Microsoft Fabric (以下、Fabric)が登場して約1ヵ月が経ちました。Fabricは、Power BIをベースとしたSaaS*1型のオールインワンアナリティクス基盤であり、データ分析に必要なワークロードがすべて含まれています。
各種のワークロードには、それぞれ異なるペルソナ(下図参照)が存在し、これらのペルソナを持つ企業ではチーム間のコラボレーションが増加することが予想されます。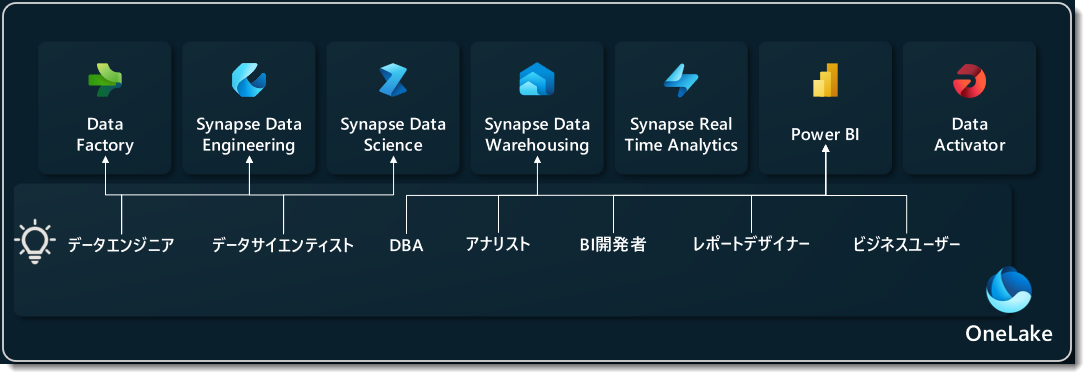
※上図はあくまで一例
Fabricの主要なワークロードであるPower BIは、他のエクスペリエンスから得られたデータを効果的に可視化する役割を果たします。以下では、Fabricがパブリックプレビュー時点のセルフサービスBIユーザーが手軽に試せる1つのシナリオをご紹介します。
なお、実際にFabricを利用するシナリオを紹介するまでに多くの基礎知識を紹介していますが、全て目を通して頂くことをお勧めします。
※注意
「データセット」は別名「セマンティックモデル」に変更となっています。
Datasets renamed to semantic models | Microsoft Power BI Blog | Microsoft Power BI
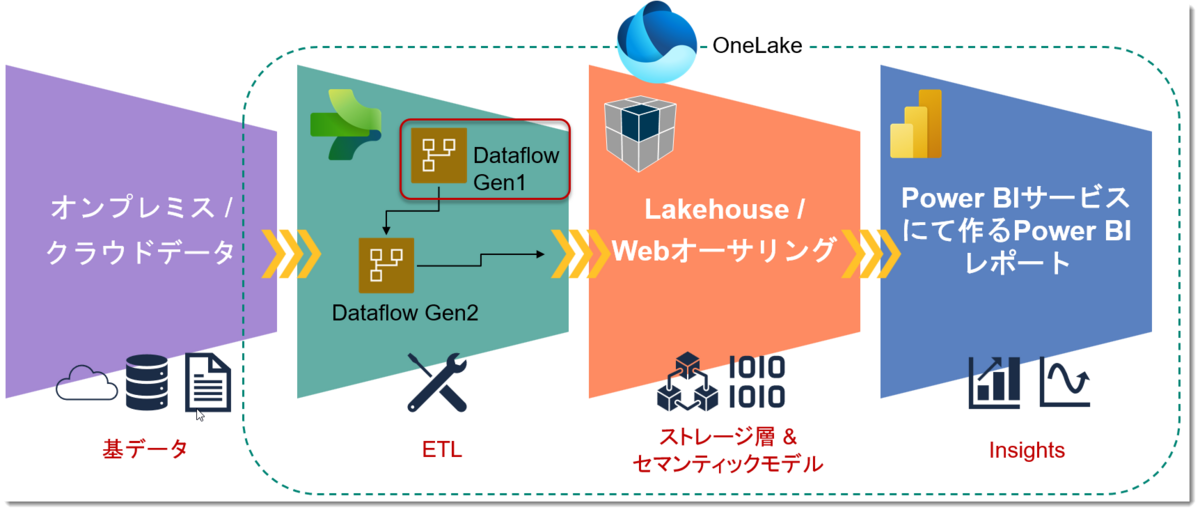
シナリオ(概要)
SQLサーバーにあるContoso Retail DBからデータを取得し、WebエクスペリエンスだけでPower BIレポートを作成
一般的なBIユーザーが良く使うPower Query体験によるものとなりますが、ステップは以下の通り。
- 基データの確認
- Data Factoryのアイテム「Dataflow Gen2」(以下詳述)を選択
- 「Dataflow Gen2」でデータを「Lakehouse」*2へロード
- Power BIで可視化
イメージは下図のような形になります。なお、非常に長くなってしまいましたので、4のPower BIで可視化については次回以降、話をします。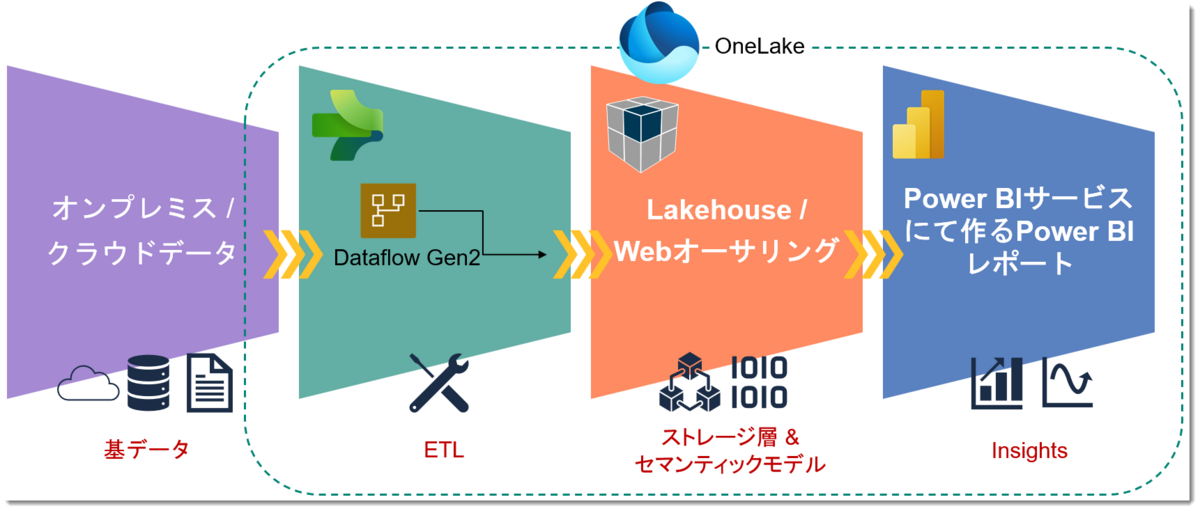
シナリオは非常にシンプルですが、前提条件として以下を満たす必要があります。
- オンプレミス版SQLサーバーを使用(Sutoさんのブログが分かりやすい)
- ContosoRetailDWを復元(同上)
- オンプレミスデータゲートウェイがインストールされている(必ず最新版を使用すること)
- Fabricを使用できる
環境を持っていない方でも、先程の説明で理解できると思いますが、より深い理解を得るためには実際にステップを追って試してみることがおすすめです。また、今回紹介した内容とは異なりますが、Fabric CAT*3のAlex Powersによる非常に分かりやすいエンドツーエンド・チュートリアル「Power BIユーザーのためのFabric」がFabricを実際に体験するのに非常にお勧めです。
Dataflow Gen2
過去10回ほど、データフローについて多くの情報を共有してきましたが、実はそれはすべてFabricを利用するセルフサービスBIユーザーがデータを取得する際のヒントを提供するためのものでした。
FabricではData Factoryというエクスペリエンスにて、新しいデータフロー(以降、Dataflow Gen2)が登場していますが、以下のようなイメージとなります。
- Dataflow Gen1 = Power BIデータフロー
- Dataflow Gen2 = Fabricデータフロー
