データフローのシリーズは前回に続き、もう少し続きます。データフローはPower BI Pro、もしくはPremium(PPC、もしくはPPU*1)でしか使えませんので、通常よりも追加コストが掛かってしまいます。そこで今回はPower BI Proだけで運用する場合のやり方を紹介したいと思います。なお、現在はPower BI FreeからPower BI Proへのトライアル(60日間有効)を行おうとすると、自動的にPremium Per Userの機能も付随された状態となりますので、本記事は毎月Power BI Pro(下図例)で運用をされる方を対象としています。

構築パターン
データフローの運用シナリオは様々ですが、最もシンプルに
Power BI Desktopからデータモデル用のクエリ
をデータフローで作るシナリオを想定して解説を行います。
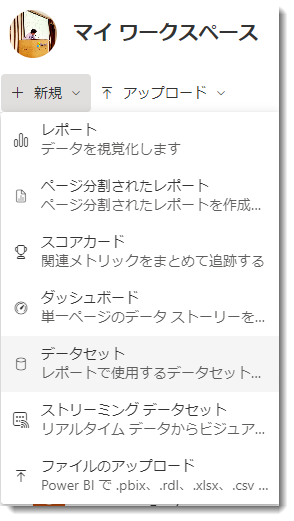
データフローはマイワークスペース*2で作ることができませんので、自然とPower BI ProやPremiumライセンスでの運用となります。マイワークスペースから「新規」をクリックすると、下図のようにデータフローが消えていることが分かります。
そこで、データフローは通常のワークスペースで作ることになりますが、今回は以下のモデルを作れるよう、データフローを作っていきます。出来上がりのデータモデルは以下をイメージしてください。
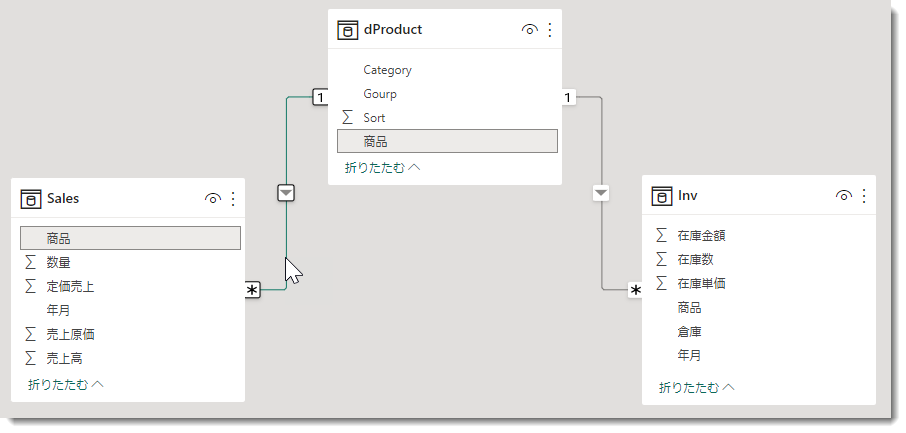
通常は3つのクエリがあれば終わる部分ですが、ソースがCSV(Sales用)とExcel(Inv用)であり、かつ、dProduct(商品マスタ)がない状態からスタートしますので、商品(=商品キー)をリレーションシップのキーとして、Sales(売上)とInv(在庫)という2つのファクトテーブルを抽出した後、それぞれの[商品]列をベースにdProductを作っていくところがポイントとなります。
この説明だけではイメージしにくいと思いますので、クエリの依存関係を見ると以下のようになります。

① SharePointをソースとして、② SourceDataという参照用クエリを構築。ファクトテーブルに使用する③と④をそれぞれCSVとExcelから結合した後、⑤と⑥、そして⑦という3つのクエリから⑧のdProductを作る。最終的に③と④と⑧がモデルに読み込まれる
というのが説明になりますが、これをPower BI DesktopやExcelで作った場合とデータフローで作った場合で結構体験が異なります。
この話をする前に、今回の事例では以下2つの質問が出てくるかもしれません
- そもそもなぜディメンションテーブルをファクトテーブルから作っているの?
