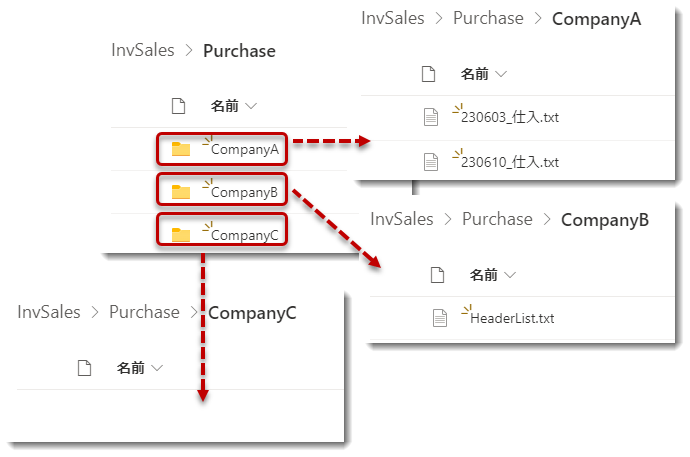
SharePointドキュメントライブラリのフォルダをフォルダツリーの状態にして管理したいというリクエストがありましたので、そのやり方について少し研究してみました。Power BIで可視化させるためにはデータを親子階層(Parent-Child Hierarchy)で持っておくことが重要ですが、今回の事例は以下のようなイメージとなります。
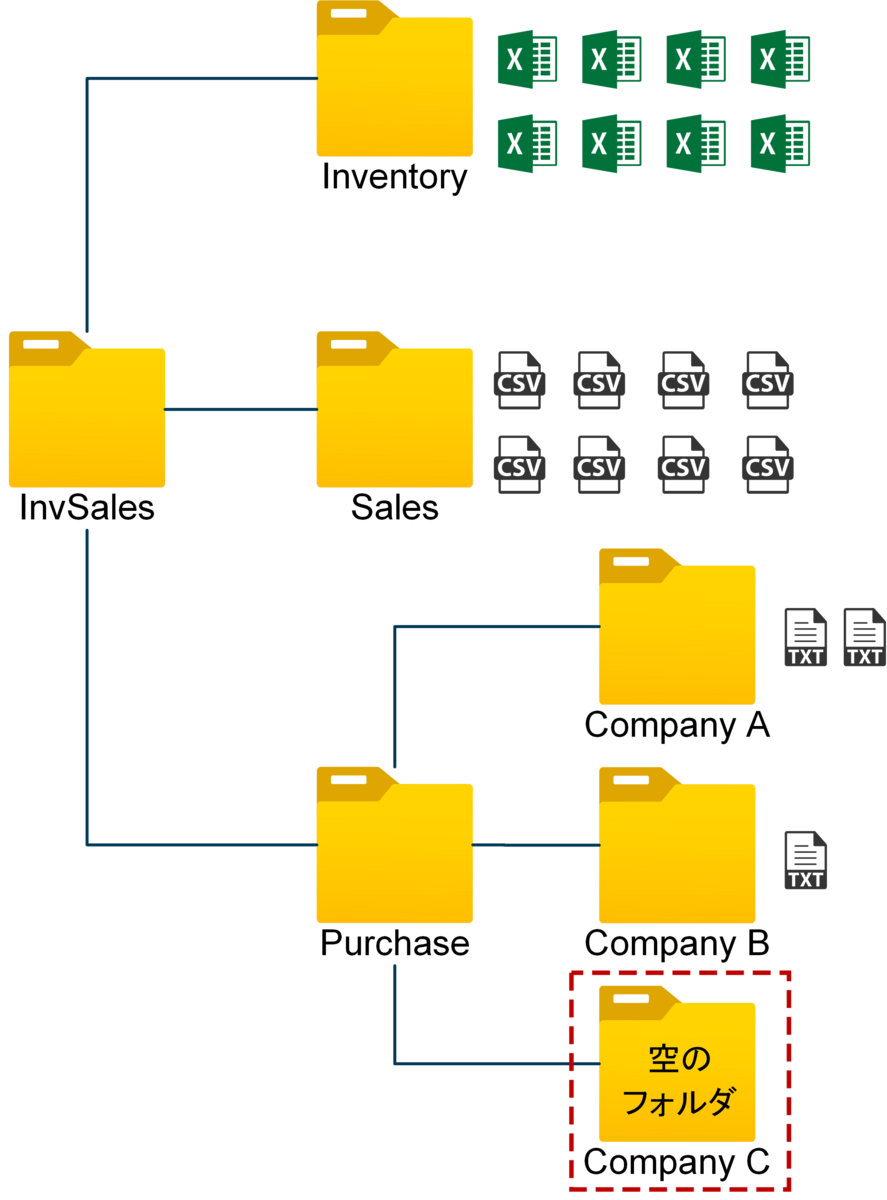
上記フォルダ構造をPower BIで可視化を行い、例えば以下のような形で可視化していきます。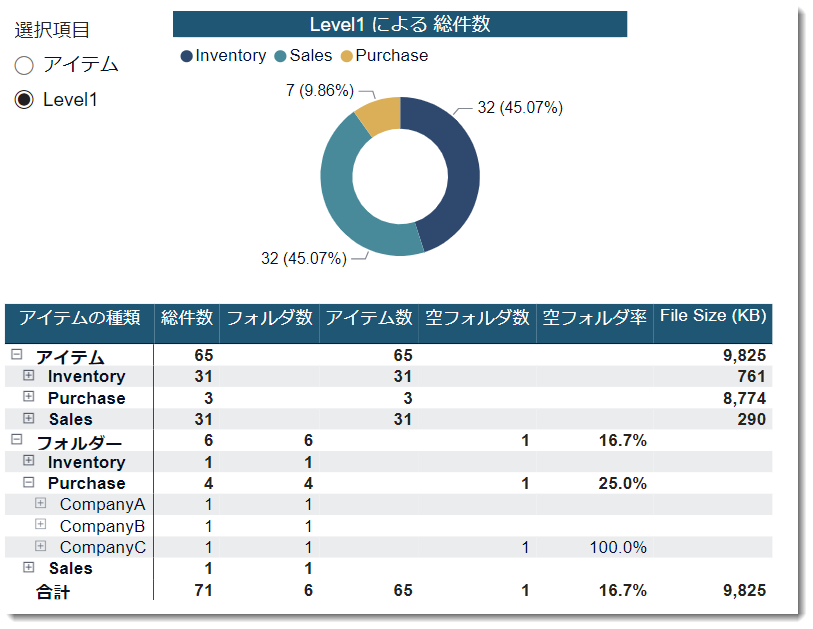
pbixファイルだけ欲しい人は一番下までスクロールしてください。
サンプル事例
- 要件定義
- フォルダ数・ファイル数・空白フォルダ数等の把握
- Power BIで可視化
Power Queryを使用してフォルダ内をスキャンし、対象となるファイル及びその数をカウントすることをイメージしてもらうと分かりやすいでしょうが、少し問題があります。
- 通常のモデリングとは異なり、親子階層(Parent-Child Hierarchy)が必要
- 空のフォルダまで取得する必要がある
- フォルダーの場合、親フォルダも1としてカウントする
2番はSharePoint.Contentを使用すれば空のフォルダまで取得することは可能ですが、階層別に展開を行う必要があるため、その処理が非常に面倒です。
