前回はPower BIからDr.Sumに接続した際の読込パフォーマンスについて見てきました。
今回はDr.SumをソースとしたDirectQueryのパフォーマンスについて見てみたいと思います。
DirectQuery
Dr.Sumをインポートした場合、CSVよりもロードは速く、SQLよりも遅いと紹介しました。インポートモードはメモリ上にデータを読み込むインメモリ・データベース・テクノロジーを採用しているため、世界最速のアナリティカルエンジン(Vertipaq)によってビジュアルの表示パフォーマンスが最大化されます。しかしながら、データを最新に維持するためにその都度更新を行う必要があるため、データ鮮度が犠牲になってしまいます。
データ鮮度を最適に保つためにはDirectQueryを使用することになりますが、SQLクエリを発行してソースシステムに問い合わせを行うため、クエリのパフォーマンスがインポートモードよりも劣ります。今回はDr.SumをDirectQueryモードで使用した場合のパフォーマンスを調べてみました。
以下、前回でも解説しましたが、データソースの概要です。
- データソース
SQLサーバー vs Dr.Sum vs CSV - テストデータ
ContosoRetailDWのFactOnlineSales
① SQLサーバー: ContosoRetailDW
② Dr.Sum: CSVから読み込んだデータ(①と同じ量)
③ CSV: ContosoRertailDWからエクスポートしたFactOnlineSales - データ量
FactOnlineSales: 約1,300万行 × 13列
検証方法
- Dr.SumにContosoRetailDWから吐き出された3つのCSV(FactOnlineSales、DimProduct、DimDate)をインポート(※インポート後の列はContosoRetailDWのオリジナルから少し減らした状態で保持)


- (条件を同じにするため)DAX Studio等のツールから上記3つのファイルをSQLサーバーへエクスポートしたデータベースを構築

- Power BI Desktopで1と2のソースに対してDirectQuery(DQ)で接続したpbixファイルを作る

- それぞれにて、リレーションシップを構築

Dr.Sumの場合、DQではモデルビュー内のヘッダーが青ではなく、白のままになっています(インポートモードと同じ)。
- 日付別売上とブランド別売上の2つのビジュアルを作る


- DAX Studioでそれぞれのファイルにあるデータセットと切り口別にパフォーマンスを測る
以下、結果となります。なお、以下では「参照整合性を想定」をOFFにした場合とONにした場合のそれぞれについて見てみます。DirectQueryのソースPK(Primary Key)/FK(Foreign Key)が参照整合性(Referential Integrity)を持つことが強制 or 既にその状態であることが分かっている、かつデフォルトの「参照整合性を想定」の設定がオフの場合、INNER JOINS の代わりに OUTER JOINS が使用され、速度が低下します。
従って、DirectQueryでは、この「参照整合性を想定」に✅を入れることで、クエリパフォーマンスが改善されます。なお、参照整合性についてはこちらの記事をご参照ください。
SQL
- 参照整合性を想定OFFの場合
- DateKeyベース:986 ms

DimDate[DateKey]ベースで3回テストしてみましたが、全てが約1,000ms(1秒)という結果となりました。 - BrandNameベース:509 ms

DimProduct[ProductName]ベースでもテストしてみましたが、全てが約500ms(0.5秒)という結果となりました。
- DateKeyベース:986 ms
- 参照整合性を想定ONの場合

- DateKeyベース:555 ms(▲44%)
 「参照整合性を想定」に✅をしておくと、DimDate[DateKey]では約半分の時間削減を実現でき、DateKeyを軸とした可視化において効果が上がることが分かりました。
「参照整合性を想定」に✅をしておくと、DimDate[DateKey]では約半分の時間削減を実現でき、DateKeyを軸とした可視化において効果が上がることが分かりました。 - BrandNameベース:435 ms(▲15%)