- なぜデータソースはSharePoint?
1に対する回答はシンプルで、
このようにしか作れない場合もある
というのが答えです。前職を例に出しますと、顧客からデータを受領して在庫分析を行っていましたが、データのやり取りは基本的にExcel、CSV等になります。データリクエストに際して各種マスタの提出をお願いしないと入手できませんので、従来のExcelの世界ではSalesやInvといったテーブルに各種マスタにある属性(列)が付属してくるものでした。商品名しかないところから分類名を作り出したりしていましたので、非常に時間の掛かる場合もありました(例:機械設備の評価の場合、企業は異なるメーカーから調達を行うため、分類マスタを管理していない場合、Power BIで分析を行う場合にマスタを作るのに非常に苦労します)。
そして2つ目の質問ですが、こちらは単純にデモ用にSharePointを使っているだけというのが答えです。フォルダ等のローカロファイルをソースに使っても良かったのですが、ローカロソースの場合、データフローは更新に際してオンプレミスデータゲートウェイ(使い方はこちら)が必要になりますので、設定が必要となります(今回は割愛)。なお、SharePoint上に大量のファイルを置いて、それらを結合する場合、ファイル数が多いと更新時のパフォーマンス低下に繋がるため、注意が必要です(というより、まったくお勧めしない)。
以下、参考までにSharePointのデータを利用するためのやり方を転載しておきます。
Power BI Desktopでベースを作成
オンプレミスデータゲートウェイを使用せず、データフローのスケジュール更新等を行うためには、ローカルではなく、クラウド上のURLからデータを取得する必要があります。今回の例で、対象ファイルに接続するローカルOneDriveでのパスは
C:\Users\Administrator\OneDrive - ○○\03_BI_Target\★Template\InvSales