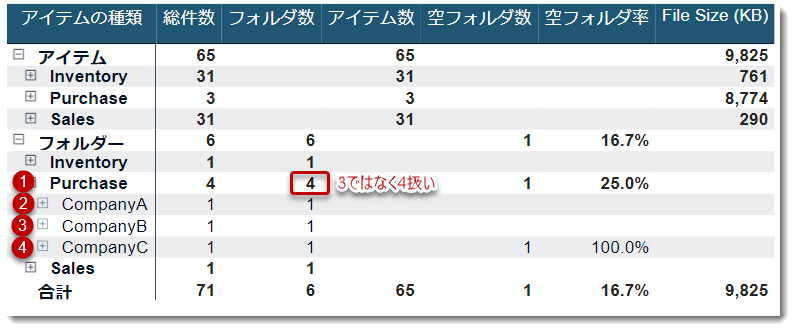
3番の留意点については上図のように、通常はPurchaseのサブセット(Company A~Company C)の数字合計(3)ではなく、親フォルダ(Purchase)もカウントするため、数字が4となります。
このように、通常のPower BIの集計ではこのような数字を算出することができませんので、モデリングを工夫する必要があります。
ちなみに、SharePoint.ContentやSharePoint.Folderといった関数を使用して、階層内のファイルやフォルダ情報を取得することは可能ですが、複数のフォルダが異なる階層で存在することから要件を満たすのは難しい状態です。また、これら2つの関数についての留意点については下記Kagataさんの記事を参考にすると良いでしょう。
ソースデータの取得
改めてメタデータの取得が関門となりますが、運よくSharePointにはこれらの情報をExcelにエクスポートする機能があり、今回はそれを使用します。以下、その手順となります。
- Microsoft 365へサインイン
- SharePointを選択

- 可視化対象のフォルダへナビゲート(今回ではInvSales)
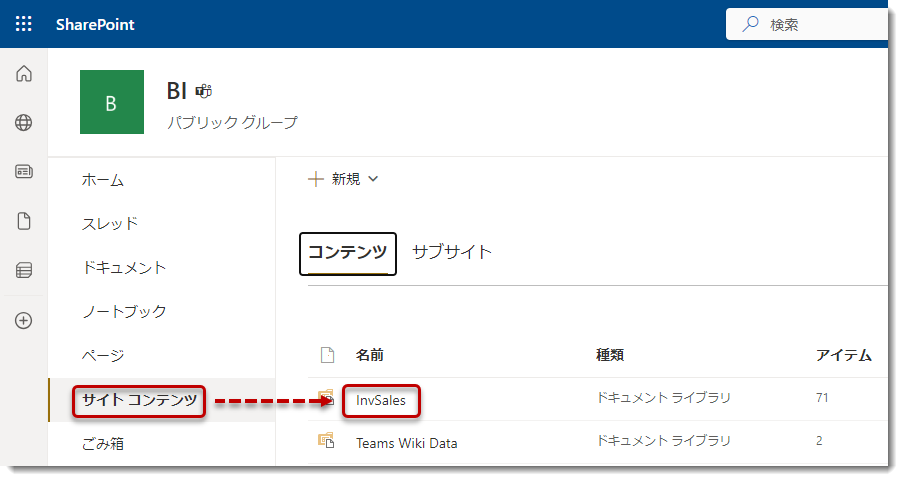
- フォルダ・ストラクチャを確認。Purchaseフォルダには更に3つのフォルダが存在

- これら3つのフォルダのうち、Company Cだけが空のフォルダ
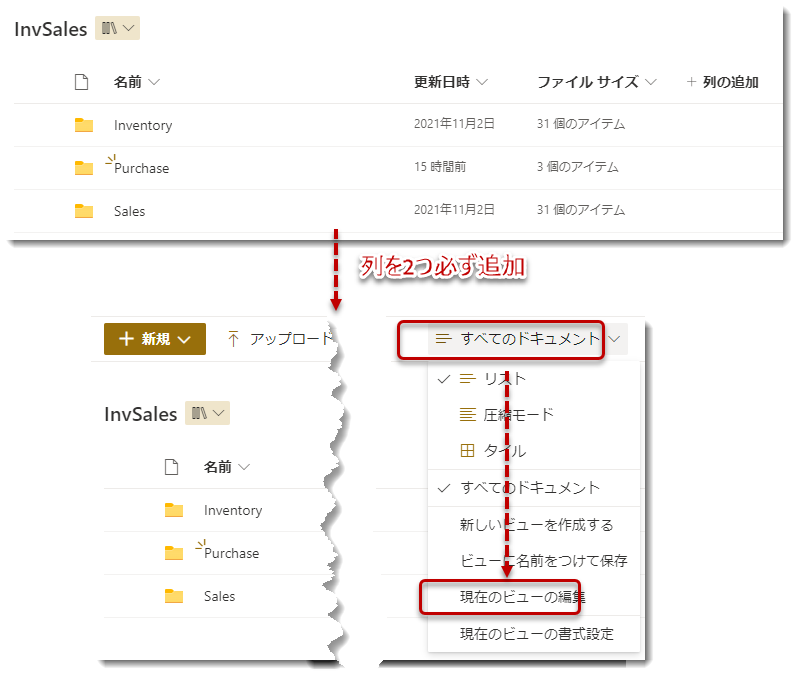