一方、DimProduct[BrandName]でも同じように「参照整合性を想定」に✅を入れて試したものの、さほど大きなパフォーマンスアップにはならなかったようです。
- DateKeyベース:555 ms(▲44%)
このSQLの数字(約500ms)を覚えて頂き、次にDr.SumベースでDirectQueryを使ってみます。
Dr.Sum
- 参照整合性を想定OFFの場合
- DateKeyベース:37,454 ms
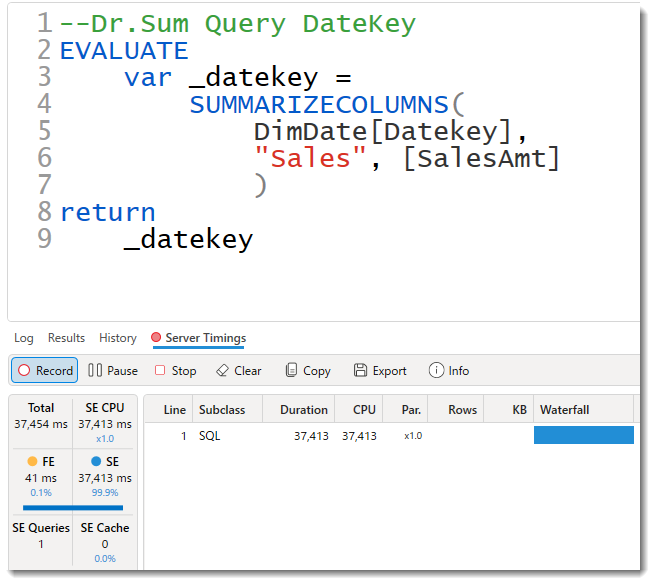
SQLサーバーによるDirectQueryとは大きく異なり、約37秒という時間が必要となってしまいました。
- BrandNameベース:28,610 ms

DimProduct[ProductName]ベースではDimDate[DateKey]ほど時間は必要としませんでしたが、それでも1つのクエリで28秒も必要となったのです。それでは、「参照整合性を想定」に✅を入れた場合はどうでしょうか。
- DateKeyベース:37,454 ms
- 参照整合性を想定ONの場合
- DateKeyベース:37,849 ms(変化なし)

- BrandNameベース:27,413 ms(▲4%)

どちらの切り口でテストしても、結果が殆ど変わりませんでした。追加検証は必要ですが、SQLサーバーだけが大きな恩恵を受けるのかもしれません。
- DateKeyベース:37,849 ms(変化なし)
クエリパフォーマンス
なぜ、Dr.SumによるDirectQueryはこれほどまでに遅いのでしょうか?DirectQueryが遅い理由は例えばこちらにある通り、下記の3つ(抜粋)がキーなるでしょう。
- Power BIはSQLクエリをビルドしているのではなく、DAXクエリをビルドするツールである
- DirectQueryの場合、DAXエンジンは可能な限り、SQLサーバーへ最大限のワークロードをプッシュして処理させている
- DAXクエリはSQLクエリとは根本的に異なっており、最適化が行われていなければ、Power BIでDirectQueryを使用した場合、パフォーマンスが非常に遅くなってしまう可能性がある
それゆえ、Dr.SumをソースとしてDirectQueryで接続した場合、SQLサーバーと比べて最適化されていない可能性が高いと言えます。Dr.Sumのモデルビューは以下の通りですが、DimDateとDimProductテーブル内にある切り口でSalesAmtを可視化していますので、インポートモードのように、何も深く考えずにDimテーブルでリレーション(この場合、物理的なリレーションというより、オンデマンドなバーチャルリレーションシップ)を作ってしまうとパフォーマンスが著しく落ちてしまうことがあります。
DirectQueryはクリックされるためにジョインがオンデマンドで発生してしまうため、リレーションシップを作らなかった時(マテリアルズドビュー)よりもパフォーマンスが悪くなります。

これを確かめるため、Dr.Sumで以下のようなビューを作ります。FactOnlineSalesにDimProductテーブルからBrandName列を持ってきて、FactSalesというビューを作り、Power BIのDirectQueryモードで読み込んでみます。

今までDimDateやDimProductテーブルからフィルターを行っていましたが、今度は新しく作ったFactSalesにあるFactSales[DateKey]とFactSales[BrandName]でビジュアルを作ってみます。

そしてもう一度、Dr.SumのDirectQueryパフォーマンスを測ってみます。
- FactSales[DateKey]でチェック: 442 ms

- FactSales[BrandName]でチェック: 510 ms

ご覧の通り、シングルテーブルにした場合、Dr.SumはSQLと同等かそれ以上のパフォーマンスを実現したことになります。
インポートモードであればスタースキーマモデルを構築することがベストプラクティスとなりますが、DirectQueryではオンデマンドでクエリのジョインが発生するため、パフォーマンスという観点から1つのテーブルにした方が幸せになる場合もあるかもしれません。
最後に個人的には以下の順番で考慮すべきかなと思います。
- 基本はインポートモードでスタースキーマを作る
- DirectQueryが必要な場合はソースシステムと相談
データの鮮度が「命」な人や、大量データによりインポートモードが無理な場合を除き、インポートモード一択になろうかと思います。