両者は混乱しやすいですが、Power BI ProではGen1データフローのみが利用可能であり、Fabric容量を有効にすることでGen2データフローも利用できます(※Fabric容量を有効にした場合、Gen1も使用可能)。詳細については、以下を参照してください。
主な違いは以下の通りで、データフローを作成したり、データを取得する部分以外はそれぞれ可能・不可能な違いがあります。実際は更に細かい部分でデータフローのコンピュートエンジンが違ったりしますが、そちらについては割愛します。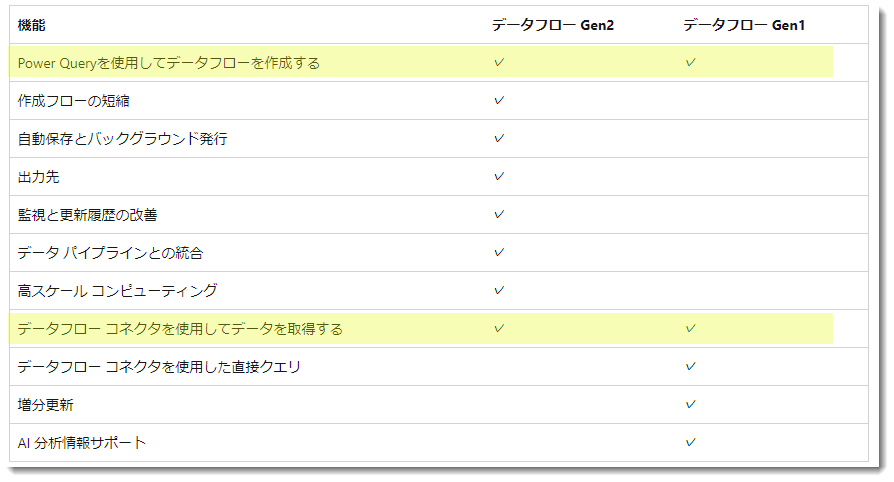
※ 各項目の詳細については上記公式サイトから確認されたい
Dataflow Gen2の特徴①
Dataflow Gen2の大きな特徴として、これまでのGen1ではPower BIのデータセットのソースとして機能していたものが、Gen2ではさらにLakehouseやWarehouseへのロードのためのステージングのような性質を持つことが挙げられます。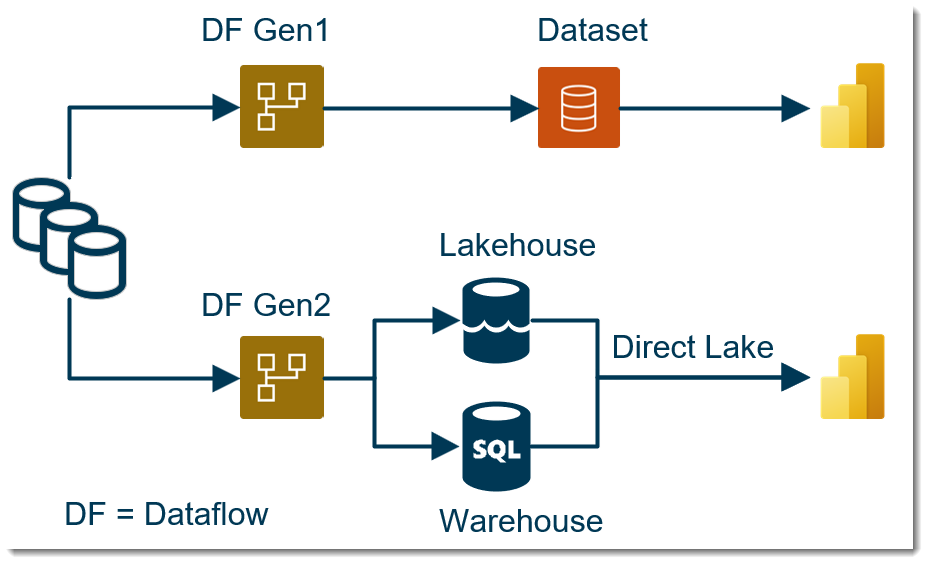
※ 2023年6月19日時点では、WarehouseからはDirect Lakeは使用できません。Direct Lakeの詳細や制限についてはこちらをご参照
Lakehouse、WarehouseはFabricのOnaLake*4におけるアイテム*5であり、前者は構造化・非構造化・半構造化データ、後者は構造化データを取り扱うものとなります。なお、LakehouseやWarehouseについては公式Docsが分かりやすいですが、別途ブログにて解説したいと考えています。
Direct Lakeモードは別名「シースルーモード」と呼ばれていますが、
インポートモードのクエリパフォーマンス + DirectQueryのレイテンシー(=データの鮮度)を併せ持つ
BIにおける次世代テクノロジーとなっています。最新のデータを常に取得したい場合、クエリパフォーマンスの遅いDirectQueryを使用せざるを得なかった人は、今後はDirect Lakeモードを使用することで、DirectQueryモードでありながらインポートモードのクエリパフォーマンスを享受できるようになります。
なお、Direct Lakeモードは執筆時点、Power BI Premium P SKU と Microsoft Fabric F SKU でのみサポートされることに留意が必要です( Power BI Pro、Premium Per User、または Power BI Embedded A/EM SKU ではサポートされていません)。
Fabricのライセンス
Fabric サブスクリプションの購入
Dataflow Gen2の特徴②
もう一つの特徴として、Dataflow Gen1ではマイワークスペースに作成することができませんでしたが、Gen2ではマイワークスペースでも作成することができるようになりました。
以下、マイワークスペースでFabric容量を有効にします。
マイワークスペースにはダイヤ💎のマークが出現し、プレミアムワークスペースとなったことが分かります。
しかし、通常のワークスペースと比較すると、下図のようにデータフローを選択することはできません(下記の「データフロー」= Dataflow Gen1)。 「すべて表示」をクリックして確認しても、やはりマイワークスペースではDataflow Gen1を使用することはできないことが分かります。
「すべて表示」をクリックして確認しても、やはりマイワークスペースではDataflow Gen1を使用することはできないことが分かります。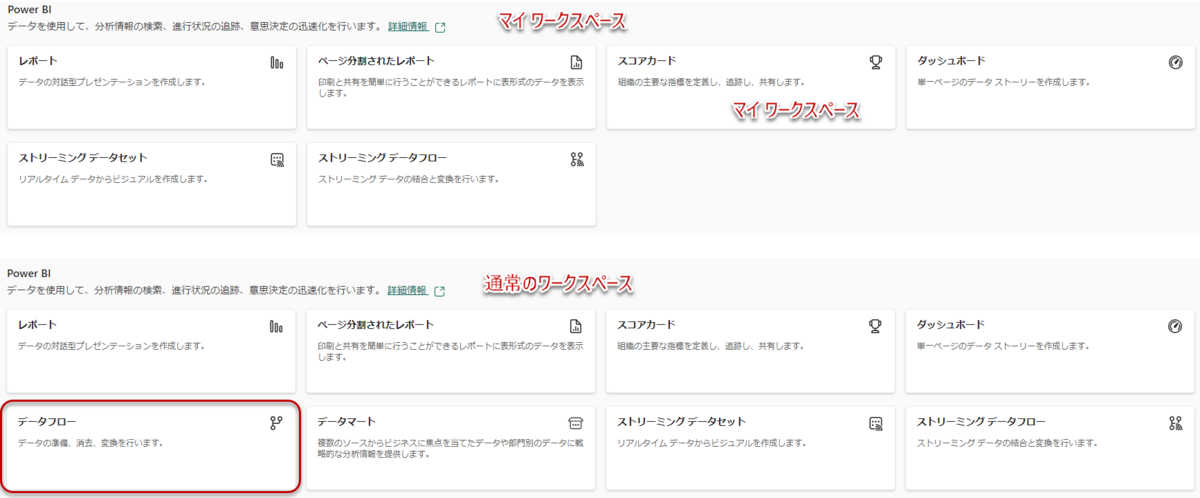
