今回は、DAXの生みの親であるJeffrey Wangさんが提唱するDAXに関するベストプラクティスについて、紹介したいと思います。YouTubeの内容をまとめたものですが、かなり参考になると思います。
DAXについて
以前、2回にわたりJeffreyによるDAXの概念についての記事をまとめました。
Jeffrey WangによるDAXエンジンの解説① - テクテク日記
Jeffrey WangによるDAXエンジンの解説② - テクテク日記
これらの記事は直近10ヵ月間ほとんどアクセスがなく、全150記事の中で121番と132番目のアクセス数が低い記事です。Power BIの中上級者向けコンテンツとなっていることや、ブログにアクセスする読者の多くが検索エンジンを利用していることを考慮すると、やむを得ない状況だと考えています。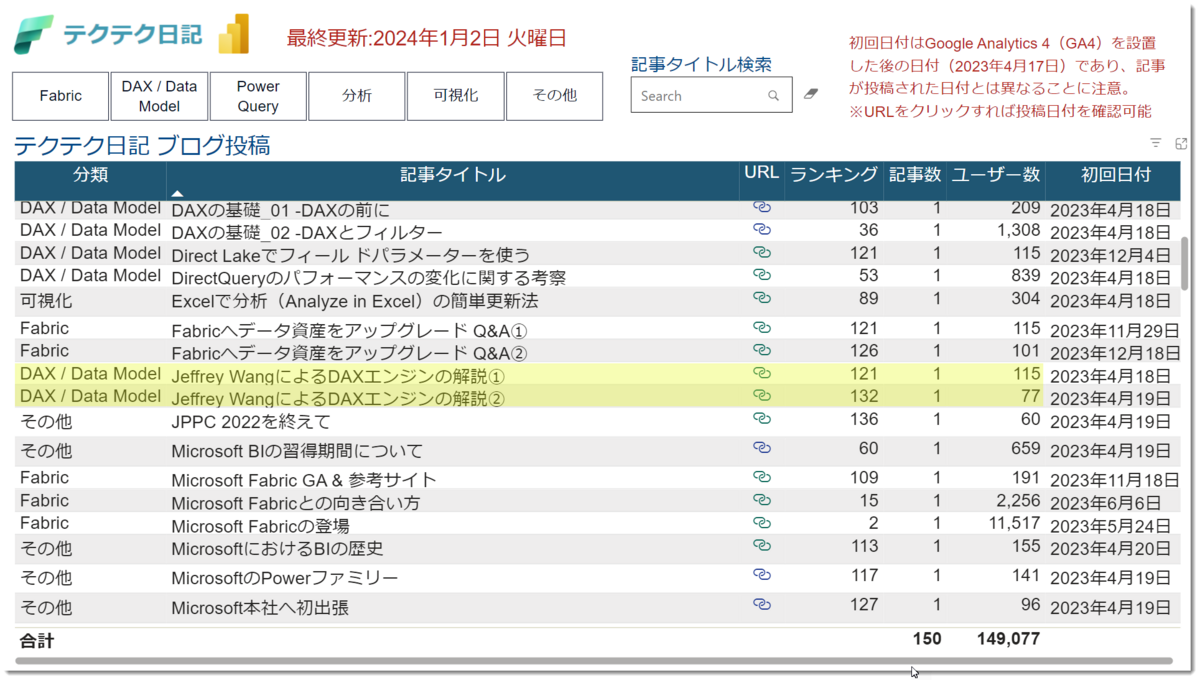
https://aka.ms/techtech2
しかし、DAXをしっかりと習得したい場合は、これらの記事を目を通すことを強くお勧めします。DAXは難しいのは周知のとおりですが、上記YouTubeでJeffreyは以下のように話しています。
"DAXの利点の一つは、複数の方法で同じ結果を得ることができることです。しかし、これは同時にDAXが難しいとされる理由の一つでもあります"
私は最初からDAXを習得する意思を持ちながら学んできましたが、確かにその考え方は正しいと感じます。DAXは非常にパワフルで自由度が高いため、改めて考えると、これが実際にDAXを難しくしている一因であることが理解できます。
DQV(DAX Query View)の登場
Power BIの開発者たちから初心者がDAXを学ぶ上での大きな進歩として、DQVの登場が称賛されています。DQVを活用することで、DAXを学ぶ機会が多く提供されており、私もそれをシリーズでブログにまとめています。一方、JeffreyはDQVの活用法の1つとして、『計算テーブルを一時的に保持して、データモデルを"汚染させず"に結果を出力したい場合』を非常に参考になる方法として述べていました。
DQVの登場は間違いなくPower BIユーザーにとって大きなプラスとなりますが、セルフサービスBIユーザーがその恩恵を受けるには、よりDAXについて理解を深める必要があると考えられます。
と言われていますが、SQL文やDAX Studio等でDAXを書くことに慣れている人にとっては、DQVの登場は非常に心地よい機能の拡張であると感じられるでしょう。
DQVの登場により、モデリングが得意な人はPower BI Desktopを離れることなく、DAXで計算された結果をEVALUATEステートメントで確認できるようになりました。また、既に定義されたセマンティックモデルの内容(例: 定義済みメジャー、リレーションシップ、テーブルと列の関連性、その他のメタデータ情報など)を確認することもできるようになりました。
ここでは詳細は省きますが、JeffreyによるDQVで使用される頻度の高い関数について以下見ていきたいと思います。
① SUMMARIZECOLUMNS
- SUMMARIZECOLUMNSは、最初のデータ行を取得し、その後の変換の基盤となります。これは、最終的なクエリの出力を形作るためのパターンであり、製品チームによって推奨される優先されるアプローチです。
- すべてのPower BIビジュアルでは、SUMMARIZECOLUMNS関数がコアの結果を取得するための基本的なステップとして使用されます。初期データは__DSOCore変数に格納されます。
- ビジュアル固有の後処理は、初期の__DSOCoreデータを最終的なクエリ結果に変換し、クエリ内のすべての行セットが__DSOCoreから派生しています。
- 現在、SUMMARIZECOLUMNSには問題のあるAuto-exists (動画)セマンティクス*1があり、グループ化された列、フィルタ、およびメジャー式の特定の相互作用に影響を与えます。
- 現時点では、メジャー式でSUMMARIZECOLUMNSを使用することはできません。
