Microsoft FabricのSpark notebook*1を使用して、Lakehouseの「Files」セクションにあるデータを「Tables」セクションにテーブルとしてロードするプロセスを見ていきます。
Fabricにはデータ処理を効率化するための強力なツールが多数ありますが、特にSpark*2を活用すると柔軟性とスケーラビリティが大幅に向上します。Power BIのPower Queryエクスペリエンスに慣れている方の中には、この作業に馴染みがない方もいるかもしれません。そこで、本記事ではその方法をステップ・バイ・ステップで解説し、備忘録としても活用していきたいと思います。
前提条件と準備
まず、始める前に準備しておくべきことを確認します。Microsoft Fabricを使用するにはまずライセンスが必要になります。こちらに関する詳細は割愛しますが、無料試用版やAzure SKUから購入することになります。ここではFabric容量をあることを前提に話を進めていきます。
次に、Microsoft FabricのSpark notebookを使うには、FabricのワークスペースとLakehouseがすでに作成済みである必要があります。ワークスペースはデータのハブ、Lakehouseはその中のデータストアととなります。
具体的な手順
- ワークスペース: Fabricにログイン後、データエンジニアリング用のワークスペースを用意
- Lakehouse: その中にLakehouseを作成し、「Files」セクションにロードしたいデータ(例えばCSVやParquetファイル)をアップロード
- notebook: 新しいSpark notebookを作成するか、既存のものを使用
「Files」にデータがない場合は、Azure Blob Storageなどからサンプルデータをコピーするか、手動でアップロードしてみてください。今回は、サンプルデータをファイルとしてアップロードするやり方を紹介します。
🔸下記Microsoft Fabricポータルへサインイン
app.fabric.microsoft.com
🔸スイッチャーからFabricのアイコンを選択