上述の通り、Dataflow Gen1はPower BIデータフローであり、データフローの概念はPower BI Pro以上のライセンス(組織内での共有を目的としたライセンス)でのみ使用できるため、マイワークスペースでは使用できません。その意味でDataflow Gen2(Fabricデータフロー)も同じなのでは?という疑問はありますが、Fabricのデータ統合チームの判断は現時点ではこのようなものとなっています。
シナリオ(詳細)
前置きが長くなりましたが、データ分析で一番最初に行うデータ統合(Data Integration)でセルフサービスBIユーザーはデータフローを使用することになります。Dataflow Gen1とGen2の違いはかなり重要ですが、操作感は殆ど変わりません。
1. 基データの確認
まずは基データの確認ですが、SQLサーバー内のデータベースを確認できるSSMSを入れている場合は以下のように見えるはずです。
① FactInventoryテーブルの上位1000行を取得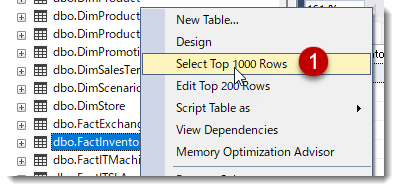
② SQL構文が自動挿入され、Power Queryのプレビュー画面と同じような結果が返される
Fabricはペルソナベースのサービスということを冒頭で話をしましたが、Warehouseを取り扱う必要が出てきますので、セルフサービスBIユーザーでもSQLをある程度学んだほうが良いと思います。
基データが確認できましたので、次はこれらのテーブルのうち、必要なものをいくつかDataflow Gen2を使ってFabricのOneLakeにロードしていきます。
2. Data Factoryのアイテム「Dataflow Gen2」を選択
以下の手順に従って、Data Factory内のDataflow Gen2を使用してデータをインポートします。まず、Fabric容量が適用されたワークスペースを作成する必要がありますが、Fabric容量は無料の60日間トライアルを利用することで無料で試すことができます。下記の説明を参考に、Fabric容量をアクティベートしてください。
マイワークスペースではなく、新たなワークスペースを作ってFabricの試用版(60日無料)を選択します。
アクセスしやすいよう、ピン止めしておきます。
空のワークスペースが作られますので、ここに様々なアイテム(項目)を作っていきます。
「新規」 > 「すべて表示」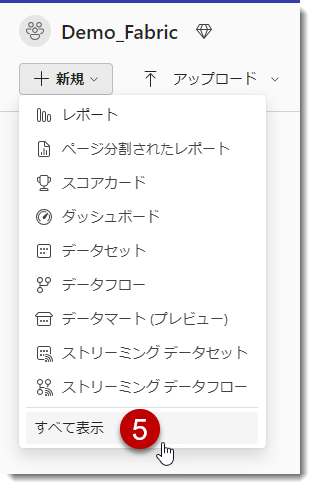
Data Factoryのワークロードから「Dataflow Gen2 (プレビュー)」を選択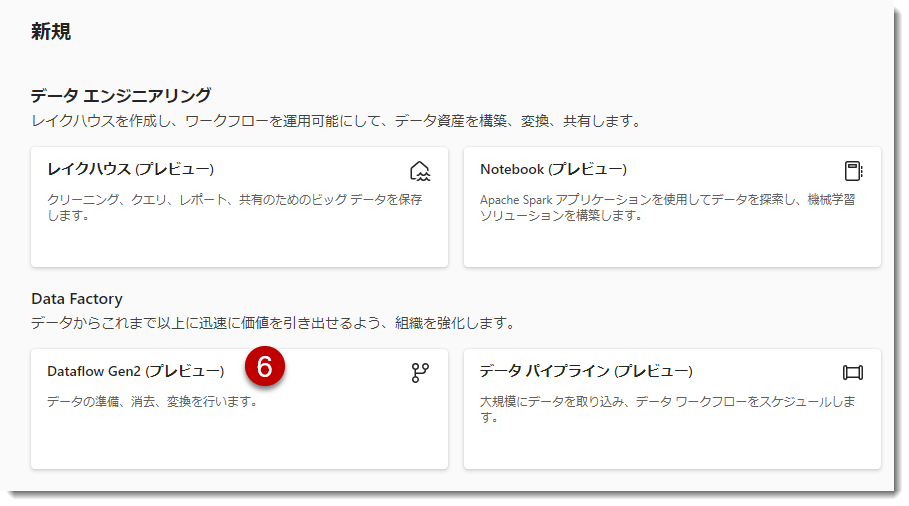
読み込み画面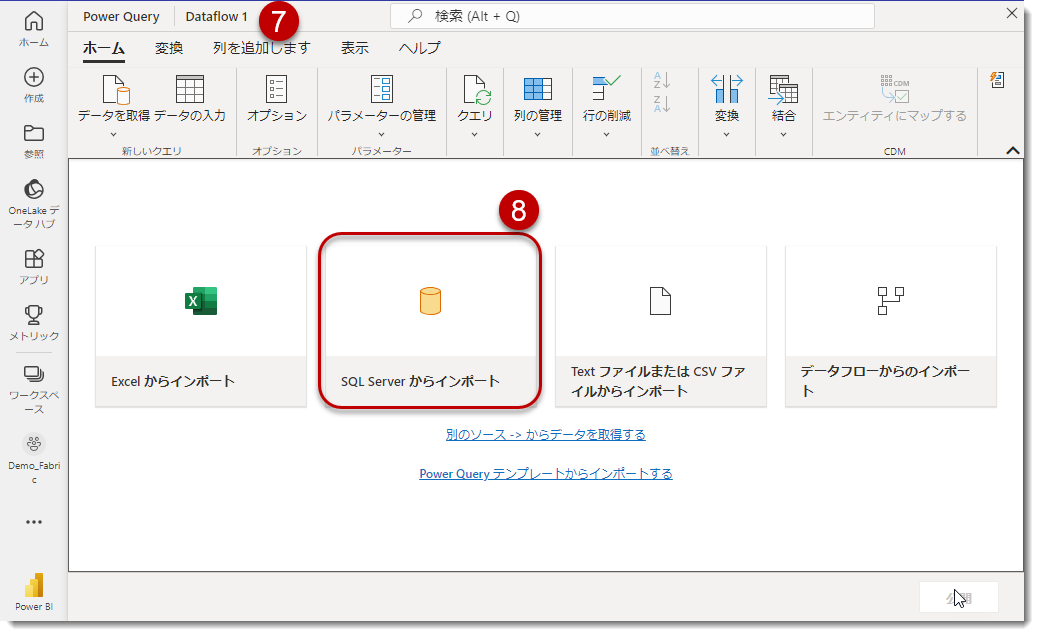
良く使用するソースとして、画面真ん中に4つのソースが大きく表示されていますが、一番右の「データフローからのインポート」はDataflow Gen1をソースとしてデータをインポートすることも可能です。なお、⑦の左側に見える「Dataflow 1」は現在作成中のデータフローの一時的な名前ですが、執筆時点ではデータの更新が終わるまで、名称変更はできません(「名称変更」できるよう、Fabricの製品チームへのリクエストとしては上がっています)。
今回はSQLサーバーからのインポートとなりますので、⑧をクリックすると以下の画面が出現します。
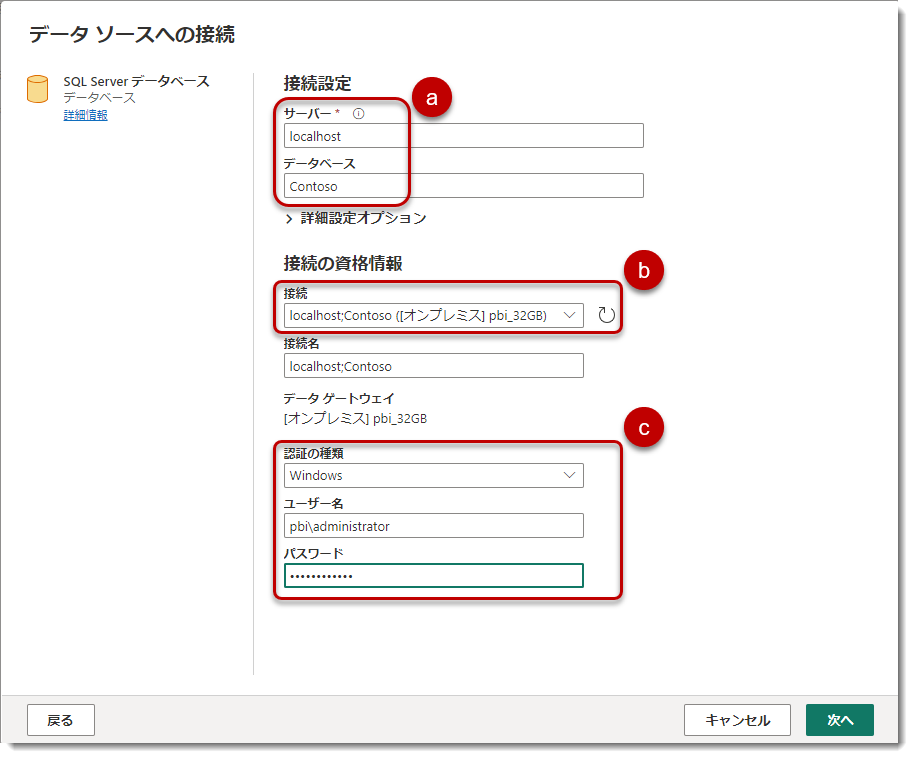
- a) サーバー名とデータベース名
サーバー名は権限借用(Impersonation)*6でlocalhostですが、通常はサーバーアドレスを入力します。 - b) オンプレミスデータですので、ここではインストール済のOn-premise data gateway(標準モード)を指定。オンプレデータは必ずGatewayを経由する必要があり、オンプレミスデータゲートウェイを必ず確認