- 列を追加するため、「すべてのドキュメント」>「現在のビューの編集」
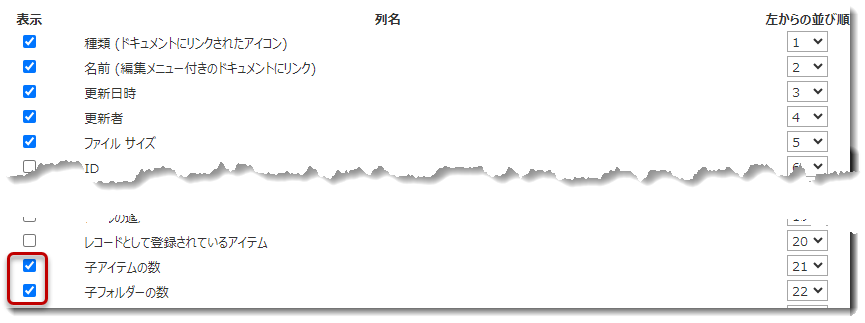
- 子アイテムの数と子フォルダの数を追加(その他必要な列があればそれらも追加)
- 列が追加されたことを確認

- 「・・・」より、「Excelにエクスポートを選択」。Excel Web Queryファイルがダウンロードされるため、それをクリック

- Excelが立ち上がり、以下の通知が出現しますが、「有効にする」>そのままOK
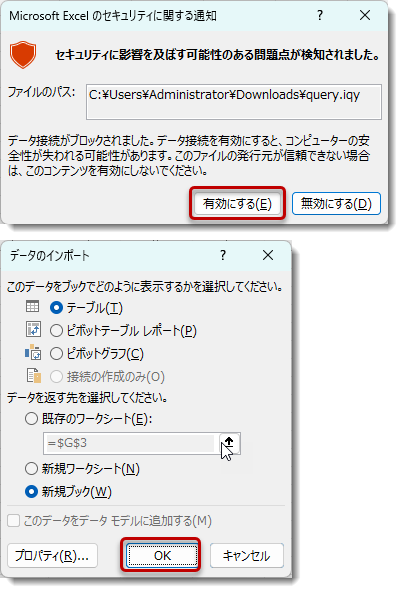
- 一番上の親フォルダの直下にある全てのフォルダとファイル情報がExcelテーブルとして出力されます。このテーブルがデータソースとなりますが、SharePointにリンクされていますので、いつでも右クリック > 更新(もしくはセルを選択した状態で、Alt + F5)で最新のデータを取得できます
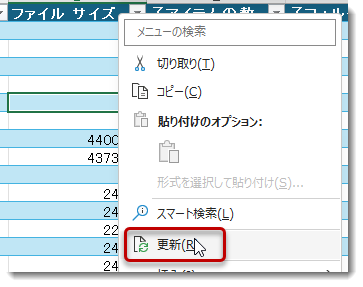
これでソースデータの準備が完了しましたので、このExcelを所定の場所に保存し、新しいPower BI Desktopを立ち上げてPower QueryとDAXを使って、親子階層を作っていきます。
親子階層(準備)
- Dataクエリ
上記クエリを実施した場合、Excelに元々あった8列が12列に増えます。
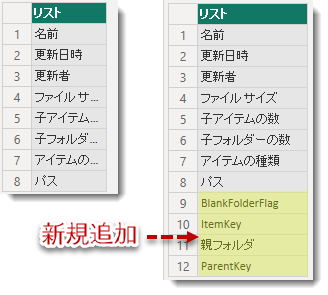