🔸ワークスペースアイコンをクリックし、作成
※ 2025年3月初め時点、FabricとがPower BIはワークスペースアイコンの表示位置は異なる


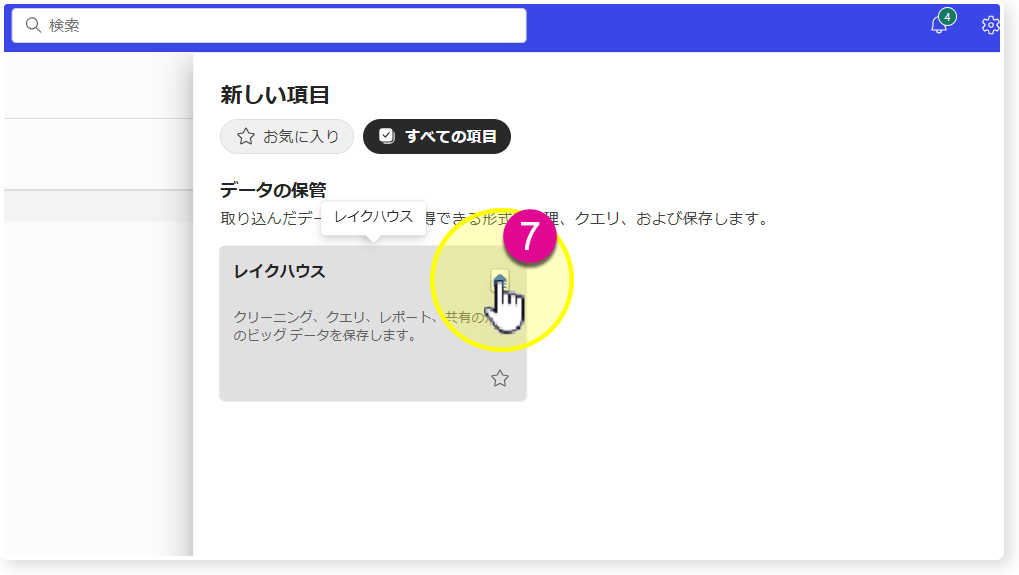
🔸「新しい項目」をクリックし、検索で「レイクハウス」を選択

🔸Lakehouseの名前をGetParquetとして保存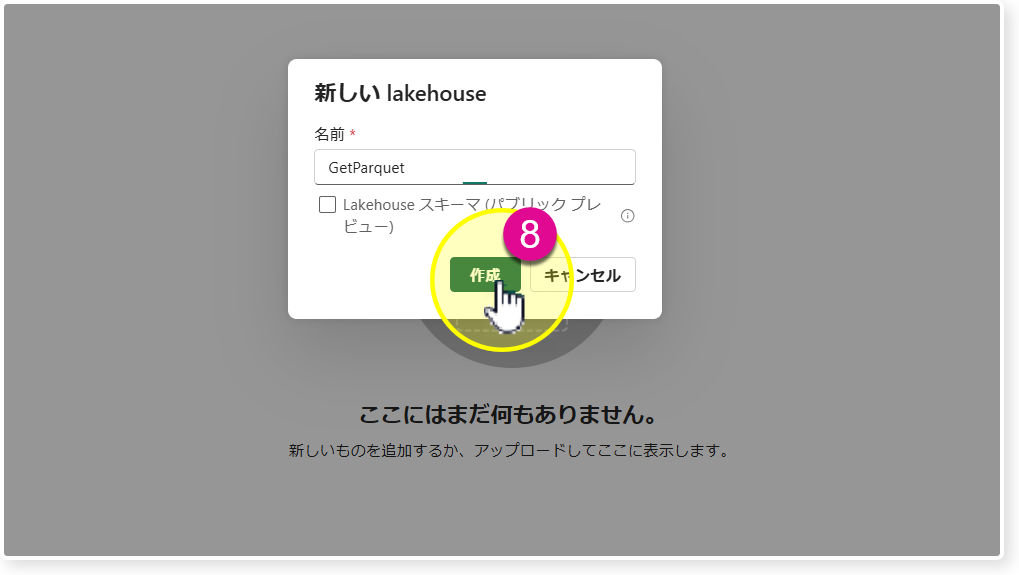
🔸Lakehouseが作成された後、「ノートブックを開く」>「新しいノートブック」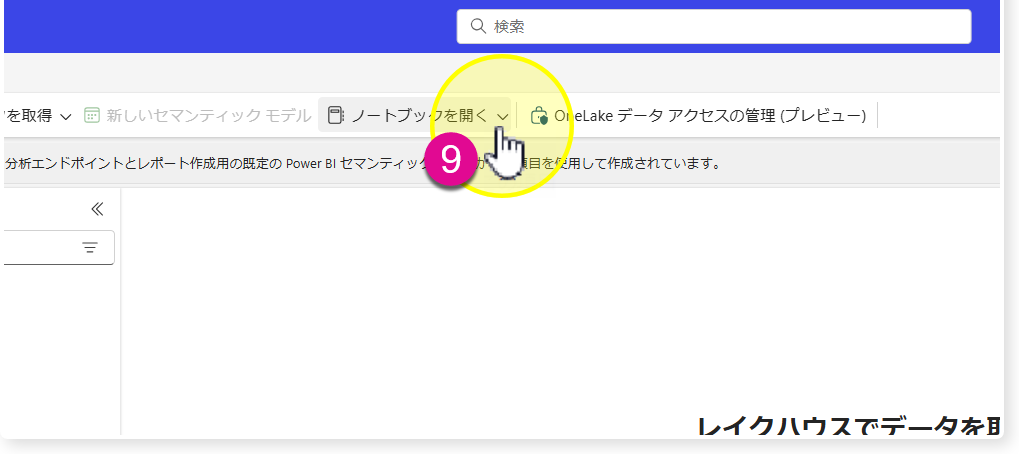
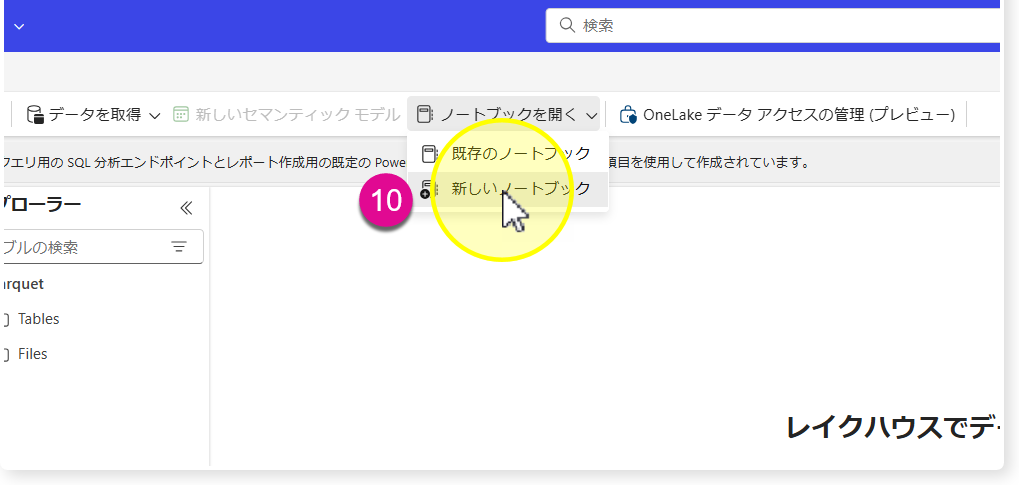
🔸左上の「Notebook 1」を「LoadCSV」に変更し、レイクハウスを選択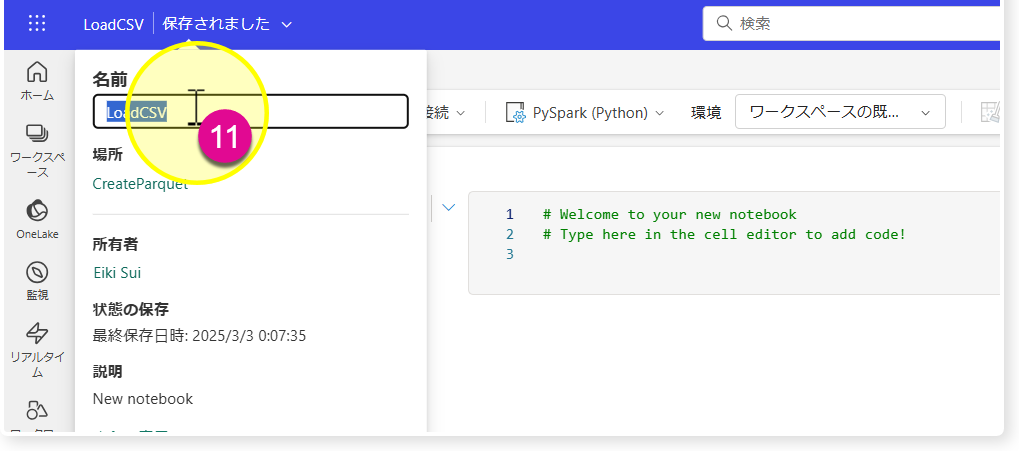