- c) 認証の種類ですが、私はWindowsによる認証を選んでおり、ユーザー名は「DOMAIN\USERNAME」となります。
なお、ユーザー名が分からない場合、以下のように簡単に調べることが可能です。
- Win + R > cmdと入力
- whoamiと入力し、Enter
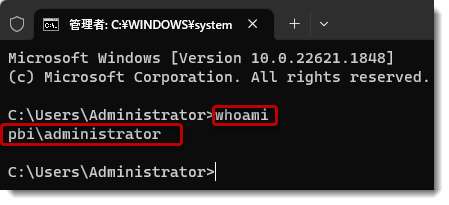
これにより、表示されたものがユーザー名となります。なお、パスワードですが、こちらはPCへログインする際のパスワードを使用します。
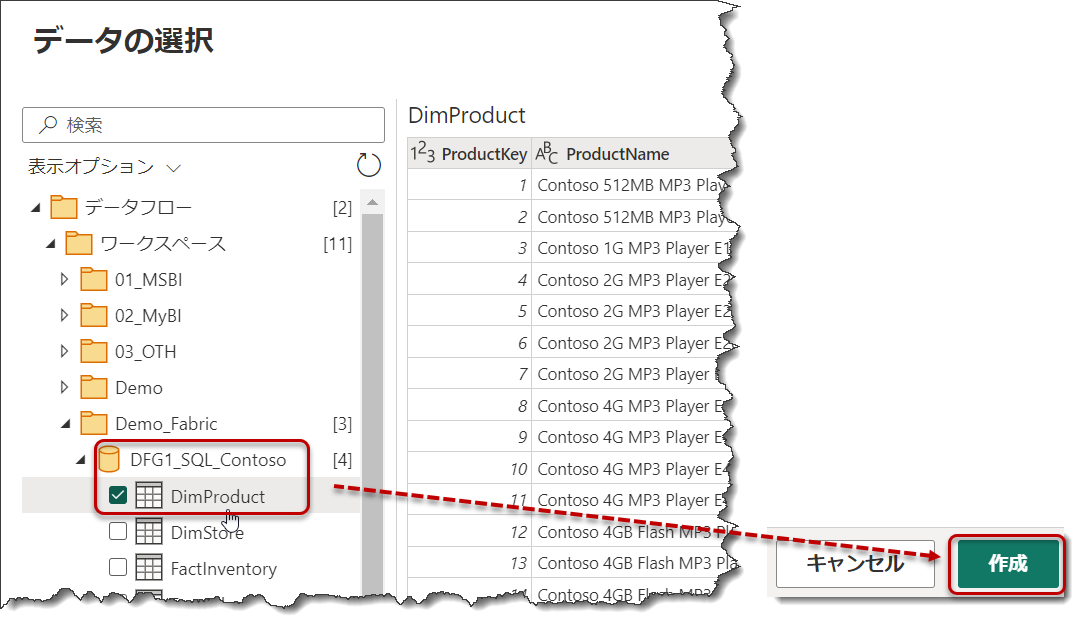
認証に成功すると、データフローへの接続が完成しますので、以下のようにDimでテーブルをフィルターし、DimProductとDimStoreを選択。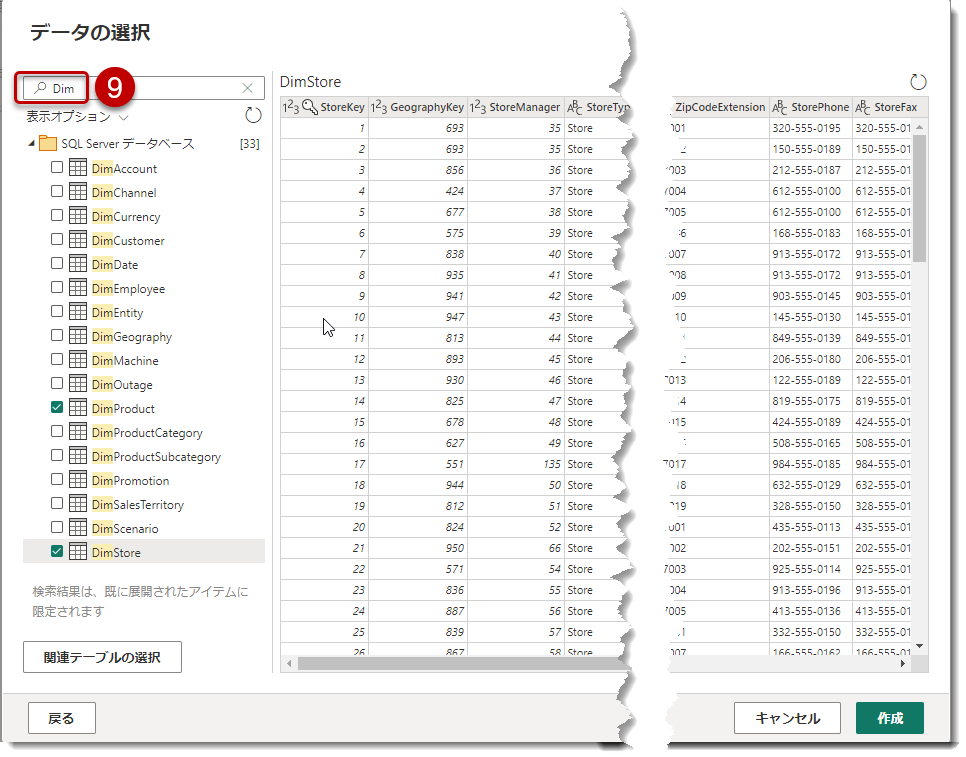
同様にFactでフィルターし、FactInventoryとFactSalesを選択し、「作成」をクリック。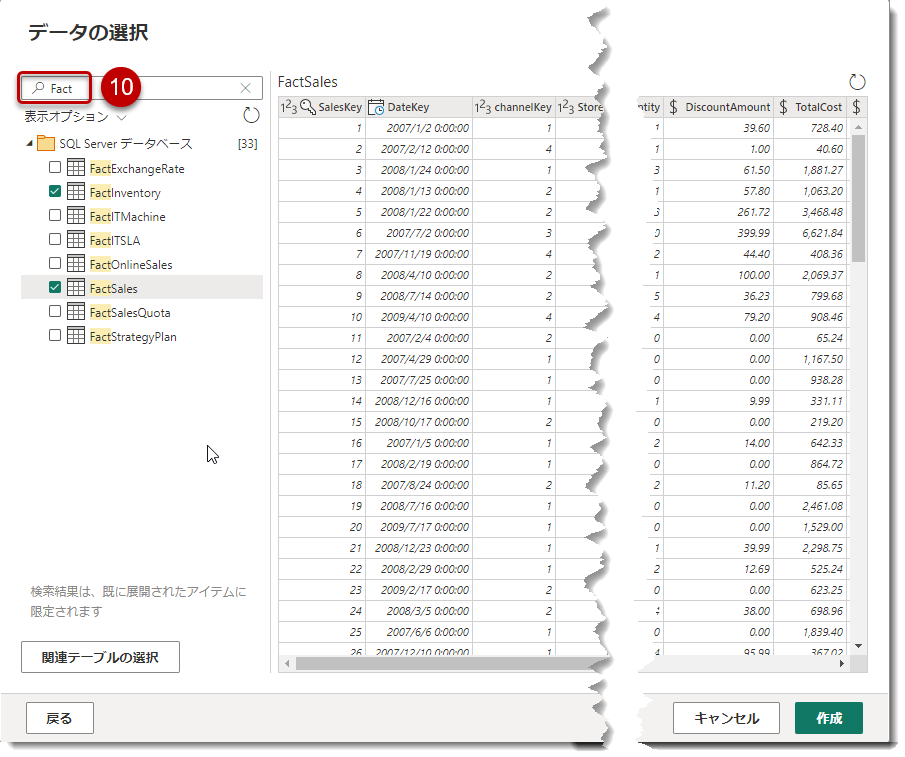
これでデータフローには4つのテーブルが読み込まれるようになりました。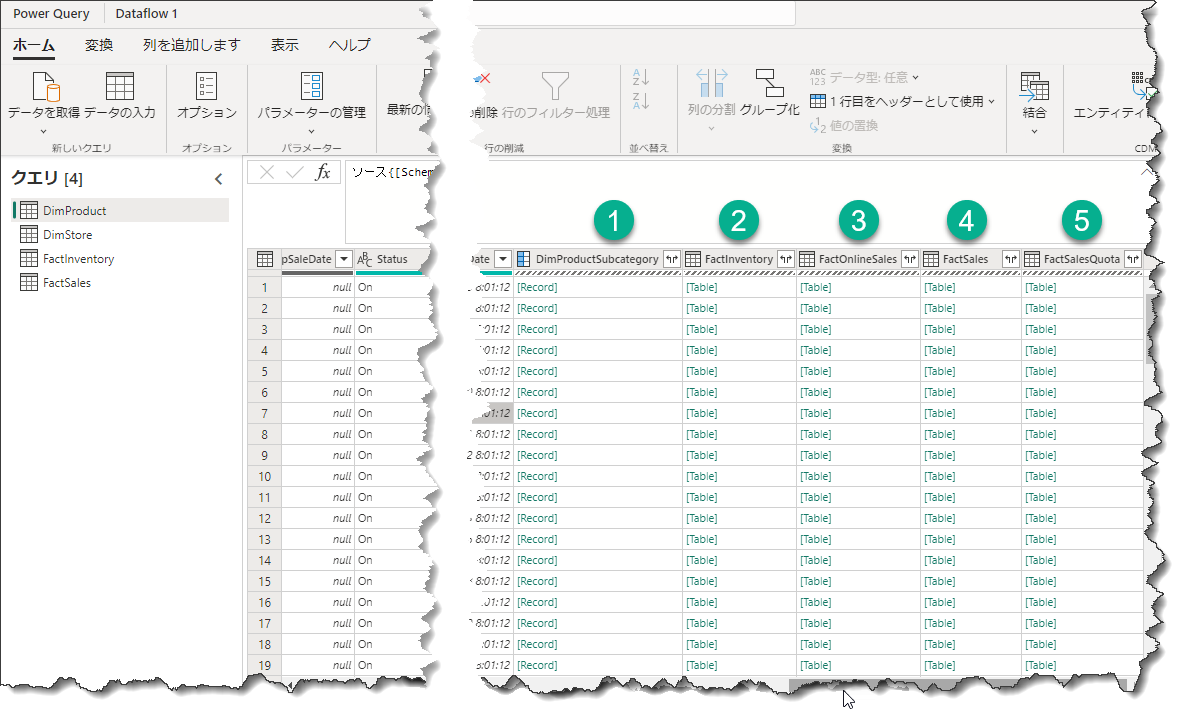
Contosoのサンプルデータを扱ったことがある方は、上図のような場合、RecordやTableを格納した列に遭遇することがあるかもしれません。これらは実際のデータではなく、データベース側(SQLサーバー)でリレーションシップが構築されている場合に、Power Queryエディタの機能を利用してそのリレーションシップから必要な列を抽出するための便利な機能です。
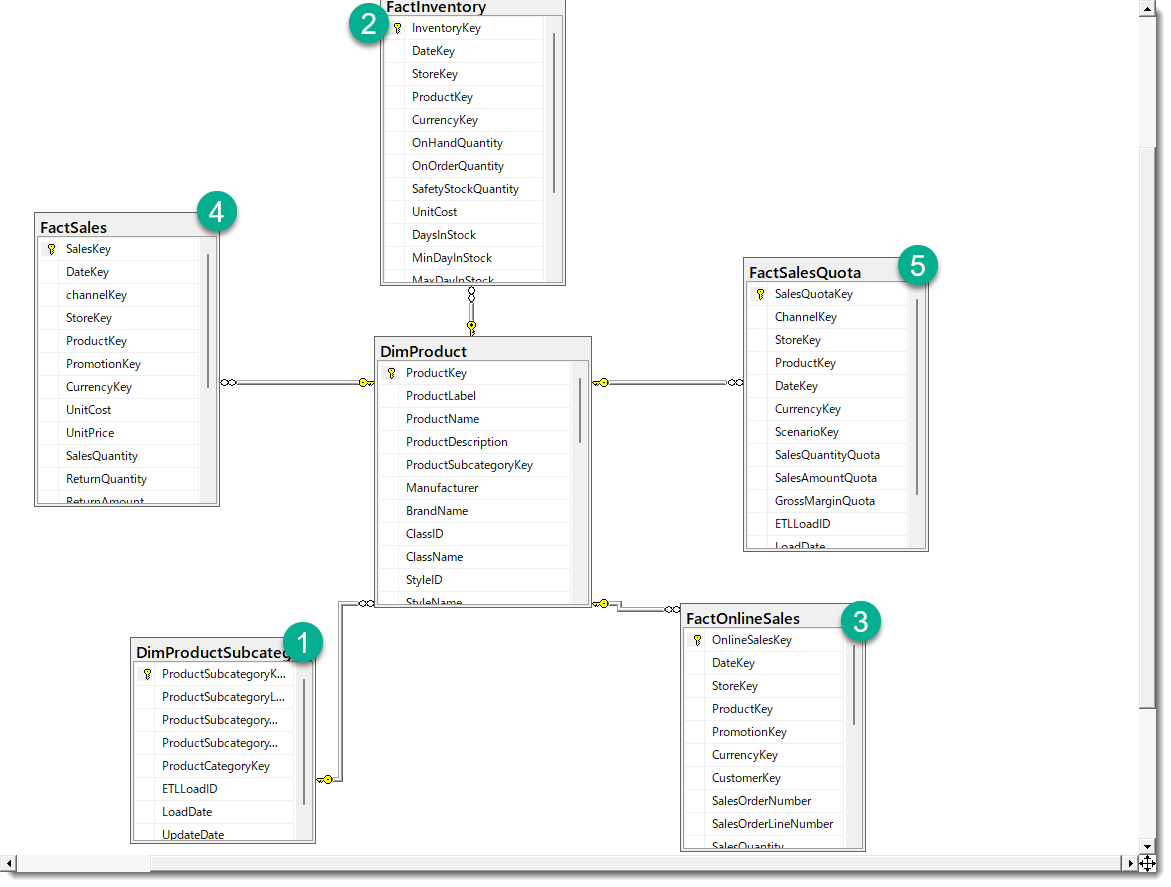
例えば、SQLサーバー上のDimProductテーブルでは、以下の手順を実行することで、DimProductとリレーションシップを持つ列(①~⑤)をSSMS上で確認することができます。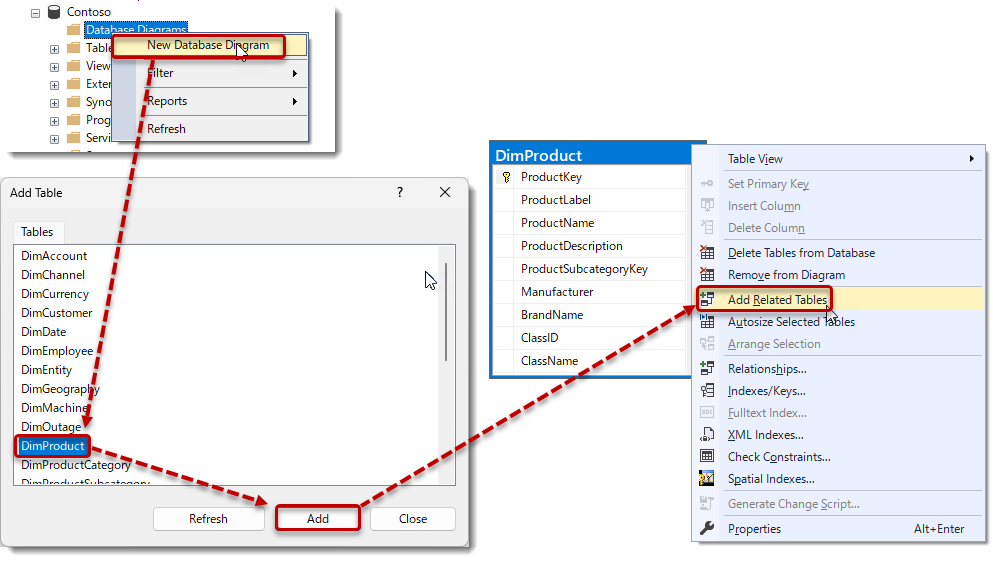
なお、"Record"として表示されている"DimProductSubcategory"列は、展開すると1行ごとに列として中身が表示されます。展開後、"DimProductSubcategory"からは以下の列が抽出されます: (a) "ProductSubcategoryName"列と、(b) "DimProductCategory"列(これはさらにネストされたレコードとして扱われます)。最終的には、(b)から(c) のレコード("ProductCategoryKey"列と"ProductCategoryName"列)から必要な列を抽出することができます。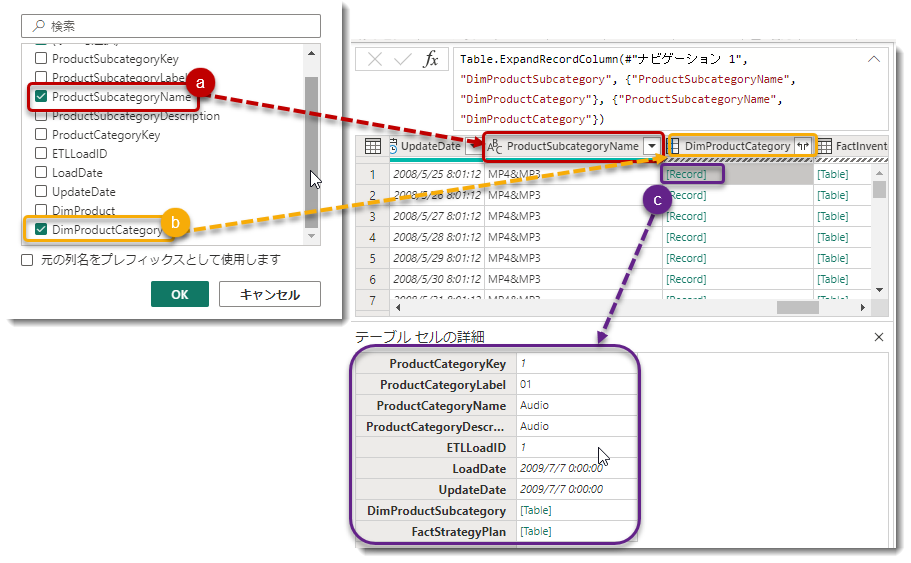
ExcelやCSVなどのファイルを使用する場合、多くの場合、Power Queryでマージ(結合)を行います。しかし、元々データベース側でリレーションシップが構築されている場合、Power Query側でこの処理を行う手間が省けるため、データ取得時の処理コストを低くすることができます。これは一般的に「クエリフォールディング」と呼ばれ、SQLサーバー等で効果を発揮します。クエリフォールディングを常に実現できるようにすることは非常に重要なベストプラクティスの1つとなります。