追加された列は以下のような意味があります。
- 列「BlankFolderFlag」
適用したステップ「BlankFolderFlag」で、以下の数式を使用して算出されています。
= if [アイテムの種類] = "フォルダー" and List.Sum({[子アイテムの数], [子フォルダーの数]}) = 0 then 1 else 0
この式の意味するところは、「アイテムの種類」がフォルダーであり、かつ、「子アイテムの数」と「子フォルダーの数」が両方ともゼロの場合、1を返し、それ以外の場合は0を返すことです。この列は空白フォルダの数を算出するための列であり、1となっているフォルダ=空白フォルダとなります。 - 列「ItemKey」
適用したステップ「ItemKey」は単純にPower QueryでIndex列を追加しただけのものであり、ユニークキーを設定したものです。ソースデータは全てのフォルダとファイルを含む抽出データであり、これらの項目には必ず親フォルダが存在します。親子階層では「名前」という列に対してユニークキーを付けることが必要であり、便宜的にTable.AddIndexColumn関数を使用して連番を付けています。したがって、読み込んだデータが合計100行あった場合、1~100までの連番が上から順番に振られることになります。 - 列「親フォルダ」
適用したステップ「ExtractParent」は重要なポイントとなります。
= Table.AddColumn(ItemKey, "親フォルダ", each let splitパス = List.Reverse(Splitter.SplitTextByDelimiter("/", QuoteStyle.None)([パス])) in splitパス{0}?, type text)
一見すると、この式は難しそうに見えますが、実際にはPower QueryのAI機能である「例からの列」を使用しています。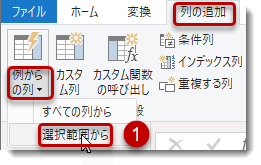
列「パス」を選択した状態で「選択範囲から」 > 列名に「親フォルダ」、その下に「パス」の一番右のフォルダ名Purchaseを記入してみます。すると、無事にフォルダ名を抽出できましたが、階層が深いフォルダを抽出できていないようです。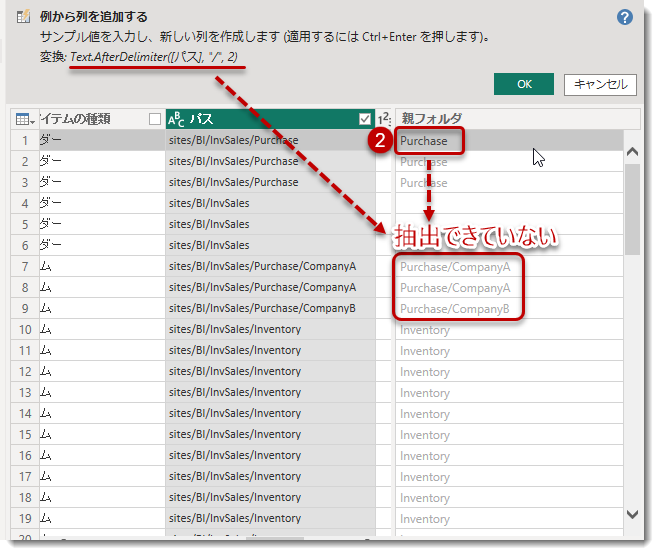
続けて、CompanyAを入力していきます。すると一瞬でしたが、全て抽出できたかと思ったものの、実際には「一番右から8文字を抽出せよ」という結果になってしまいましたので、Inventoryがnventoryとなってしまいました。

諦めずに、最後はnventoryをInventoryで入力し直すと、難しそうな関数が挿入され、ようやく全ての親フォルダを抽出できました。
なお、この式はTable.AddColumn関数の中にさらに定義したカスタム関数を入れたもので、"/"をベースにテキストを分割し、抽出されたキーワードの順番を逆転させ、本来は一番最後のキーワード(フォルダ名)を一番上に持ってくることでそのキーワードを選択しやすくするための処理を行ったものとなります。「例からの列」を使用すると自分で一から考える必要がないため、このようなケースで非常に便利な機能となります。 - 列「ParentKey」