となっています。Power BI Desktopでこのフォルダパスを参照する場合、ローカル扱いとなりますので、SharePoint.Filesではなく、Folder.Filesというコネクタを使用することになります。一方、これをSharePoint上のパスにするためには、以下のように操作をします。
- OneDriveのアイコンをクリックし、「オンラインで表示」
- URLが以下のようになりますので、下記パスをSharePoint.Filesのパスとして指定(※ファイル数が多い場合、時間が掛かります)
https://○○-my.sharepoint.com/personal/△△/
○と△は人それぞれとなりますが、これを指定することで、OneDrive(SharePoint)内の全てのフォルダを抽出してくることが可能に - ターゲットとするフォルダを絞り込む(私の場合は以下の通り)

これでSharePoint上にあるターゲットファイルを全てリストアップすることができました。
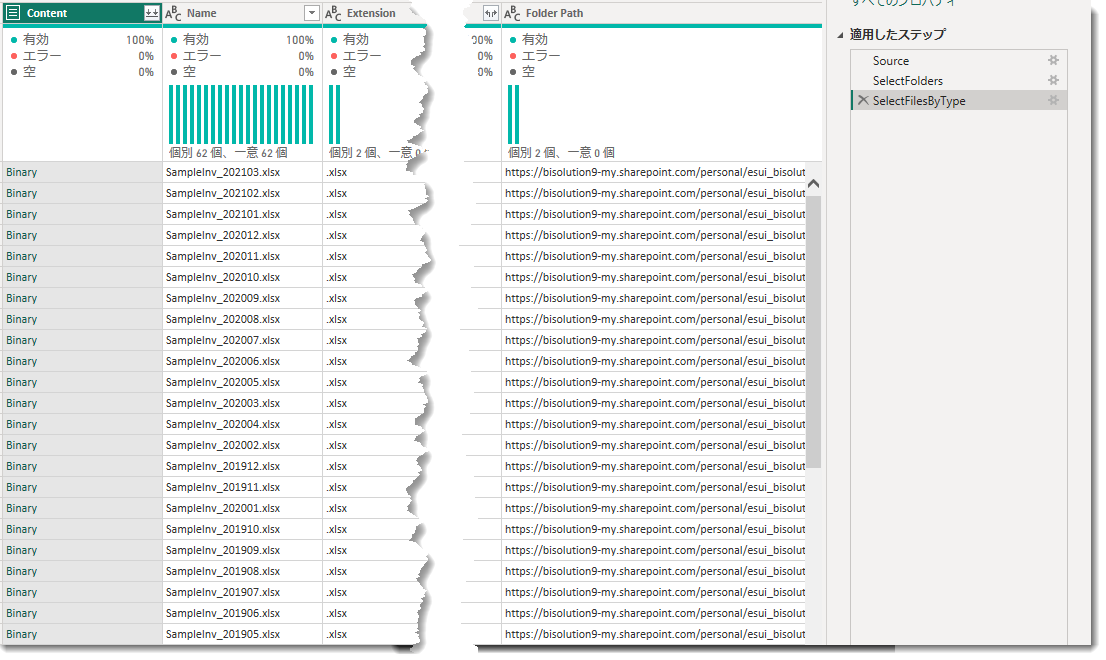
ここから、この作られたクエリを参照して、ExcelとCSV別に結合していきます(やり方は以下ご参考)。
念の為、全てのコードを載せておきますが、全てはdProductを作るためにあります(Mマニアの人以外はコードを即スルーしてもらって良いと思います)。
- フォルダパス用パラメータ(非表示)
- フォルダ内(非表示)
- Inv、Salesクエリ(表示)
- dProductを作るためのInvクエリ(非表示)
- dProductを作るためのSalesクエリ(非表示)
- dProductにCategory等の列を追加するためのクエリ(非表示)
- dProductクエリ(表示)
これら全てのクエリを作ると、以下のようになります。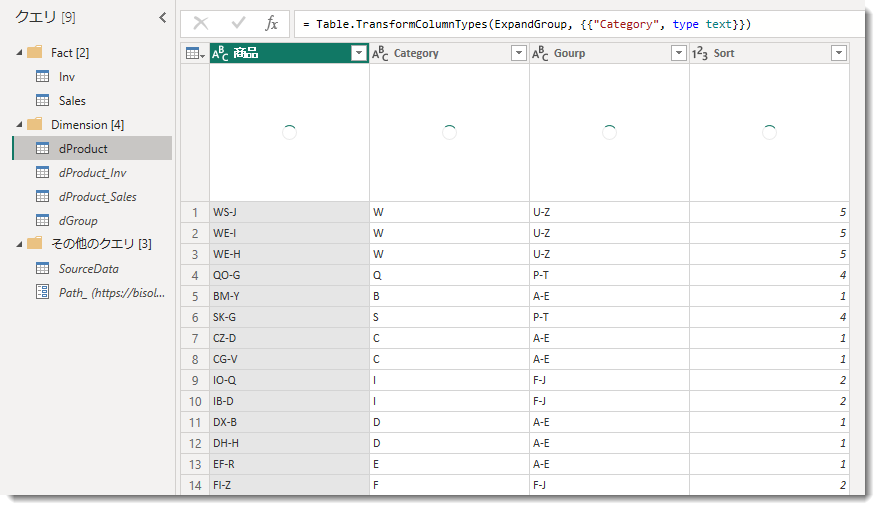