- この制約により、ユーザーは代替のクエリパターンを検討することが奨励されています。
SUMMARIZECOLUMNSの概要について述べたものですが、ポイントは以下の通りです。
- DQVでDAXクエリを出力する際、一般的には最終的にSUMMARIZECOLUMNSを使用することが推奨されます。これは、ユーザーが最も混乱しにくく、直感的に理解しやすい数式(セマンティック上のアプローチ)であると同時に、SUMMARIZECOLUMNSは他のアプローチ(例: ADDCOLUMNS + SUMMARIZE等)と比較して)その副作用(空白に対する処理の違い等)が少ないからです。
- Power BIビジュアルのDAXクエリをパフォーマンスアナライザー等で取得した場合、初期データが__DSOCoreに格納されています。SUMMARIZEはこれをベースに最終的にDAXメジャーを含むDAXクエリを評価を行っていきます。

- SUMMARIZECOLUMNSは構文がシンプルで便利ですが、残念ながらまだDAXメジャー(メジャー式)で使用することはできません。たとえば、[SampleDAX_SUMMARIZECOLUMNS]というメジャーは、Category = Fabricでフィルターされたブログ訪問ユーザー数を計算する式ですが、このクエリを実行しようとすると構文エラーが発生します。

一方、FILTER式を使ったDAXメジャーは問題なく計算結果を算出することができます。
SUMMARIZECOLUMNSというDAX関数の制限の1つ(もう一つはAuto-exists)ですが、2024年はこれらの制限が解除になる可能性が高いとJeffreyは述べています。
② CALCULATETABLE + SUMMARIZE
- このクエリパターンは、Power PivotとPower View時代に起源を持ち、そのためv1クエリパターンと呼ばれています。
- SuperDAXプロジェクト*2から派生したSUMMARIZECOLUMNSパターンは、v1クエリパターンを置き換え、それに応じてv2クエリパターンと指定されました。
- SuperDAXプロジェクトは、新しいPower BIの発売直前に終了した複数年にわたる取り組みでした。
- v1パターンは、特に複雑なメジャーやモデルを含むシナリオでのセマンティクスとパフォーマンスの問題からSUMMARIZEによって置き換えられました。
- 製品チームは、グループ化を行う列の有効な組み合わせを返す場合に、SUMMARIZEを専属的に使用することを推奨しています。これらの場合、SUMMARIZEはGROUPBYよりもStorage Engineフレンドリーなため好まれます。
上記のまとめは以下の通りです。
- DAXは元々Excel Power Pivotから誕生したもので、クエリの結果を効率よく返すパターンが存在していました。
- CALCULATETABLEとSUMMARIZEを一緒に使うことがパターンの1つであったが、SuperDAXプロジェクトではこのパターンに置き換わる関数(SUMMARIZECOLUMNS等)が導入されました。例えば、以下は CALCULATETABLE + SUMMARIZEを使用したパターンで、日本以外のブログの訪問ユーザー数([Total Active Users])とブログ数([# Blogs])を抽出するクエリです。このクエリでは、①の順序で評価が開始され、②で国・年月・分類の切り口でグループ化された結果が返されます。

このパターンでは、評価の順序が留意すべきポイントであり、CALCULATEやCALCULATETABLEを使った場合、①の部分が先にフィルターが適用されることになります。また、SUMMARIZEの中にDAXメジャーを含める方法は、DAXメジャーを記述する際の悪い慣例の1つであり、推奨されません。これは、DAXを学び始めた人が間違いやすいポイントの1つであり、そのためにSUMMARIZECOLUMNSの導入が必要になった要因の一つです。 - DAXメジャーを使用しない場合、グループ化のためにはSUMMARIZEを使った書き方が推奨されます。以下のクエリは、Dataテーブルとリレーションシップが存在するdCalendarとdBlogの列を使用し、グループ化した結果を表示します。