 これで最初に作ったLakehouse「GetParquet」にnotebook「LoadCSV」がアタッチされるようになり、”器 (Lakehouse)"とその器に必要なデータをロードするための"ツール (notebook)"が準備できました。
これで最初に作ったLakehouse「GetParquet」にnotebook「LoadCSV」がアタッチされるようになり、”器 (Lakehouse)"とその器に必要なデータをロードするための"ツール (notebook)"が準備できました。
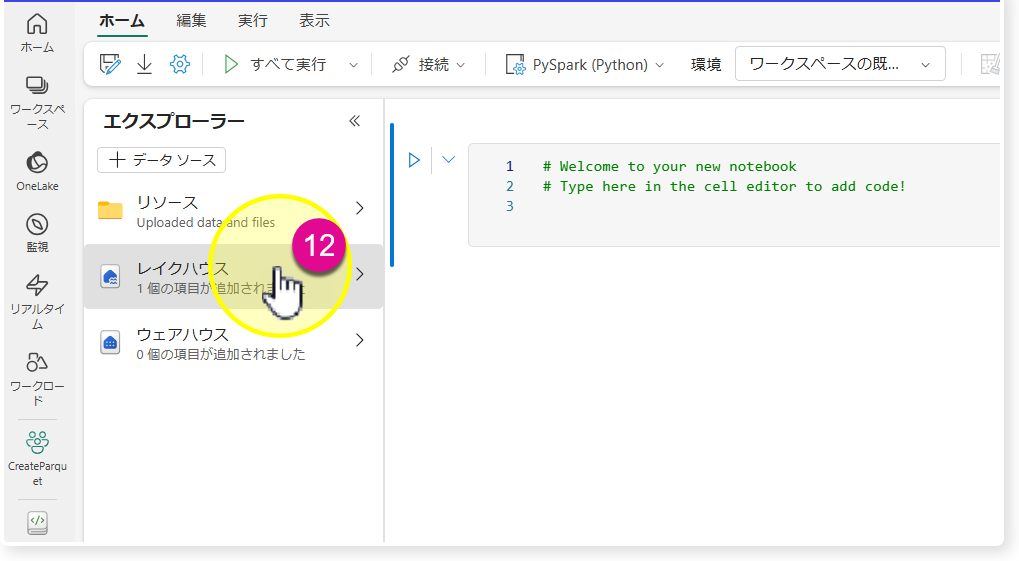
サンプルデータをアップロード
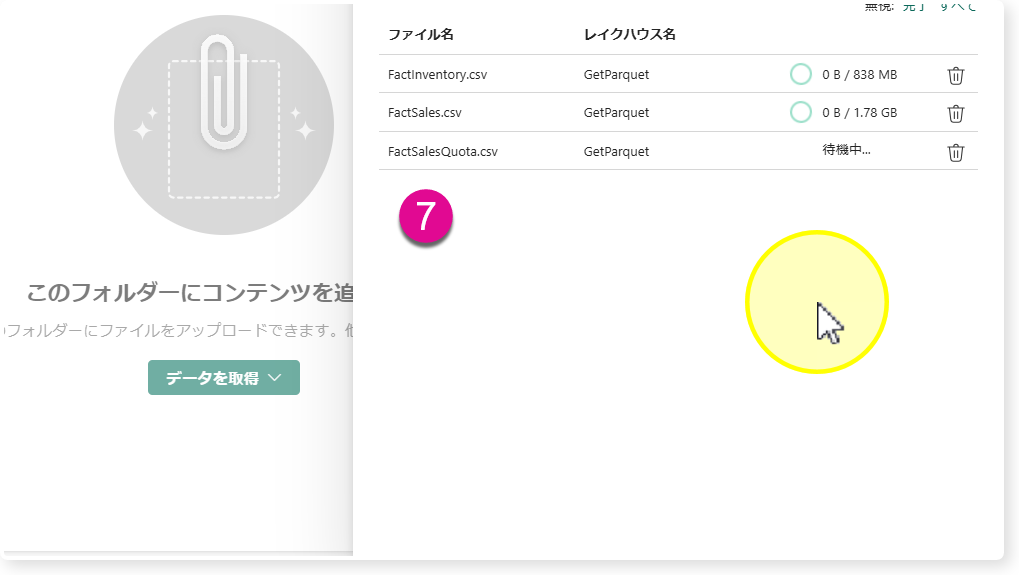
🔸「GetParquet」のLakehouseアイコンをクリックし、「Files」の・・・をクリック。

🔸「アップロード」 > 「ファイルのアップロード」 > ファイルを複数選択し、「アップロード」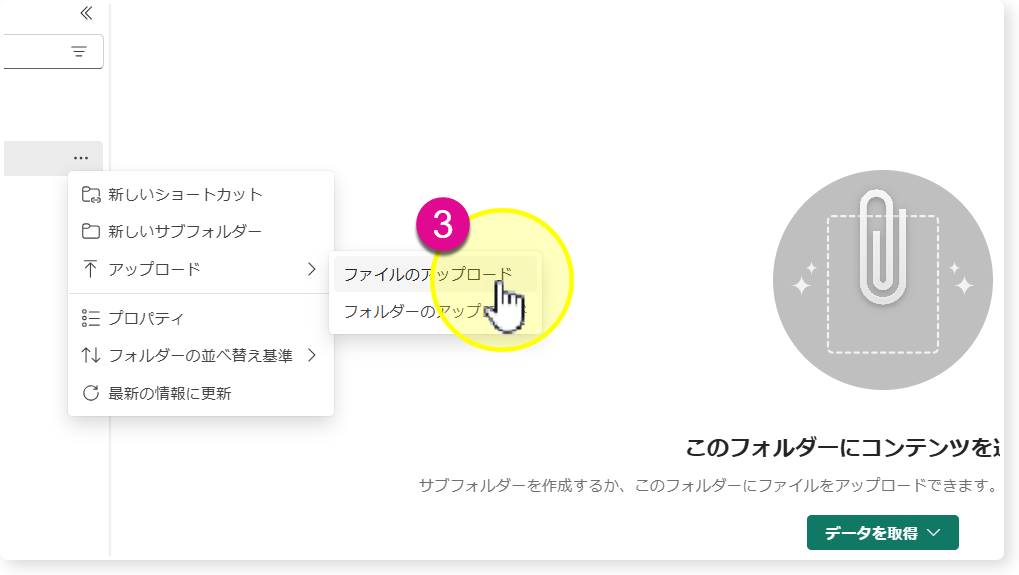
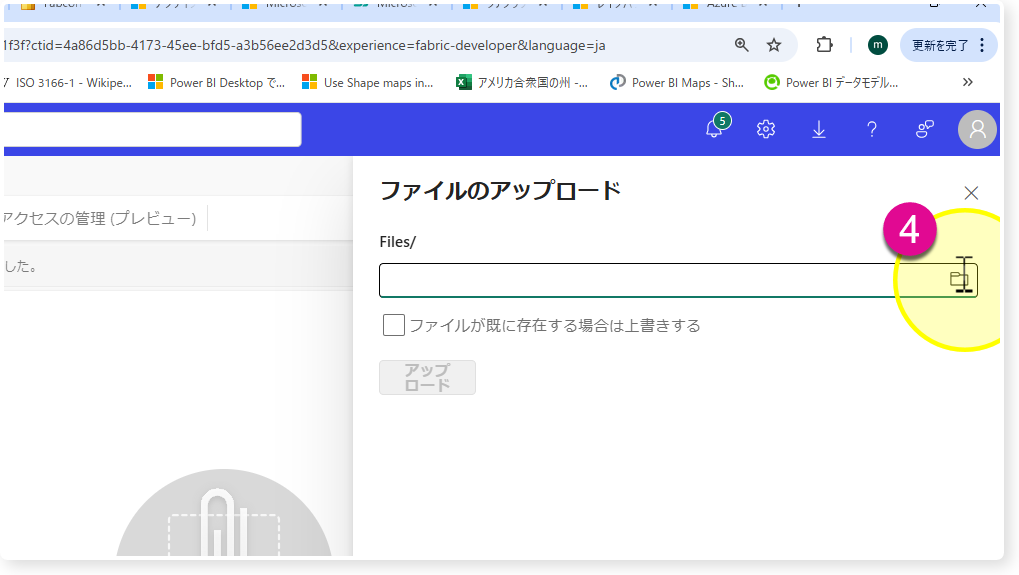