ここでInvとSales、dProduct以外は全て読み込みを行わない設定となっていますので、このままPower BI Desktopから「閉じて適用」を行うと、3つのテーブルだけがデータモデルに読み込まれますが、データフローで同じようにやろうとすると・・・
データフローの利用制限
Power BI Desktopで作った全てのクエリをデータフローにコピペしていきます(コピペのやり方)。いきなり貼り付けた場合、資格情報が必要となりますので、設定を行っていきます。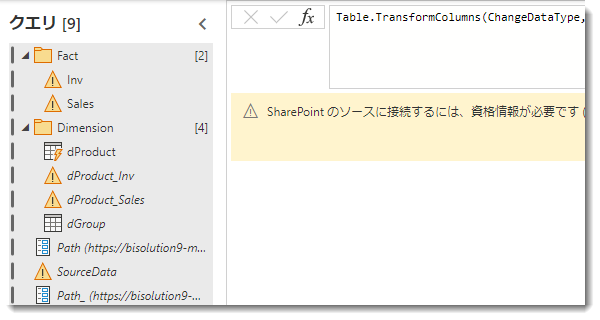
このメッセージの右にある「接続の構成」を押し、「接続」します。すると、以下のようなメッセージが下のほうに出現し、少し待つと全ての処理が完了します。
![]()
そしてここでいきなり最初で最強の関門にぶち当たります。⚡マークが付いているクエリ(dProduct)の出現です。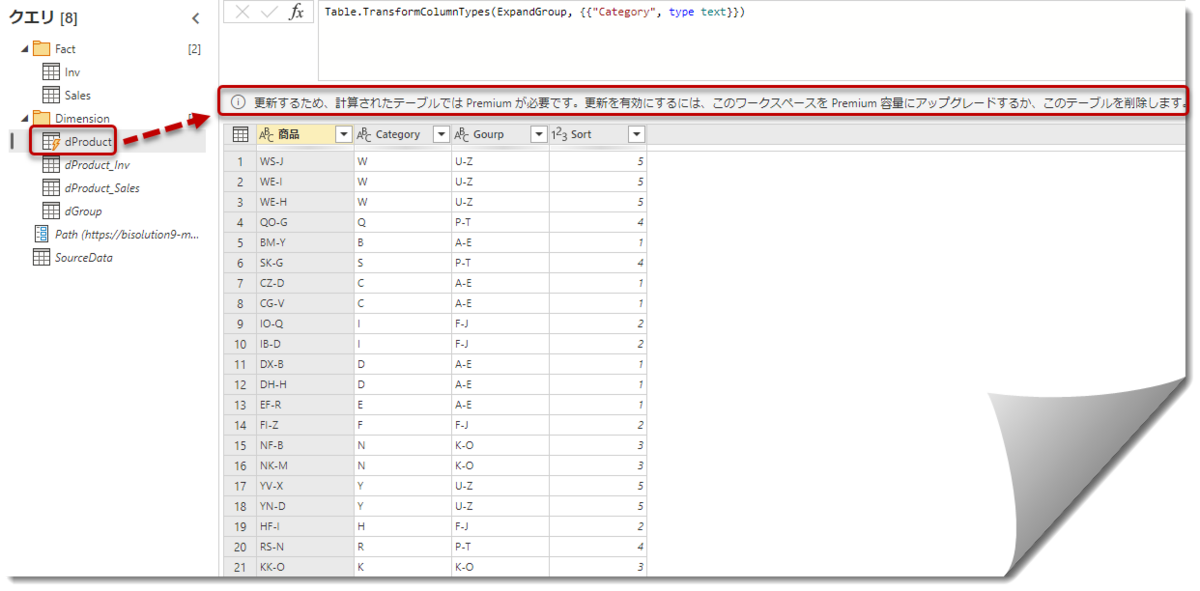
メッセージを読むと、こちらはプレミアム機能とあります。このまま、無理やり右下の「保存して閉じる」をクリックすると、スキーマチェック等の処理に入り、最終的に「今すぐ更新」をクリックしても、「問題が発生しました」とデータフローの更新ができません。

この「更新」という言葉、実は非常に重要で、デスクトップ版Power QueryとPower Query Online(データフロー)が大きく違う部分の1つとなっています。すなわち、データフローでETLを行うと最後には必ず「更新」をする必要があります。更新することで実際にデータが各種ソースから読み込みが始まり、
データの読み込み先
がどこになるのか、ということが重要です。デスクトップ版Power Query(ExcelやPower BI Desktop)は読み込み先がデータモデル、すなわち読み込んだテーブルでリレーションシップを作り、モデリングを行っていきますが、データフローの場合は
Power BIサービスが管理するストレージ
