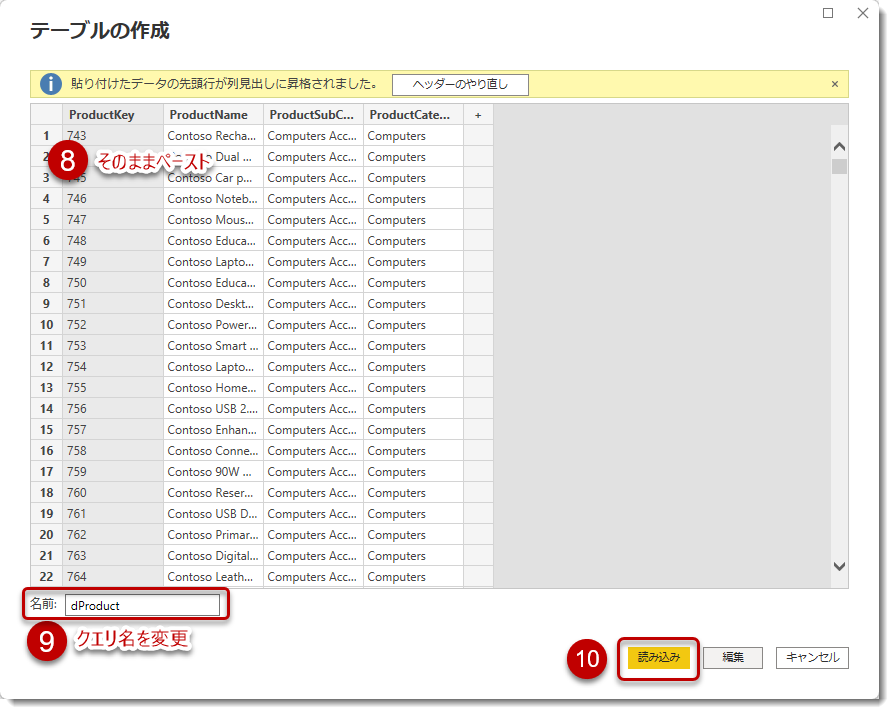
これでマスタ(ディメンションテーブル)の1つが完成しましたので、他のマスタについても同じようにやっていきます(中略)。
ファクトの抽出
今度はファクトテーブル(SalesやBudgetSales)を抽出していきます。ディメンションテーブルと異なるのは、ファクトテーブルでは時系列データになるため、年月別にどうやってバランスよくデータを抽出できるかどうかになります。
なお、抽出前に確認していますが、オリジナルのデータモデルでは行数こそ多かったものの、列数はSales、BudgetSalesともに6列でしたので、499行 × 6列 = 2,994セルとなります。よって、DAX式は以下のようになります。
-
ファクトテーブルの抽出DAX
SAMPLEというDAX関数(Iterator関数)が良い感じに母集団(Sales: 1,600万行、BudgetSales: 746万行 )の中から、どちらも499行だけ抽出してきてくれます。SAMPLE関数はIterator関数であり、SalesやBudgetSalesはどちらもN側、Dateは1側ですので、RELATED関数を使用して年月(Year Month Number)で並び替え(ASC: 昇順)を実現できるようにしています。
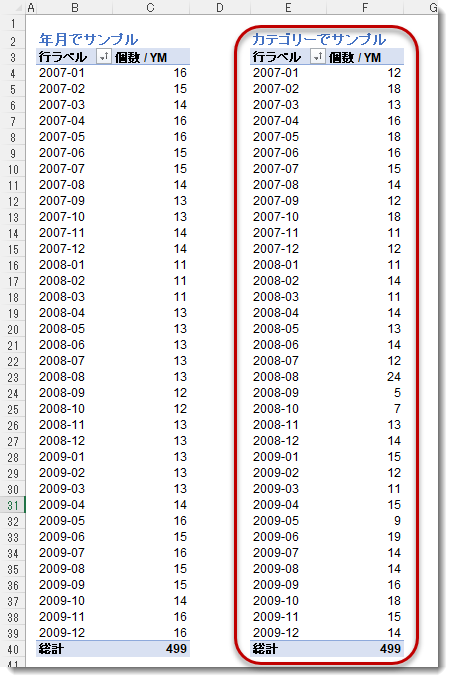
なお、RELATEDを使わず、Sales[DateKey]をそのままパラメータとして使ってもまったく問題ないのですが、RELATEDを使用すれば例えばRELATED('Date'[Year Month Number])をRELATED ( 'dProduct'[ProductCategoryName] )に変更することもできます。この場合、サンプルサイズは依然として499行になりますが、前者は年月ベースでサンプルデータを抽出してくるのに対して、後者はカテゴリーベースで抽出してくるようになります。従って、年月別に見た場合、後者のほうが年月で見た場合、データの分布が不均一になる可能性があります(下図赤枠)。
SAMPLEの詳細についてはDAX Guideを参考にして頂きたいのですが、抜粋すると以下が構文となります。