サンプルCSVをテーブルにロード
ここからは、アップロードされたCSVを「Tables」セクションにデルタテーブルとして保存します。デルタ形式はFabricのLakehouseで推奨されるフォーマットであり、パフォーマンスとデータの信頼性が向上するだけでなく、すべてのコンピュートエンジンから参照可能なオープンフォーマットでもあります。
CSVをデルタテーブルへロードするにはいくつか方法はあります。
- UIで操作
- notebookを使ってSparkエンジンをフル活用
- Dataflow Gen2でロード
最後のDataflow Gen2は対象サンプルCSVがあるLakehouseを選び、データの変換を行った後、「データ変換先」(データ同期先 or データの宛先)を設定します。下図はそのイメージとなります。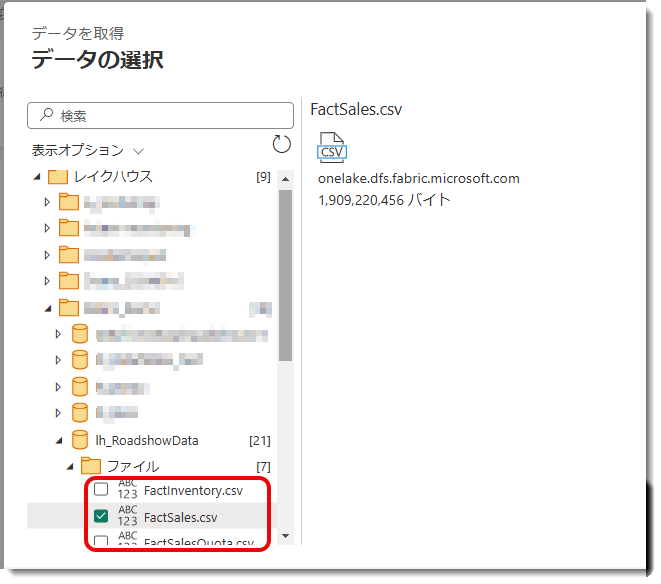
Datalfow Gen2を使ったETL処理→データのロードについては下記シリーズに詳細が記載されています。