参考までに、データフロー内で「クエリフォールディング」が適用されているかどうかを確認するためには、「適用されたステップ」を確認することができます。もし、赤いアイコンが表示されている場合は、「クエリフォールディング」が途切れている可能性が高いことを示しています。また、ステップを右クリックして「データソースクエリの表示」が選択できない場合は、途中で「クエリフォールディング」の効果が失われていることを意味します。これらの手順を通じて、「クエリフォールディング」の有効性を確認することができます。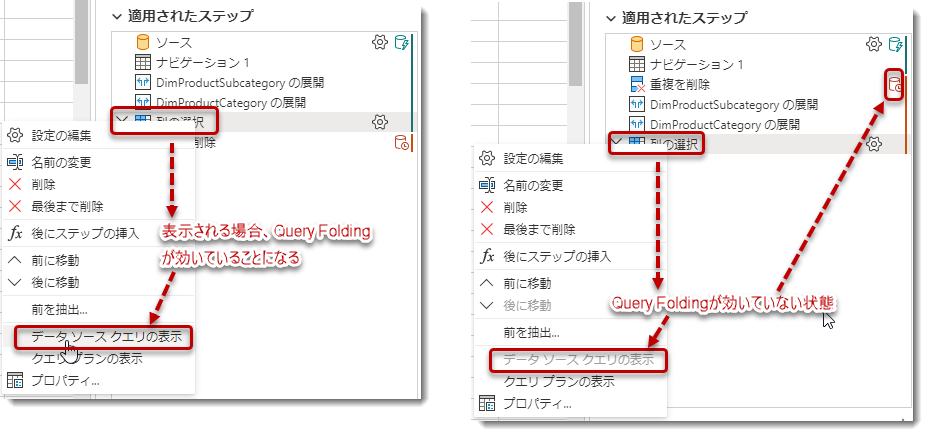
ここで、Power Queryエディタで列の選択のショートカット(Ctrl + K)を使用して、必要な列だけを選択していきます。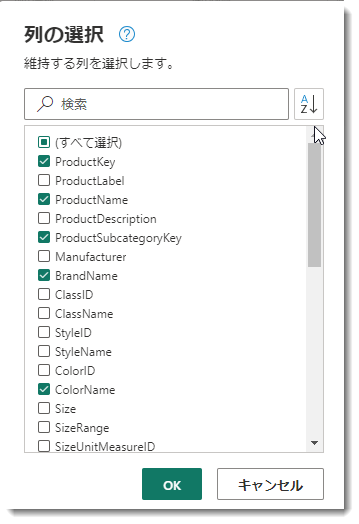
- DimProductテーブル
- DimStoreテーブル
- FactInventoryテーブル
- FactSalesテーブル
3.「Dataflow Gen2」でデータをLakehouseへロード
2が終わると、DF Gen2の部分まで終わったことになります(下図)。
ここからLakehouseへデータをロードしていく作業となりますが、下図の「データ同期先の追加」がこれに当たります。
「データ同期先の追加」アイコンはDataflow Gen1にはなかったアイコンで、執筆時点では下記4つのロード先を選ぶことができます。
ただ、Lakehouseはまだ作成していないので、ここでは何も選択せず、下図の「公開」をクリックします。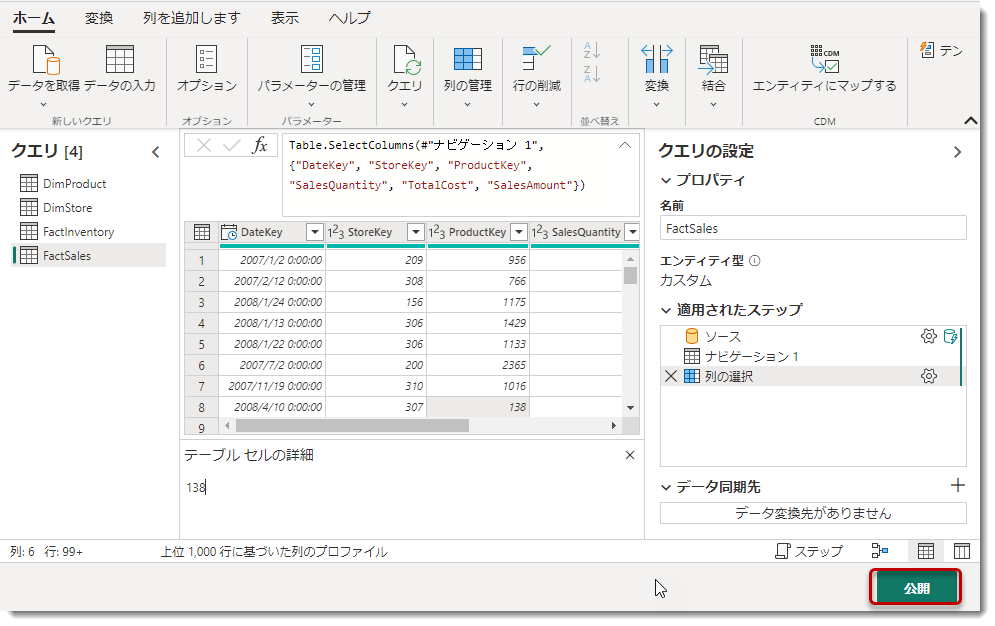
するとDataflow 1はバックエンドで「検証(Validation)」を行い、そのままデータをSQLサーバーから抽出し、更新が始まります。
ここで非常に驚くべきことですが、Dataflow 1というアイテムを作成したにも関わらず、なぜか複数のステージングアイテムが作成されるようになります。なお、繰り返しになりますが、更新中は「プロパティ」から名前の変更を行うことはできません(下図)。
※追記
2023年7月6日時点、公開ボタンに「後で発行する」という選択肢が追加されたようです。これを選択することで、更新が開始する前にプロパティ > 名前の変更が可能となりましたので、通常はこのボタンをクリックすると良いでしょう(下図)。
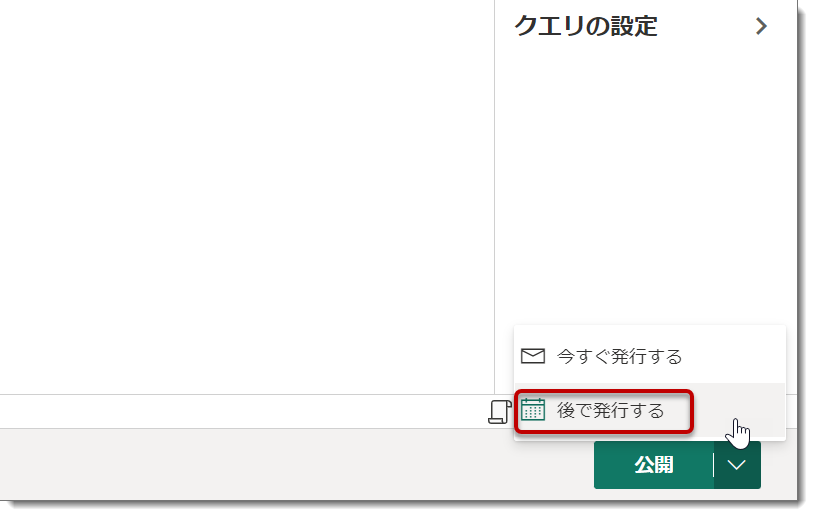
上図のように、「今すぐ発行する」を選択した場合は名前の変更を更新が終了するまで行うことができませんので、下図のように更新が終了した後、「プロパティ」>「Dataflow 1」から名前を変更して、「保存」をクリック。 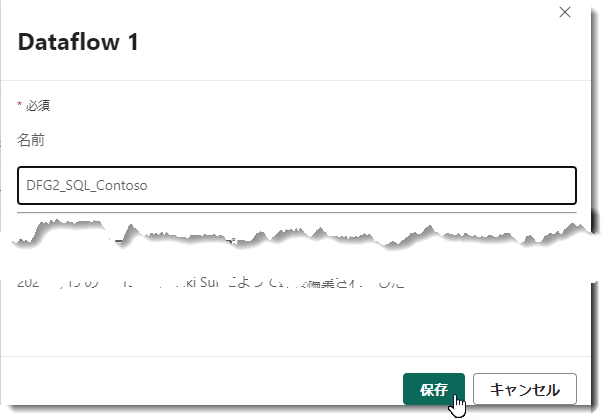
執筆時点では、ワークスペース内のFabricアイテムが自動的に増殖するため、アイテムの命名に注意を払う必要があります。この例では、DFG2(Dataflow Gen2)+ SQL(ソース)+ Contoso(データベース名)という規則で名前を指定しています。
更新履歴を見てみます。下図のように、DFG2_SQL_Contosoの横にある・・・をクリックし、「更新履歴」を選択。
今回の更新はFactSalesが340万行、FactInventoryが800万行というデータ量でしたので、更新に掛かった時間は4分弱となったようです。
ところで、DFG2_SQL_Contoso以外にも5つのステージングクエリが存在し、これがユーザーに混乱を引き起こしています。製品チームはこの問題に対して認識しており、将来的にはこれらのクエリを非表示にする予定です。
なお、これらのステージングクエリは意味を持っており、削除可能なものと削除できないものに分けられます。誤って削除すると、データフローがその先の読み込みを行えなくなる可能性があるため、基本的に何も削除しないよう気を付ける必要があります。。