に読み込まれます。
データフローの特性の1つとして、再利用性が挙げられますので、小さなデータベース、あるいはデータソースとして利用できるわけです。
なお、データフロー同士でリレーションシップを組むことはできず、リレーションシップを組み、データモデリングができるのは(2023年2月時点において)Power BI Desktop(他のツールもあるがここでは割愛)やPower Query Onlineを経由して、Power BIデータマート(PPC、もしくはPPU必要、プレビュー機能)となります。
少し話を戻して、⚡マークのクエリですが、これは下記公式ドキュメント(開くと日本語)にあります通り、ストレージ内にて計算を行うことができる機能(計算されたエンティティ)となります。
計算されたエンティティは以下の特性があります。
- プレミアム機能である
- 実現させるためには、ストレージ内にまずデータを持ってくる
- データを含むテーブルが出来上がってから、計算されたエンティティを作ることが可能
言い換えれば、計算されたエンティティとは
マテリアライズ(or キャッシュ)されたクエリ
となります。マテリアライズ(Materialize)は聞き慣れないかもしれませんが、”具現化”とか”実現された”という意味で、SQLの世界ではよく「マテリアライズド・ビュー」という用語を使っています。
※ マテリアライズという言葉よりもキャッシュのほうが分かりやすいので、この後全てキャッシュという言葉を使うことにします
Excel Power Queryの世界であれば、他のクエリをマージやグループ化した結果、「適用したステップ」が増え、プレビュー画面の更新でさえ非常に遅くなってしまうところ、以下のパターンで回避できるようになります。
- 途中まで抽出変換されたクエリを一旦ワークシートに読み込む
- ワークシートに読み込んだクエリ(テーブル)を参照して最終クエリを作る