marshal115.hatenablog.com
今回はFabric Sparkを使ったデータエンジニアリングの紹介となりますので、最後のDatalfow Gen2は割愛するとし、最初の2つを紹介したいと思います。
UIでロード
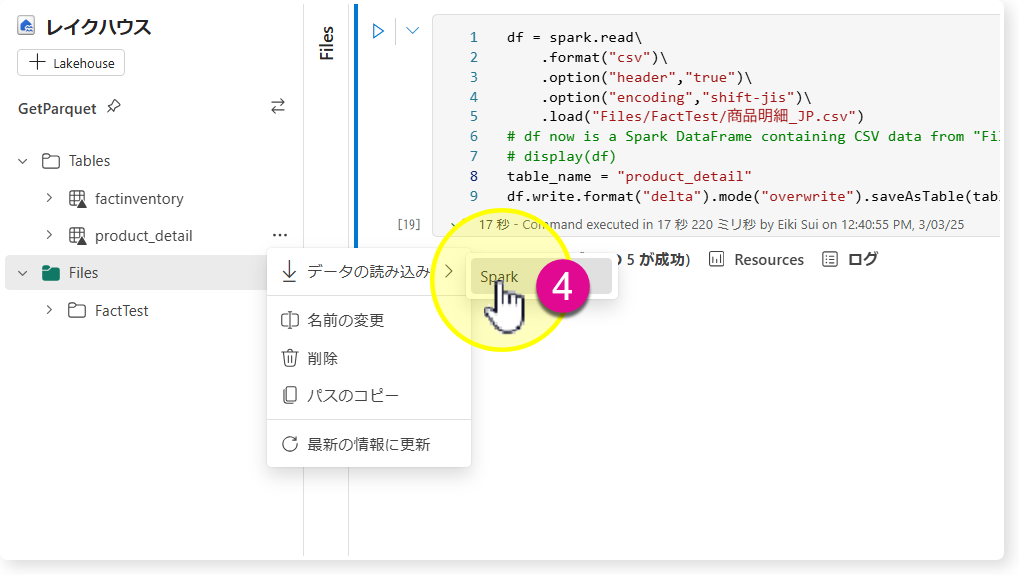
まずはUIを使ってロードするやり方です。Lakehouse「GetParquet」のFilesから、対象CSVの・・・をクリックし、以下のようにロードする。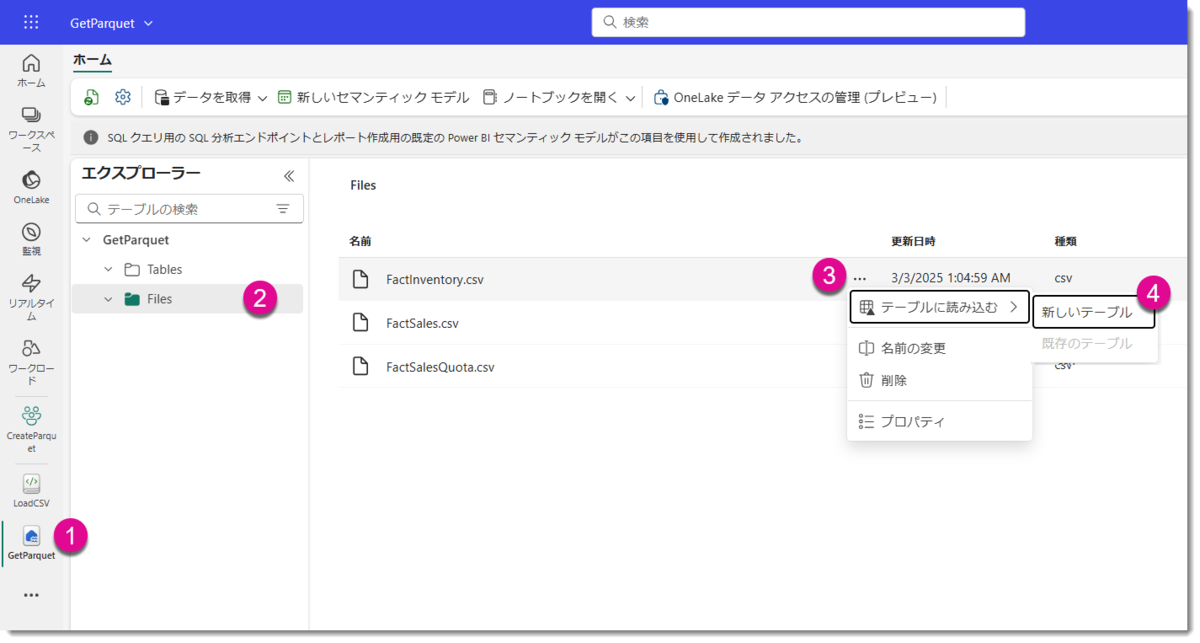


SQL 分析エンドポイントで結果確認
成功すると、factinventoryというテーブルが「Tables」セクションから出現しますので、SQL 分析エンドポイントをクリックします。
※UIやこの後に紹介するnotebookでテーブルへロードする際、テーブル名のアルファベットは全て小文字 (FactInventoryがfactinventory)に変換されてしまいます。