ここから下図のように、Lakehouseを作ります。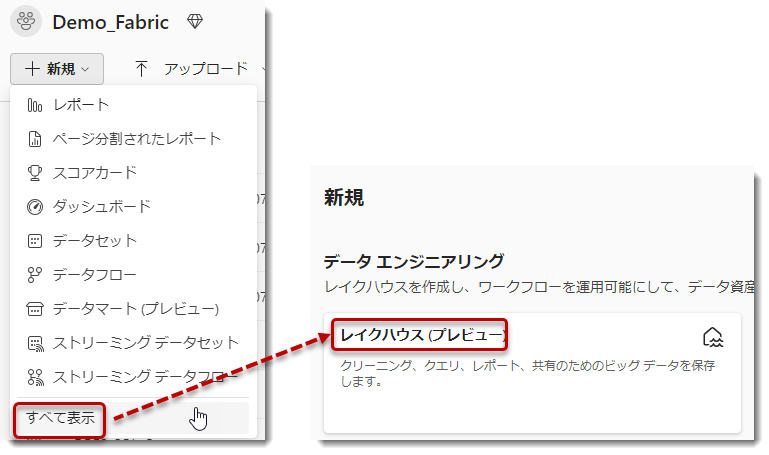
新しいlakehouseに名前を付けます。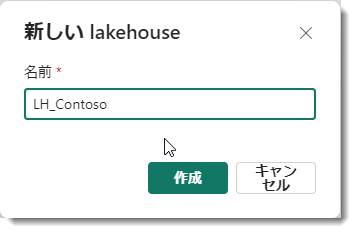
うまく作成が完了すると、下図のように”器”が出来上がります。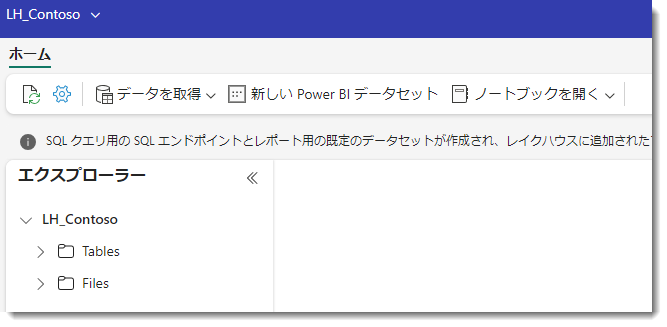
このまま、一旦LH_Contoso(LHはLakehouseの略)から離れ、先程のDFG2_SQL_Contosoに戻り、「データ同期先の追加」に、LH_Contosoを選択します。
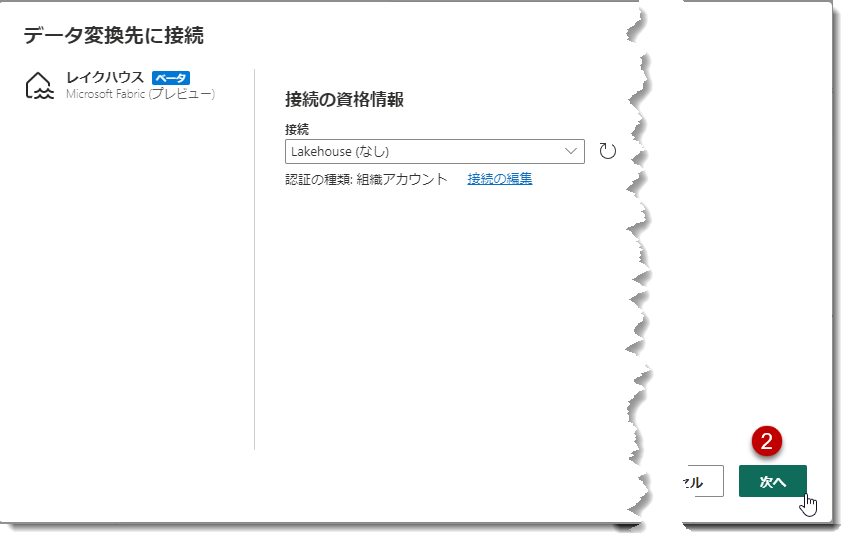
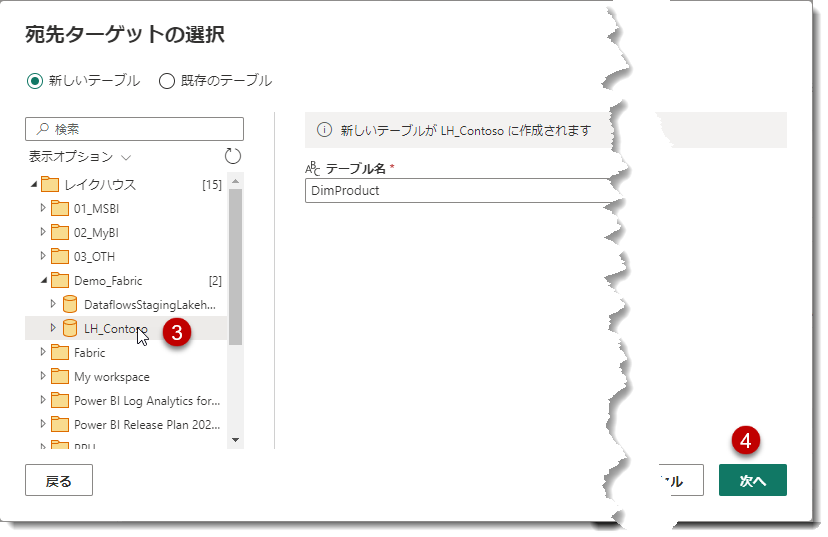


流れ作業の中で、注意が必要な点は①のステップです。このステップでは、複数のテーブルをまとめて選択し、Lakehouseを指定することができないという点に留意してください。したがって、DimProduct以外のテーブルに関しては、同じ作業を繰り返す必要があります。これはFabricがパブリックプレビューになる前から改善が求められている項目の1つであり、今後に期待したいところです。
全ての同期先を設定し終えたら、「公開」をクリックします。これでデータフローからLakehouse(LH_Contoso)へデータがロードされるようになります。。。のはずですが、実際には更新は以下のように失敗してしまいます。
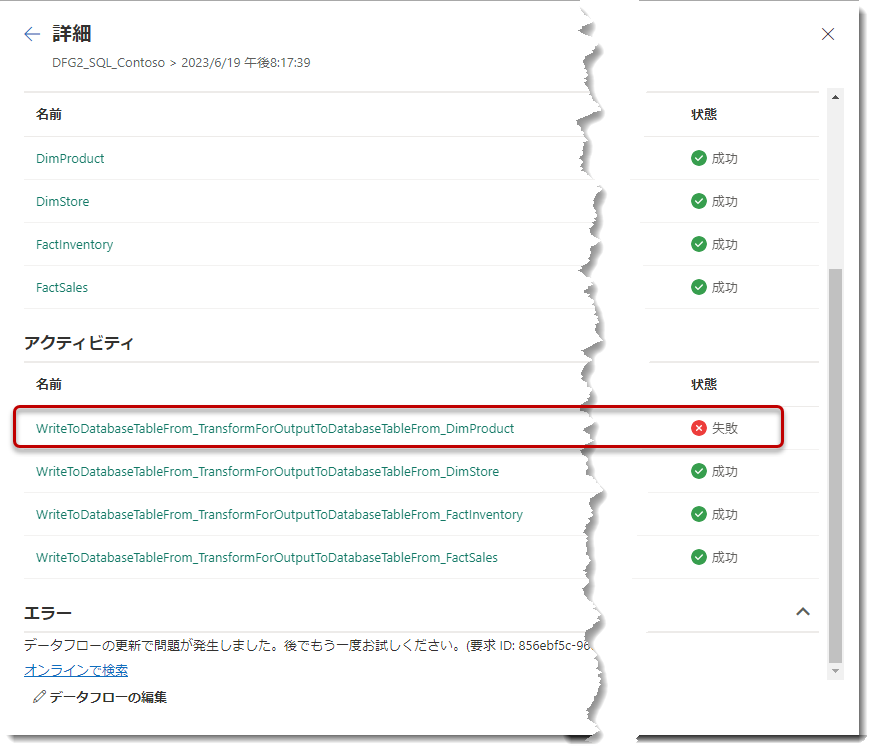
Fabricはパブリックプレビューですが、Dataflow Gen2はやや不安定な部分があるようです。こちらは既知の問題ですが、2023年6月19日時点では、
- On-premise data gatewayが必要なオンプレデータを使った場合
- Dataflow Gen2にロードするだけでは更新に支障なし
- Dataflow Gen2から「データ同期先の追加」を選択して更新した場合、更新は失敗
となるようです。上記のエラーを見ると、DimProductの書き込み操作が失敗しているようです。この問題を確認するために作成したLakehouseであるLH_Contosoを確認してみると、DimProductのみが読み込まれていないことがわかります。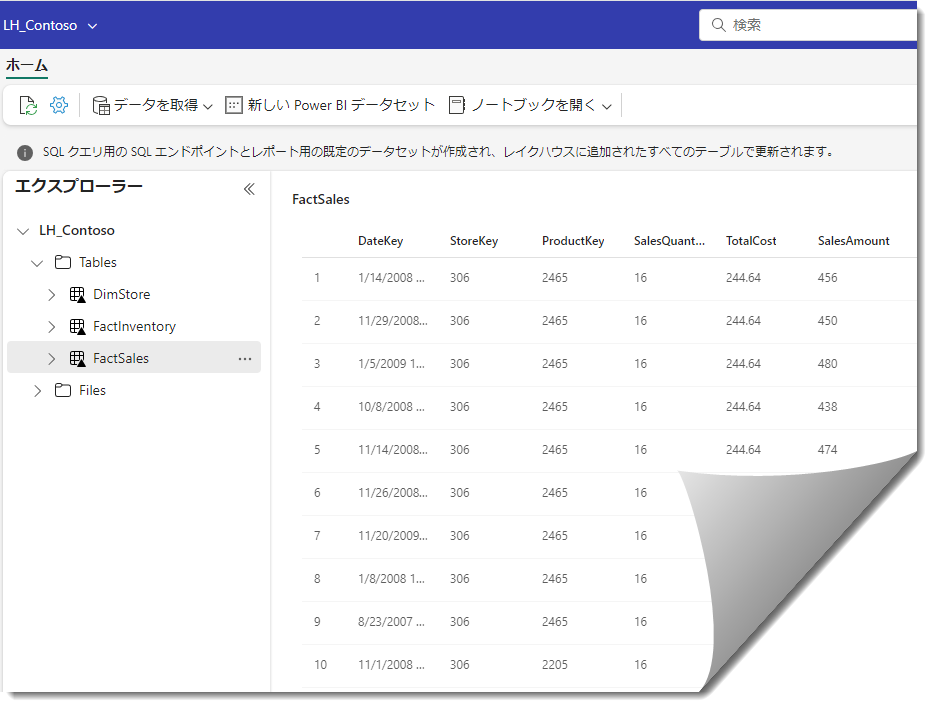
この問題も既知の問題であり、製品チームは認識しています。ただし、具体的な改善の時期や予定については現時点では明確ではありません。
追記: 2023年6月30日時点、どうやら上記更新エラーは改善され、オンプレミスSQLデータベースからDataflow Gen2へ直接データをインポートして、LakehouseやWarehouseへロードするできるようになったようです。
従って、ご自身の環境で上記更新が失敗した場合に限り、下記やり方を試して頂きたい。
まず、Dataflow Gen2からデータフローのスキーマーファイルをエクスポートします。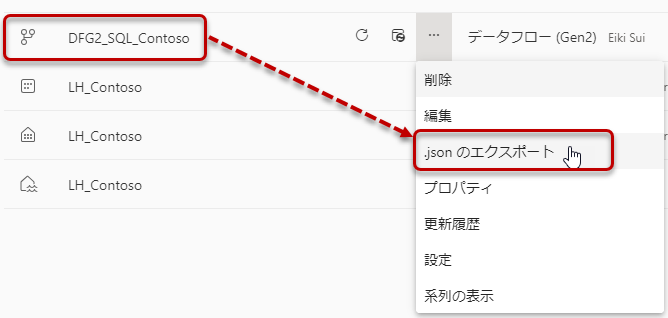
苦肉の策ですが、以下のようなアーキテクチャ(Dataflow Gen1をソースとしてGen2に読み込む)に組み直します。
ダウンロードしたJSONファイルを開き、nameの部分をDFG1_SQL_Contosoに変更(JSONファイルの名前も同様に変更)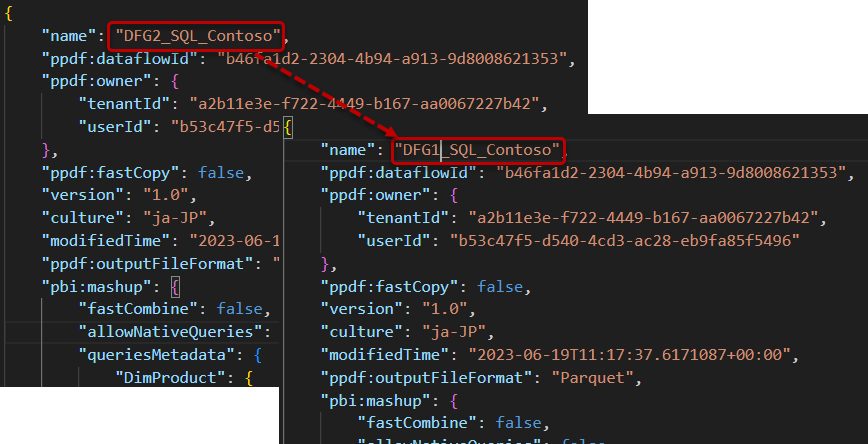