ExpandedテーブルというDAXにおいて非常に重要な概念が暗黙に含まれており、この書き方のほうが次に説明するGROUPBYという関数よりも複数のコアで処理ができるようになり、クエリパフォーマンスが高まります。
SUMMARIZECOLUMNSはDAXクエリの処理に使用されるものであり、SUMMARIZEの限定的な代替として利用できます。一方、CALCULATETABLE + SUMMARIZEはDAXクエリの中で使用可能ですが、SUMMARIZECOLUMNSのような制約はなくとも、クエリが複雑になりすぎる場合に問題が発生することがあります。そのため、クエリを簡素化する観点からはSUMMARIZECOLUMNSの使用が推奨されています。
③ GROUPBY
- GROUPBYの関数名は、SQLに精通しているユーザーに響くため、SQLのバックグラウンドを持つ新規ユーザーに魅力的です。
- GROUPBYは、SUMMARIZECOLUMNSの結果に追加の集計を行うために導入されました。
- 集計がStorage Engineにプッシュダウンできる場合、SUMMARIZEに比べて効率が低下します。
- 基本的な集計関数のサブセットのみをサポートし、メジャーはサポートしていません。
GROUPBYのポイントは以下の通りです。
- SUMMARIZECOLUMNSは物理テーブルを読み込み、グループ化と集計を行いますが、GROUPBYはその結果を基に処理を行います。そのため、物理テーブルは存在せず、VAR(変数)として格納された仮想テーブルに対する追加の処理となります。従って、GROUPBYは集計された結果に対してさらに処理を行いたい場合に使用される関数となります。
- GROUPBYの使用はあまり推奨されておらず、可能であればSUMMARIZECOLUMNS、SUMMARIZE等の関数を使用するほうが好ましい。
④ ADDCOLUMNS
- ADDCOLUMNSは、SUMMARIZEと共に使用され、グループ化列(SUMMARIZEから取得)とメジャー列(ADDCOLUMNSを介して追加)を組み合わせることができます。
• SUMMARIZECOLUMNSの制約を回避する代替方法を提供してくれます。SUMMARIZECOLUMNSはメジャー式で使用が許可されておらず、SUMMARIZEにメジャーを直接含めることに関連する問題を解決できます。
• ADDCOLUMNSとSUMMARIZECOLUMNSの比較- SUMMARIZECOLUMNSは固有の非空(non-empty)のセマンティクスを持っています。
- 最適な形では、SUMMARIZECOLUMNSは単一のStorage Engineクエリに効率的に変換され、最良のパフォーマンスを実現します。
- ADDCOLUMNSには組み込みの非空のセマンティクスがなく、ユーザーが非空フィルタを明示的に定義しない場合、異なるディメンションテーブルからの列の"高価"なクロス結合が発生する可能性があります。
- ADDCOLUMNSは常に2つ以上のストレージエンジンクエリを生成します。
ADDCOLUMNSのポイントは以下の通りです。
- 現時点のSUMMARIZECOLUMNSの制限(メジャー内でのテーブルフィルターとして使用できない)に対処するために、ADDCOLUMNS + SUMMARIZEというパターンで一緒に使用することが多くなります。
- SUMMARIZEに直接メジャーを含めた場合の計算間違いやクエリパフォーマンスを最適化させるためにもADDCOLUMNS + SUMMARIZEというパターンが使われます。
- ADDCOLUMNSを使用したパターンでは、以下のような空白の結果が算出されることがあります。

これを防ぐためには、以下のように明示的にフィルターを適用しておく必要があります。
もしくは、最初からSUMMARIZECOLUMNSを使用します。