処理エンジン (Apache Spark) がデフォルトでテーブル名やカラム名を小文字として処理する仕様であるため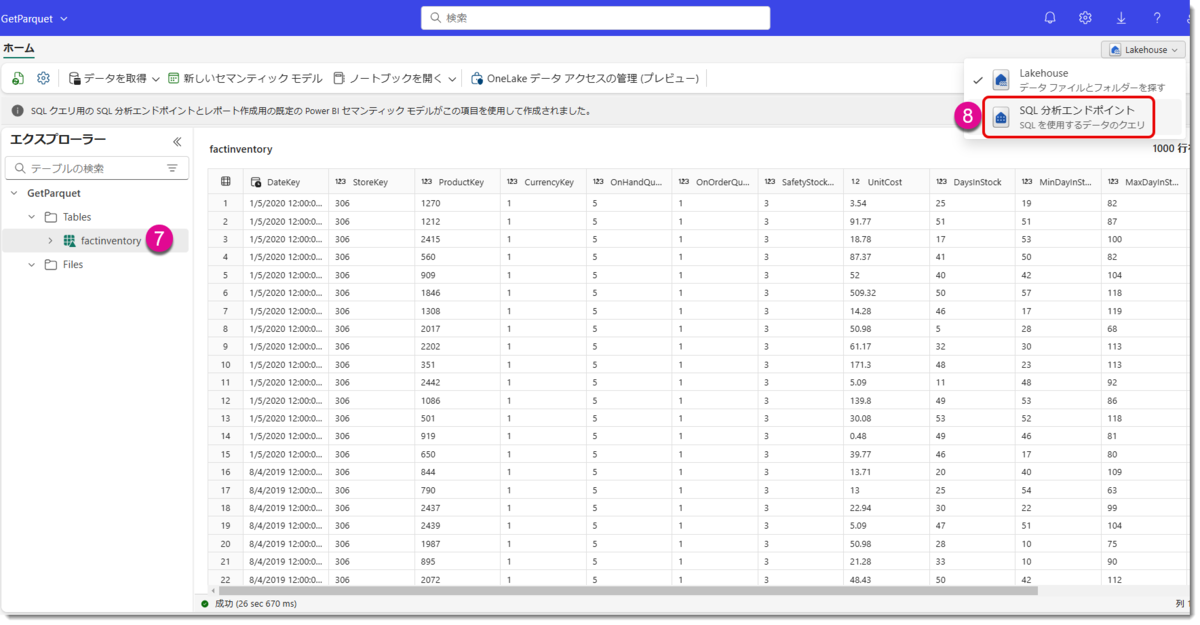
SQL 分析エンドポイントは読取専用のWarehouse機能を具備しており、ここからロードされたデータの確認ができます。
🔸新規 SQL クエリを作成
🔸SELECT構文でトップ10行の表示、factinventoryテーブルの合計行数を取得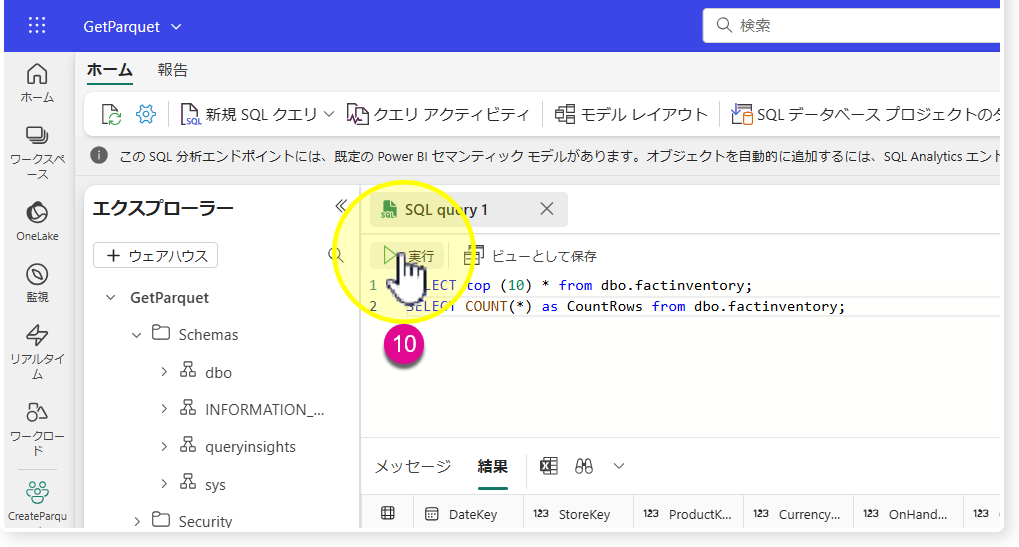
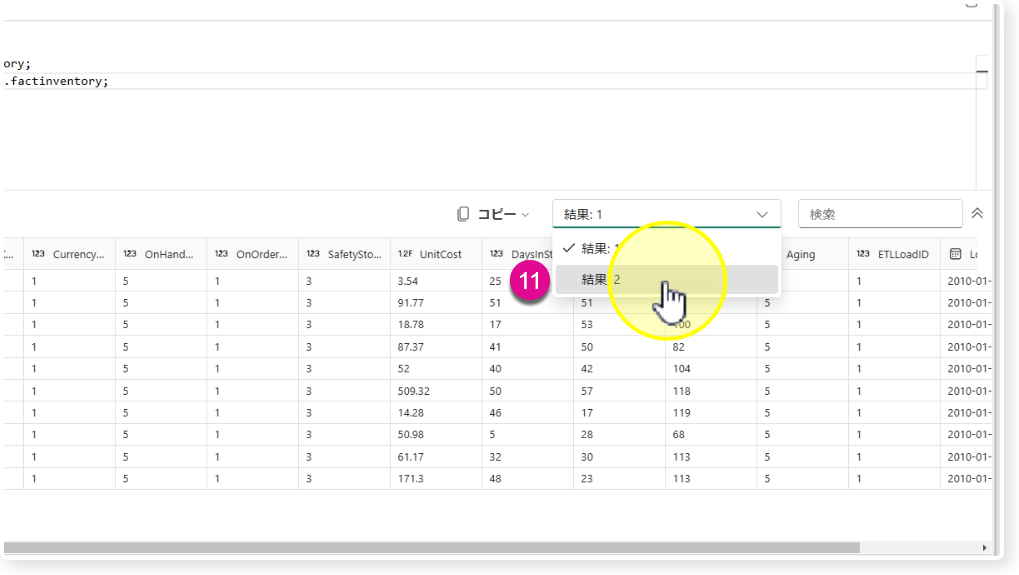
🔸合計約800万行のデータ量を確認
UIで読み込む際の注意点
このように、UIからの操作は非常に手軽であるため、次に紹介するnotebookでコードを書かなくても、データをDeltaテーブルとしてロードできます。
ただし、このUIベースの方法では、ヘッダー名やデータ内に日本語が含まれると文字化けが発生するため、利用には制限がある点に注意が必要です。