念のため、日本語訳は以下の通り。
- 抽出結果の確認

あとは先程と同じように、Power BI Desktopの「データの入力」にペーストしてあげれば以下のようにSalesテーブルのサンプルデータの完成です。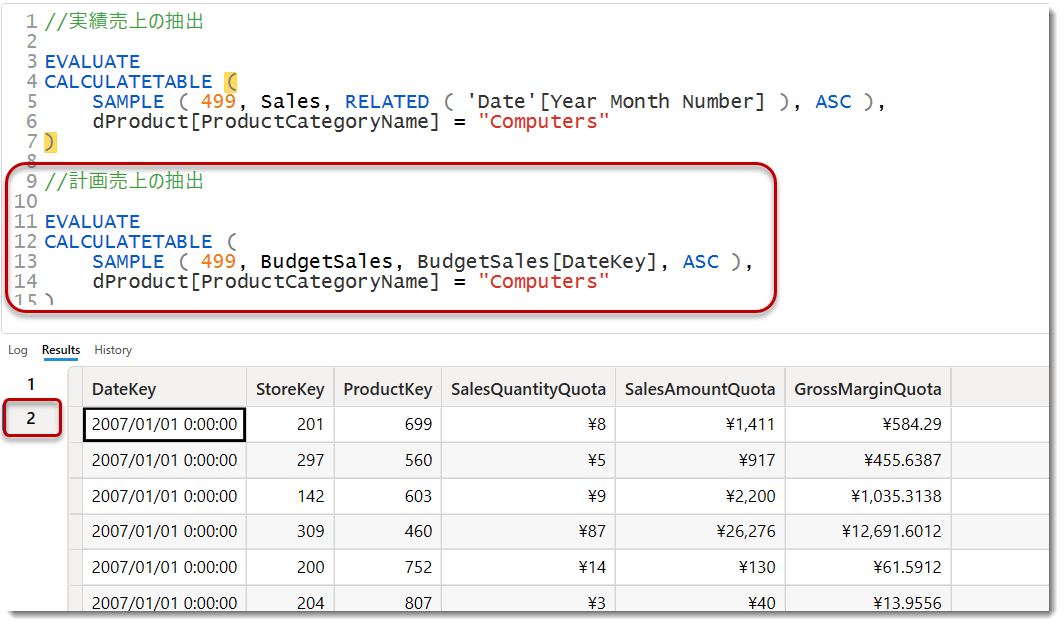

おまけ
上記ピボットはExcelで実現していますが、以下の構文を使用すればDAX Studioでも実現することができます。
-
年月別にサンプル数をカウント
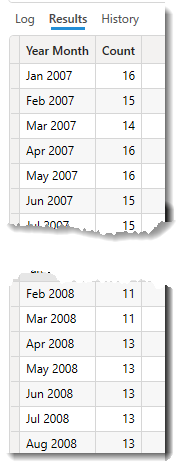
サンプルとは言え、実務上のデータは使用しにくいですが、Power Queryから外部データソースに参照させず、Power BI Desktopだけでデモ用ファイルを作りたい場合に活用してみてはいかがでしょうか。
- ダウンロード
>>サンプルデータ(10万行のみ)