結果が全て同じであれば、圧倒的にSUMMARIZECOLUMNSを使った書き方がシンプルであることが分かります。 - クエリプラン(パフォーマンスに直結)という意味ではSUMMARIZECOLUMNSは1つのSE(Storage Engine)クエリを生成しますが、ADDCOLUMNSはどうしても2つ以上生成されてしまいます。以下、DAX Studioで見たその結果となります。
SUMMARIZECOLUMNS使用時
比較可能な結果を得るためのDAX式ですが、後者は複数のDAX式を評価する必要があるため、SEクエリが3つに増えてしまいました。そのため、前者の書き方の方が圧倒的に優れていることが分かると思います。 ADDCOLUMNS + SUMMARIZE 使用時
ADDCOLUMNS + SUMMARIZE 使用時
⑤ GROUPCROSSAPPLY
- GROUPCROSSAPPLYは、Power BIセマンティックモデルへのDirectQueryをサポートするために導入された新しい関数です。
- 主に内部利用を目的として設計されており、現時点ではDQVのクエリエディターでのIntellisenseサポートも、包括的な公開ドキュメントもありません(DAX Guideでも記載なし)。
- GROUPCROSSAPPLYの機能はSUMMARIZECOLUMNSに類似していますが、クラスタリング*3とAuto-existsの挙動において、より制限された構文と異なるセマンティクスを持っています。
GROUPCROSSAPPLYのポイントは以下の通りです。
- DAXを直接DirectQueryのSQL文に変換できない場合、GROUPCROSSAPPLYが使用されるようです。現在、この関数をDQVで追跡することが可能になっていますが、Intellisenseは対応していません。
- 完全にエンジンが評価するための内部で使用される関数であり、挙動としてはSUMMARIZECOLUMNSとほぼ同じですが、GroupByに使用される列をフィルターに使用した場合、必ずVALUESでフィルターを適用する必要がある点が特徴です。

なお、この関数を導入する必要があった理由は、Composite Model(複合モデル)で使用するためであり、またセマンティック的にSUMMARIZECOLUMNSとこの関数が異なっているためです。Composite Modelでは、リモートエンジンに計算をプッシュしてローカルエンジンが理解できるようにするために、ローカルモデルとリモートモデルをクエリできるようにするため、このDAX関数が導入されました。
最後に
今回、たった5つのテーブル関数(操作系関数)について紹介しましたが、1つの関数について学ぶだけでも、深く理解するには数時間かかることがあります。DAXが難しいとされるのは、こうした細かな点を理解する必要があるからでもあります。一般的な使い方をする場合、これほど深く理解する必要はないかもしれませんが、モデリングが複雑になったり、メジャー式で複雑な計算ロジックが必要な場合は、より詳しく学ぶ必要が出てくるかもしれません。自分たちのニーズに合わせてうまく活用することが重要ですが、DAXを作成している製品チームからのインプットは常に興味深いものですので、何かの参考になればと思います。
*1:DAXの文脈で使用される関数や式が、データモデル内の情報を解釈し、操作する方法やルール等の定義
*2:SuperDAXプロジェクトは、Microsoftが開発したデータ処理エンジンの強化プロジェクトです。このプロジェクトは、Power BIやExcelなどのデータ分析ツールにおいて、高速で効率的なデータ処理を可能にすることを目指していました。SuperDAXプロジェクトは、Power PivotやPower Queryなどのテクノロジーを改良し、より複雑な計算やデータモデルの取り扱いに特化した新しいクエリ処理を提供しました。その結果、SUMMARIZECOLUMNSなどの新しいクエリパターンが導入され、データの処理速度や効率性が向上しました。
*3:複数の列を指定して行をグループ化し、それらのグループに対して集計を実行するプロセス