1が上述した「・・ストレージ内にまずデータを持ってくる」の部分であり、2が1をベースに作られた「計算されたエンティティ」というイメージになります(下図)。
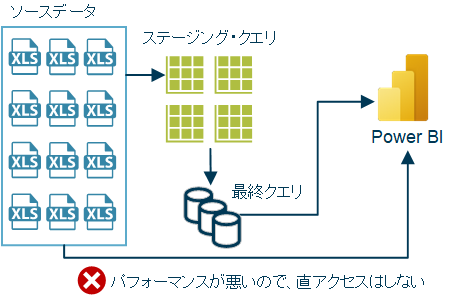
上図は別用途で作ったものでこの概念を全て説明できるものではないですが、「ステージングクエリ」(キャッシュされた状態)が上記1、「最終クエリ」が計算されたエンティティ、というイメージになります。特徴はステージングクエリがキャッシュされた状態となっていることから、それを参照して作られる「最終クエリ」の更新パフォーマンスが非常に良くなることです(今回の例dProductがこちらに相当)。
データフローでの運用(Proライセンス)
このように、Proアカウントでは「計算されたエンティティ(Computed Entities)」を利用することができないため、データフローを活用したアーキテクチャを作るのが難しくなります。計算されたエンティティはリンクされたエンティティからも作ることが可能ですが、次回以降追って詳しく説明します(こちらの機能、私は最初結構混乱しました)。
dProductは必須なテーブルとなるため、これを作るためにはどうすれば良いのでしょうか。結論から先に言いますと、
dProductを作るためのクエリがキャッシュされる前にdProductを作る
ことになります。少し分かりにくいので、図説します。データフローには「ダイアグラム ビュー」というものがあり、こちらはクエリエディタの右下にあるアイコンをクリックすると表示されます。
すると、デスクトップ版Power Queryの「クエリの依存関係」を進化させたダイアグラムビューが表示されます。
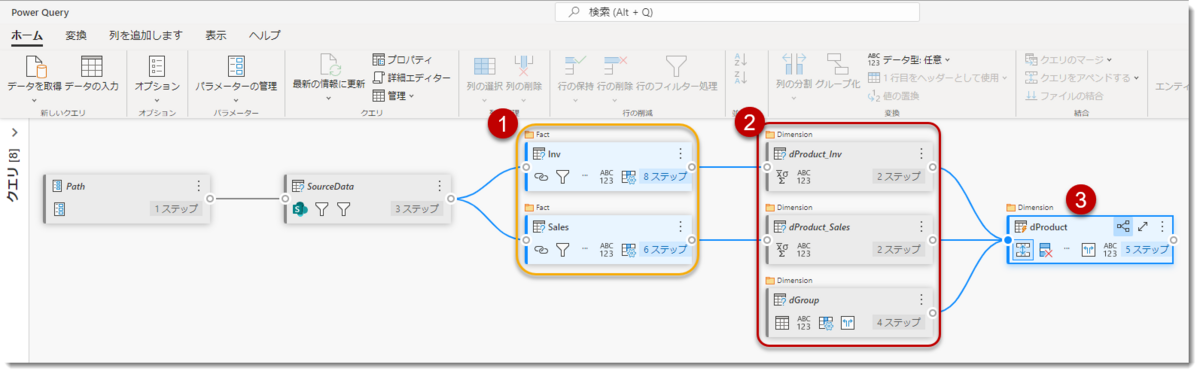
ここで③(計算されたエンティティ)が参照しているのは②(「読み込みを有効にする」がOFFの状態)となっていますが、その参照元である①がキャッシュされたInvとSalesとなっています。InvとSalesの参照先はデータソースとなりますので、この段階では「計算されたエンティティ」という扱いではありません。「計算されたエンティティ」はあくまで、キャッシュされたクエリを参照したり、結合・マージ等を行った際に定義されるものとなっています。