LH_Contosoにある全てのDeltaテーブル(テーブルに▲が付く場合、Delta Parquetフォーマット)を削除。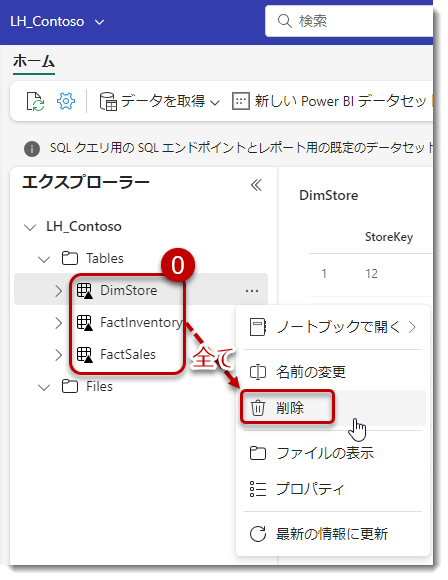
Dataflow Gen1(データフロー)を読み込む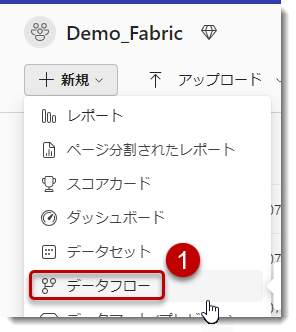
モデルのインポート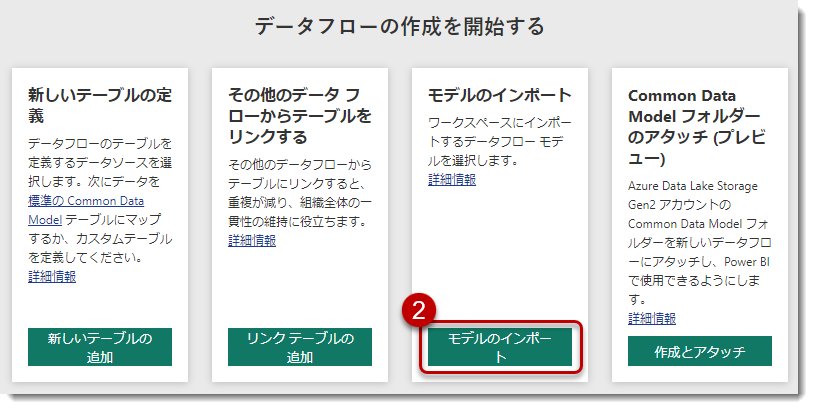
先程のJSONを読み込む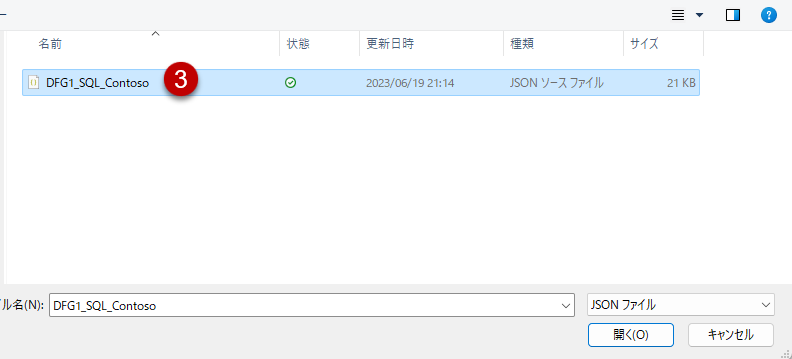
ワークスペースに戻り、DFG1_SQL_Contosoを選択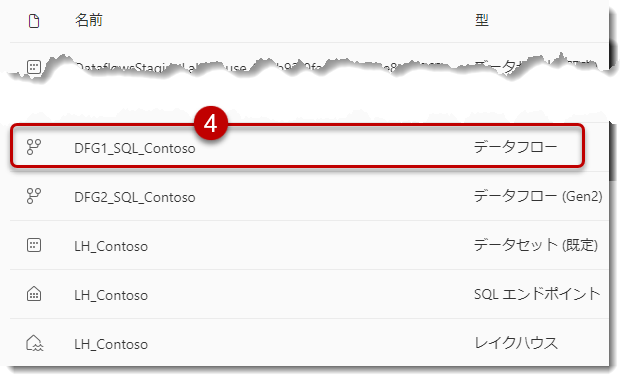
Dataflow Gen1の画面となりますので、「テーブルの編集」をクリック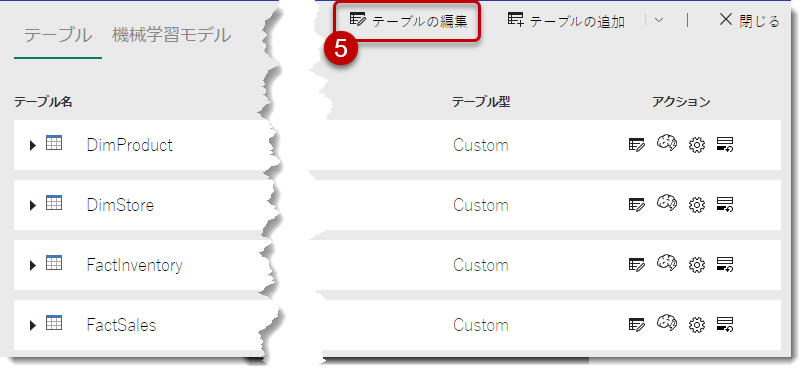
Power Queryエディタが開きますので、不要なクエリを全部削除。なお、こちらはData Factoryに関する既知の問題ですので、今後の動きに注目したいところです。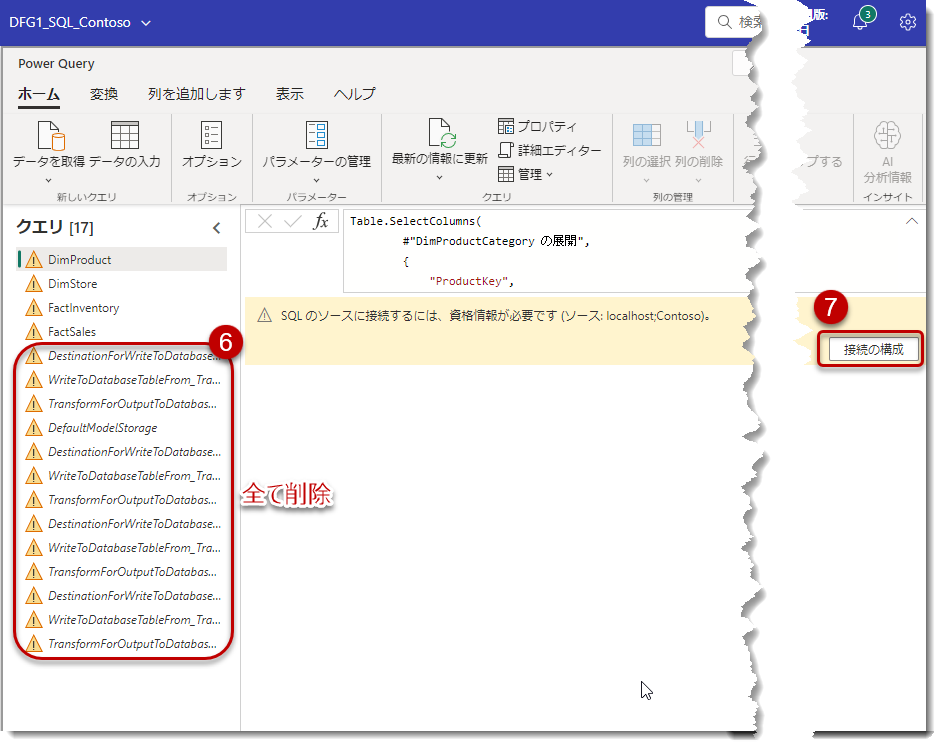
「接続の構成」>「認証の種類」を再度設定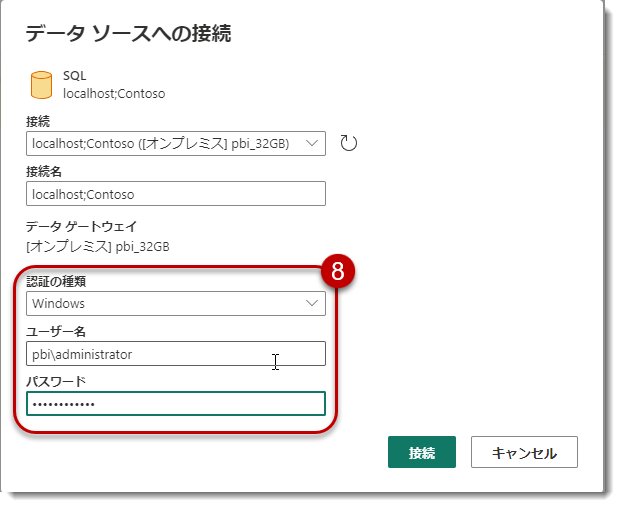
「接続」>Power Queryエディタに戻り、「保存して閉じる」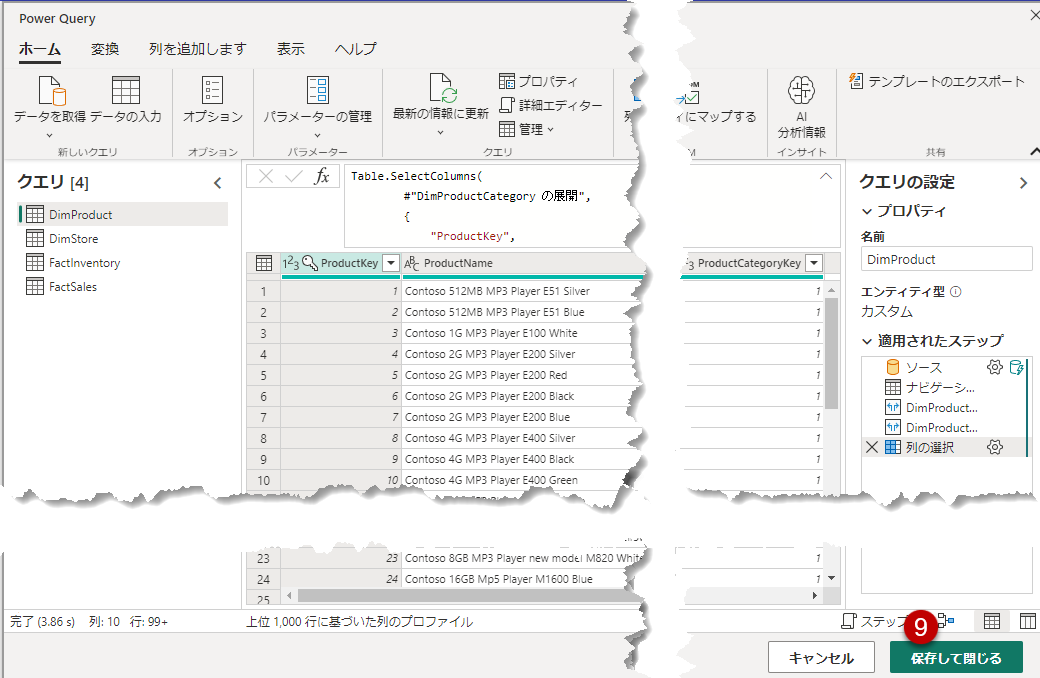
「今すぐ更新」をクリック
ワークスペースに戻り、更新履歴を見てみる
Dataflow Gen2だけの更新は4分弱であったのに対して、Dataflow Gen1は2分という結果になりました。通常はGen2のほうが早いと思われるかもしれませんが、実際には様々な要因(コンピュートエンジンやDelta Parquetフォーマットへの変換処理等)によって、一概にGen2がGen1よりも早いとは限りません(むしろ、Deltaフォーマットへの変換作業が行われるため、遅いことが普通かもしれません)。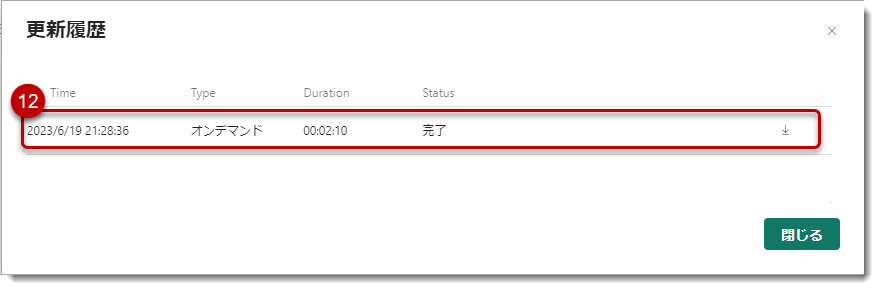
DFG2_SQL_Contosoを開き、全てのクエリを一度削除します。
データフロー(Dataflow Gen1)を選択
認証を行い、次へ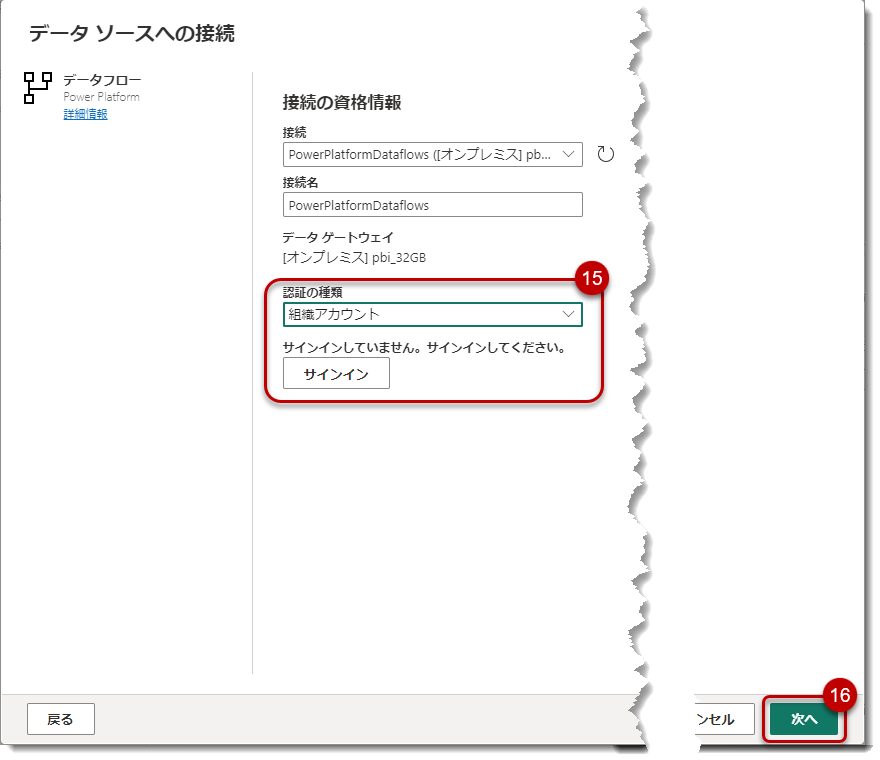
Dataflow Gen1で作成した「DFG1_SQL_Contoso」のテーブルを全て選択し、「作成」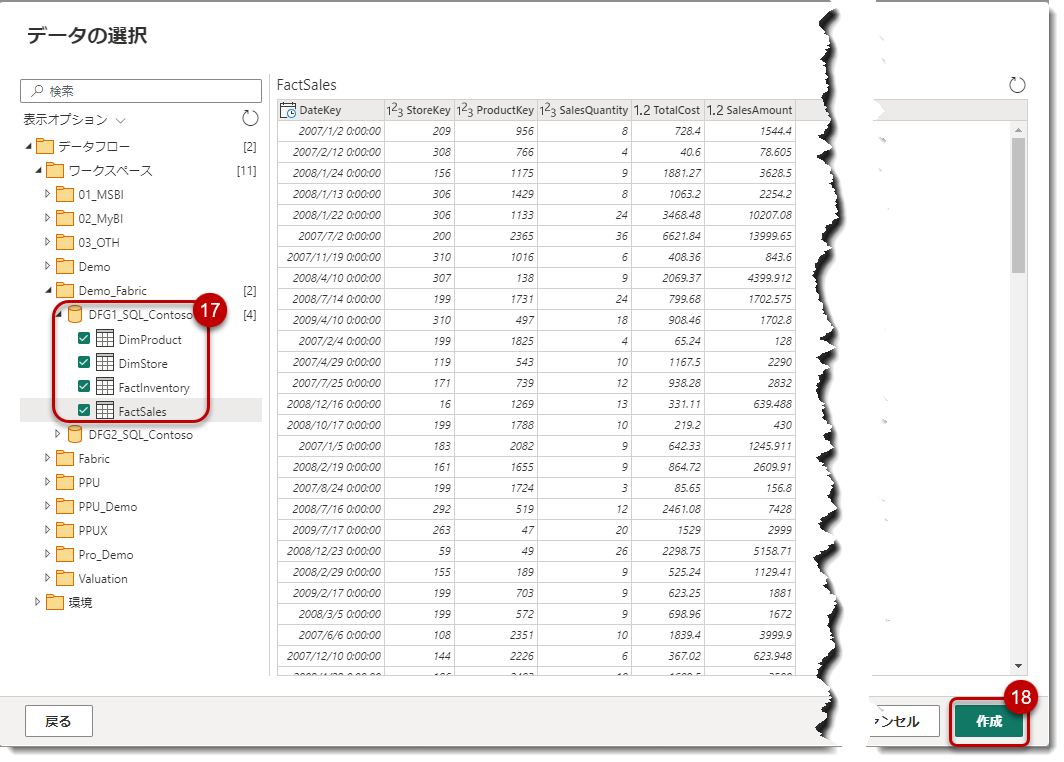
全てのクエリの同期先をもう一度指定し、「公開」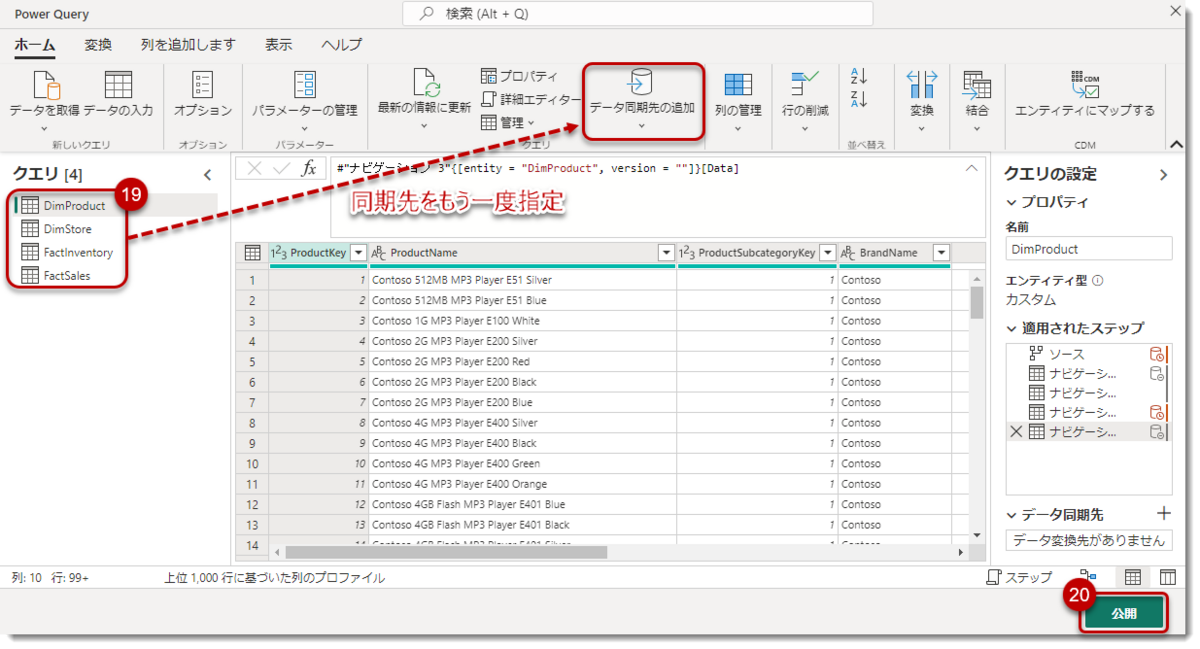
なお、手順0で削除したテーブルが残っていた場合、以下のようなメッセージが出現することはありますが、時間を少し置いてください。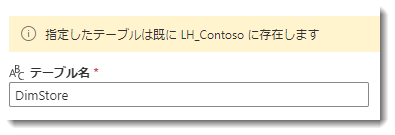
「公開」をクリックするとDataflow Gen2がもう一度更新されるようになります。失敗する可能性もありますが、先程とは違い、更新が成功しました。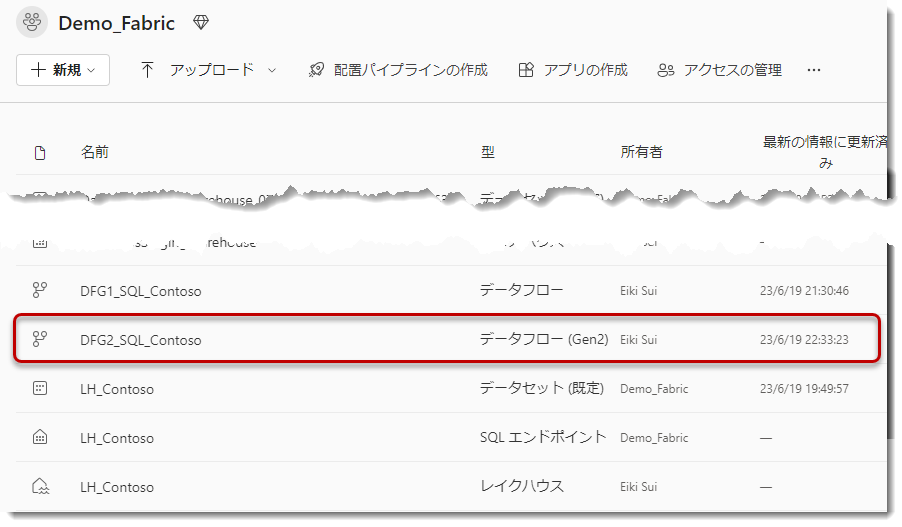
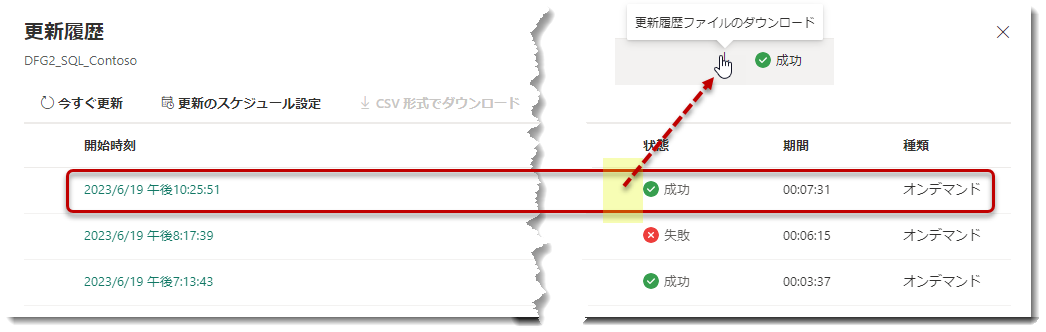
LH_Contosoを見てみます。「正体不明」という言葉が出てしまい、一瞬ドキッとしますが、更新ボタンをクリック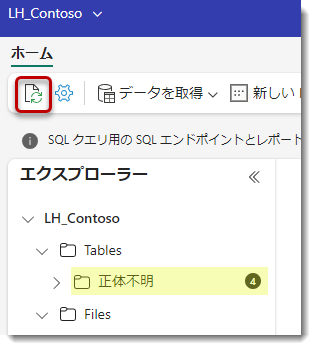
無事、全てのデータがDelta Parquetフォーマットで読み込まれたことが確認できました。