適用したステップ「MergeItemKey 」ですが、
= Table.NestedJoin(
ExtractParent, {"親フォルダ"}, ExtractParent, {"名前"}, "ExtractParent", JoinKind.LeftOuter
)
セルフマージというテクニックを使用して、抽出したばかりの「親フォルダ」列と同じ「Data」テーブルの「名前」列に対してマージさせて、結果を抽出してきます。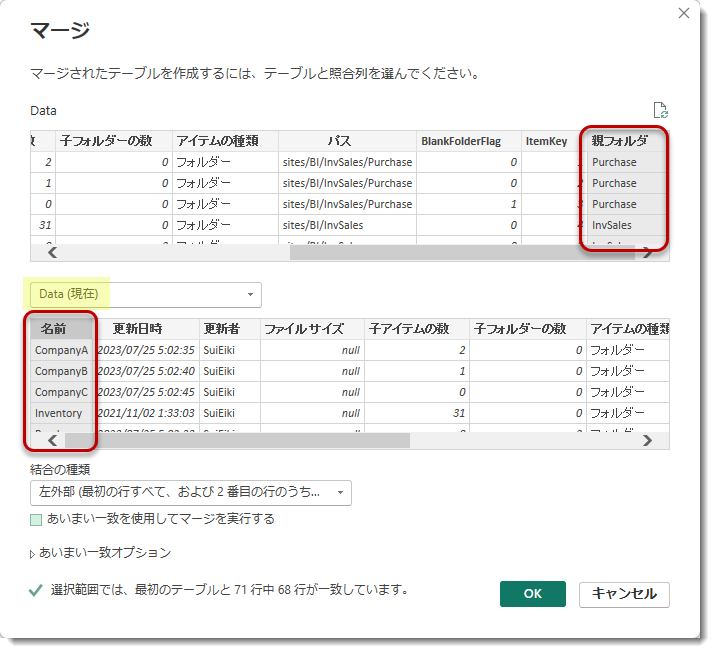
結果的に「名前」にある項目(フォルダ名、ファイル名)の親フォルダをここで抽出してきていることになります。
※注意
ここで名前が重複するフォルダが別々の階層に存在した場合、このクエリは壊れてしまいますので、Power BIビジュアルも正常に表示されなくなります。重複フォルダが存在する場合、最後のステップ「CheckDuplicates」にて確認を行い、重複を避けるように変更する必要があります。デモ用データでは重複がないという前提で作成されていますが、実際には同じ名称のフォルダが存在する可能性は十分にあるため、フォルダマネジメントも行うと良いでしょう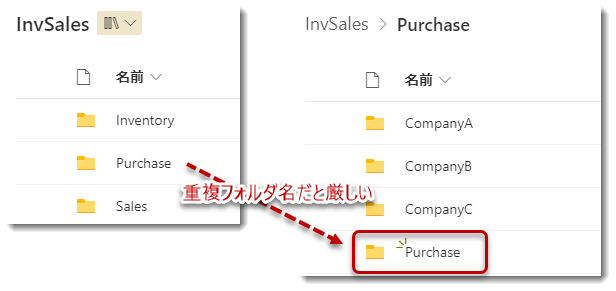