試しに②のdProduct_Invを「読み込みを有効にする」にした場合(下図)、既にキャッシュされた①のInvを参照しているため、②のdProduct_Invは「計算されたエンティティ」となってしまいます。結論として、②を元に作られる③のdProductも計算されたエンティティになりますので、②で全てのクエリを「読み込みを有効にする」をOFFにしたところで、③はキャッシュされたクエリである①を暗黙的に参照しているため、計算されたエンティティとして、Proライセンスでは使用できない、ということになります。
となると、残された手段は1つで、dProductをProライセンスで読み込むためには、
dProductを最初にキャッシュされたクエリとして作る
ことが必要になってきます。
ちなみに、下図の通りdProductを作るのに、dGroupとマージを行う必要があり、マージを行った場合も計算されたエンティティとなります。
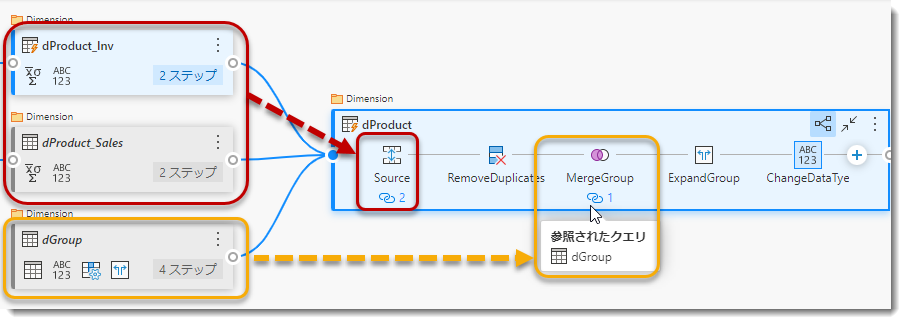
もうご想像がつくと思いますが、dProductをProライセンスの環境で作るためには、これら3つのクエリを1つにする必要があることになります。
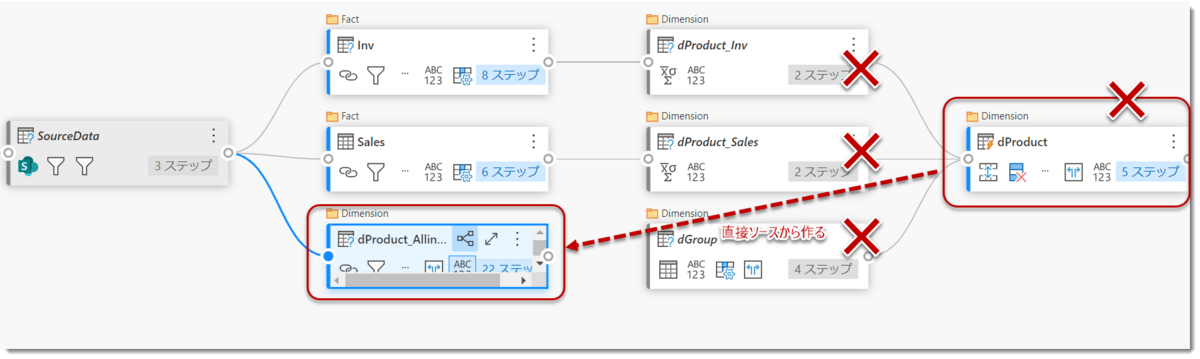
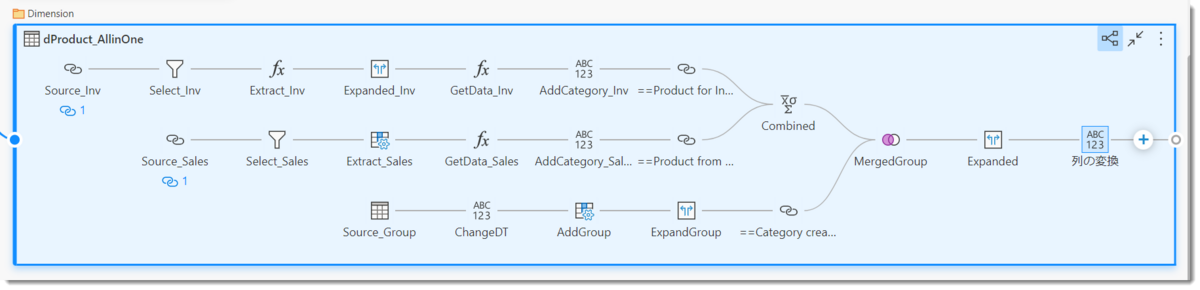
- dProductを最初から作った場合のクエリ
見てお分かりの通り、3つのクエリ(dProduct_Inv, dProduct_Sales, dGroup)を強引に1つのクエリとして作り、しかもデータソースから「計算されたエンティティ」にならないように作っていますので、かなり複雑な構造になっています。もはやPower QueryのUIで作業できるものではなく、メンテナンスが必要な場合、それなりにM言語に関する知識が必要になります。