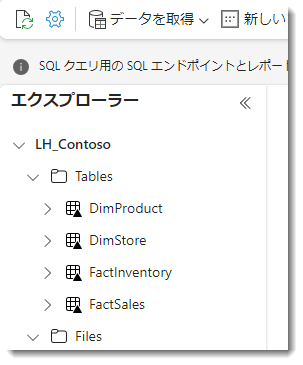
4. Dataflow Gen1 => Datafloe Gen2参照時のエラー対処
上記Dataflow Gen1をソースとして、Dataflow Gen2でデータを参照する際、下記のエラーが発生する可能性があります。
Access token has expired resubmit with a new access token(中略)
発生条件は不明ですが、各テーブルの結果が表示されなくなります。
Dataflow Error: Access token has expired resubmit ... - Page 2 - Microsoft Fabric Community
既に上記より報告があるようですが、対処法は以下の通り。
- エラーが発生したデータフローから、新しいデータフローを作成
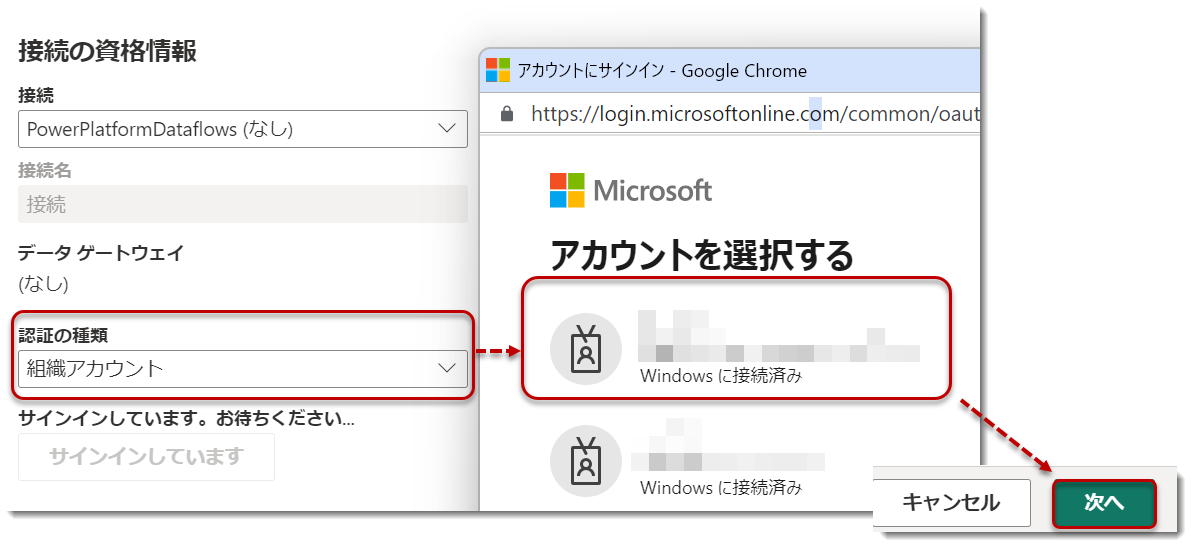
- 接続の詳細で "接続の編集 "をクリックし、サインイン
- エラーが発生したデータフローと同じワークスペースで、ランダムなデータフローを選択し、作成
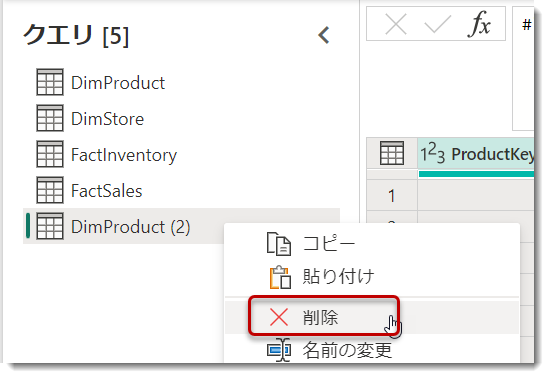
- 下図のように、選択されたテーブルが追加されるが、しばらくすると上のエラー発生となったテーブルが通常に戻るので、ランダムに作成したデータフローを削除
これにて一件落着ですが、Dataflow Gen1からGen2へ読み込むため、面倒ですね。Dataflow Gen2が問題なく更新できるのであれば、Gen1を利用しないほうが良いと思いますが、頻繁にデータソースへの問い合わせが発生する場合やソースシステムが遅い場合、Dataflow Gen1でワンクッション挟むやり方が良い場合もあるでしょう。
最後に
Fabricを実際に使用してみると、まだまだ予期しない動作が多く、望んだ通りに機能しない部分が多いことに気付くかもしれません。パブリックプレビューの目的は、以下のようなことを実現するためです。
- バグの発見
- 使い勝手や機能性に関するフィードバックの提供
- Fabricの検証とPoC(概念実証)
- 最新テクノロジーの体験とアーリーアダプターとしての参加・貢献
今回はセルフサービスBIユーザーがFabricを試した場合に直面するであろう「躓きポイント」について取り上げましたが、次回はPower BIの可視化に際して重要な日付テーブルをショートカットという機能で追加していくやり方を見ていきたいと考えています。
*1:Software as a Serviceの略
*2:Fabricはレイクファースト(Lake-first)、レイクセントリック(Lake-centric)という概念であり、まずはLakehouseを作り、Lakeを中心に作業を行っていくことを意味します
*3:旧Power BI CATであり、Fabricの登場を機にFabric CATに改名。CATはCustomer Advisory Teamの略で、Fabric全般に対するテクニカルアドバイザリーを行うチーム。Microsoftの製品チームの一員であり、Power BIを含む全てのワークロードに対するフィードバック収集及びQ&Aを行う
*4:データのためのOneDrive
*5:公式Docsでは「項目」という表現、少し昔では「アーティファクト」という表現が使用されていた
*6:SQL Serverの権限借用(Impersonation)は、ユーザーが特定の権限を持つ別のユーザーとして操作する機能です。これにより、ユーザーは他のユーザーの権限を借りてデータベースにアクセスしたり、操作したりすることができます