これにてPower Queryでの作業は終了しました。最後に追加されたParentKeyですが、先述の通り、Table.AddIndexColumn関数を使用して全ての項目(フォルダ名、ファイル名)に対して付与したユニークキーのうち、フォルダに関するキーをだけを抽出したものとなります。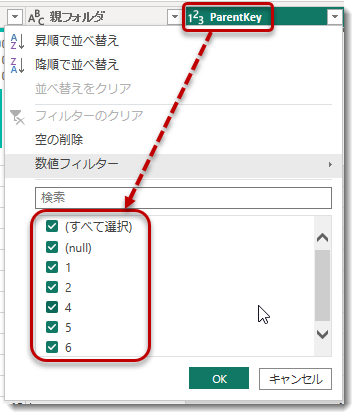
親子階層(構築)
DAX式で計算列を追加する際、SQLBIのDAX Patternの記事を参考にしていますが、内容をほぼそのまま活用しています。
Power BIを学んでいる人の中には、「計算列のご利用は計画的に!」というルールがあるのを知っている人も多いと思いますが、今回はそれを使用しないと実現できないものとなります。
SQLBIの記事のままに進めていけば、最終的にはPathKeyから右の列が追加されるようになります。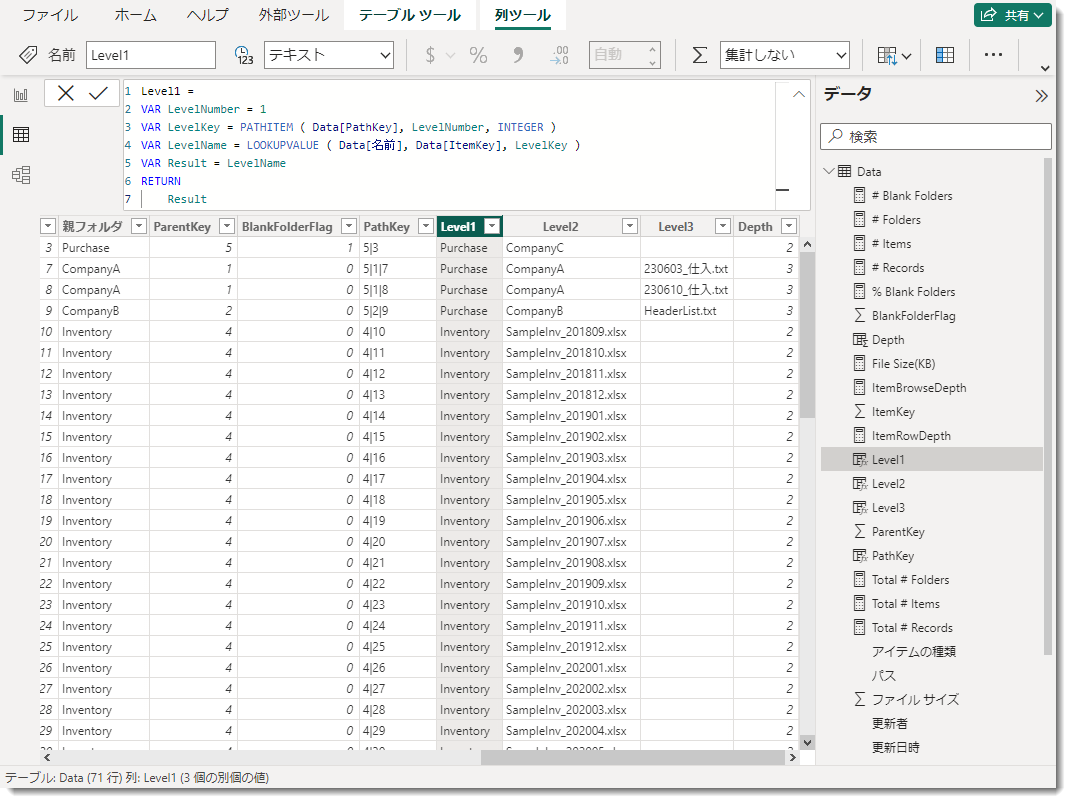
なお、PathKeyもDAX関数を使って計算されたものですが、Data[ParentKey]は必ず数値型でないと機能しません。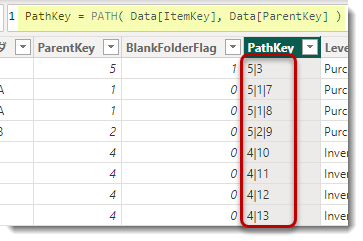
以下は使用されているメジャーと説明であり、下記サンプルファイルを見てもらえれば仕上がりを確認することができます。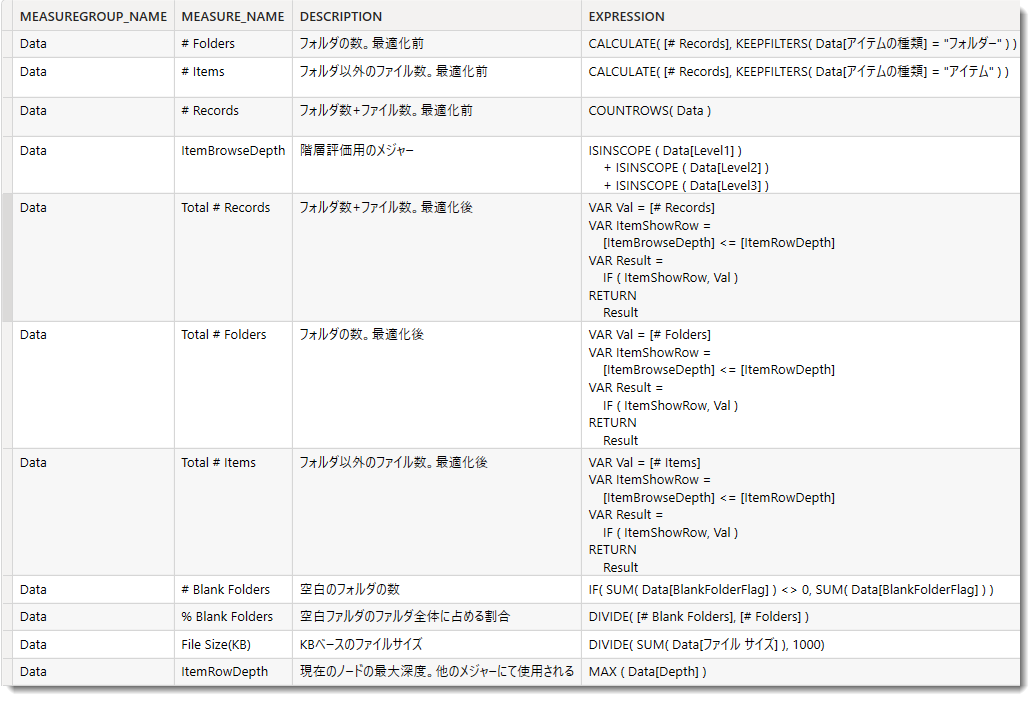
サンプルファイル
>>Download
最後に
親子階層のモデリングは組織図などを可視化するために使えるだけでなく、今回のようなフォルダ管理にも活用できるものです。あまり使う機会がないロジックかもしれませんが、一度理解すると非常にパワフルな機能であると感じるでしょう。