そしてこのクエリには弱点があり、それは更新を行った場合、常にデータソースに対する負荷を掛けてしまうことです。プレミアム機能である「計算されたエンティティ」はメリットの1つとして、データフロー内でキャッシュされたクエリに対して更に追加で変換を行うことが可能なことであり、データソースへの負担を減らしつつ、処理変換のパフォーマンスも改善されることですが、Proライセンスではそのメリットを享受できないということになります。
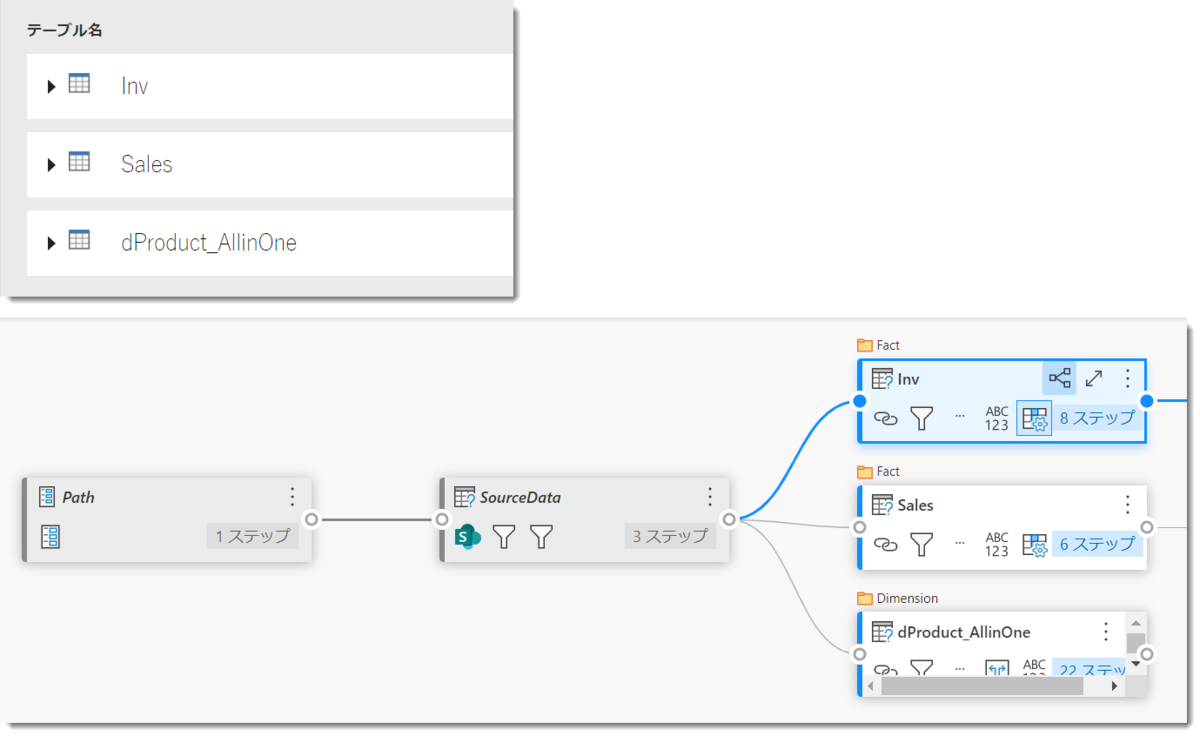
最終的にdProduct_AllinOneを含め下記3つのクエリでデータフローを保存することができるようになりましたが、今回紹介したクエリを構築する際に遭遇するボトルネック以外にも、更新回数(Proの場合は8回、Premiumの場合は48回)やPower BIサービスが提供する拡張コンピューティングエンジンをプレミアム環境でしか使用できない等、データフローがチームコラボレーション(組織向け)のソリューションであることが分かります。
まとめ
- Power BIデータフローをProライセンスの環境で使おうとすると、マージやテーブルの追加、参照等のオペレーションを行うことが難しくなる
- それでもProライセンスの環境でデータフローを構築したい場合、「計算されたエンティティ」の概念をしっかり理解した上で、クエリ及びアーキテクチャの構築を検討されたい
- Power BI Proの環境で計算されたエンティティにならないよう、オリジナルソースを参照し、最終クエリになるような書き方を心がける必要がある
かなり長くなりましたが、データフローとデスクトップ版Power Queryはかなり違うと理解できたのではないでしょうか。次回はPremium環境でデータフローを活用する際の事例等を紹介したいと思います。