例えば、以下のように、「Files」の直下に「FactTest」というフォルダがあり、その中に「商品明細_JP」というCSVがあるとします。これをUIベースでSparkを使って読み込んでみます。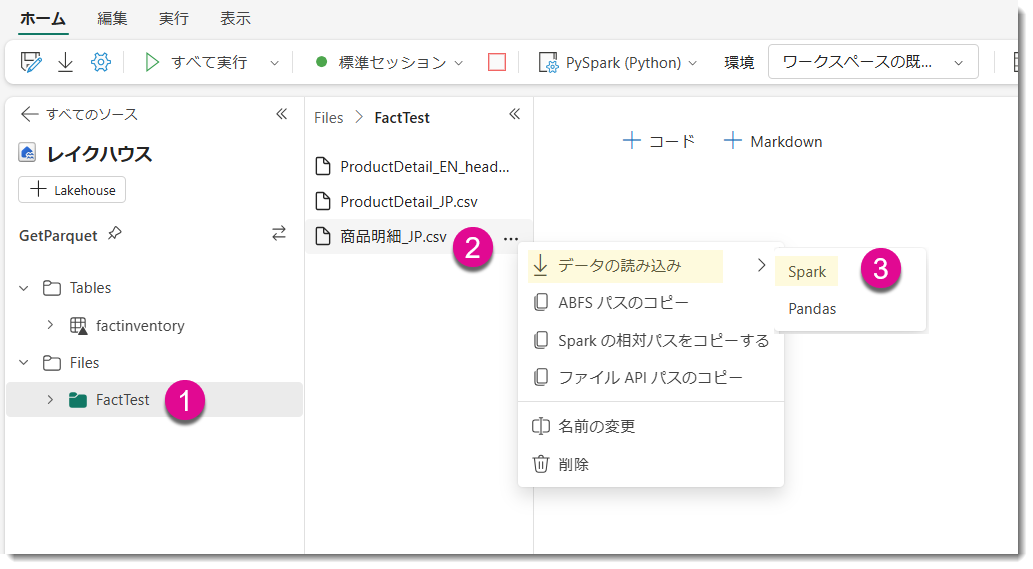
③をクリックする下記のように、PySparkコードがコードセルに挿入されます。日本語ベースのファイル名は問題ありませんが、UIベースで生成された PySpark コードを実行した結果、以下の通り文字化けが発生します。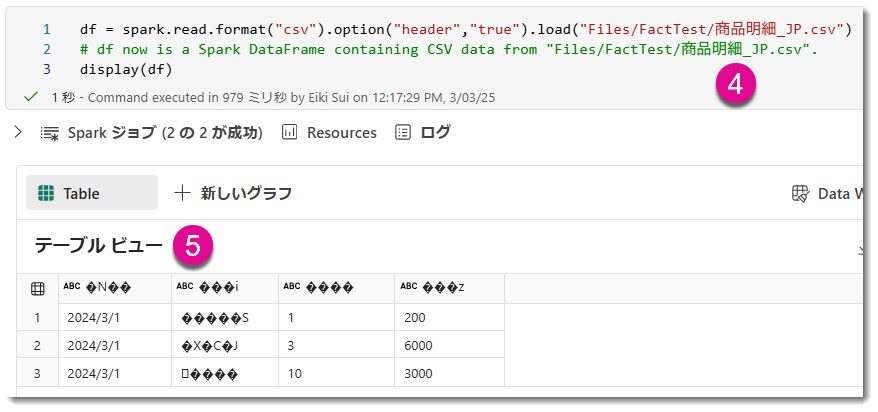
エンコーディングを追加する
これはFabric Spark notebookでは既定では日本語エンコーディングの設定が為されていないためで、日本語を読めるようにするためには、以下のようにoptionにencodingを指定してあげる必要があります。
※ 可読性を高めるために改行していますが、実際のコードでは \ を使用します。display (df) は df の中身を可視化するためのコードになります。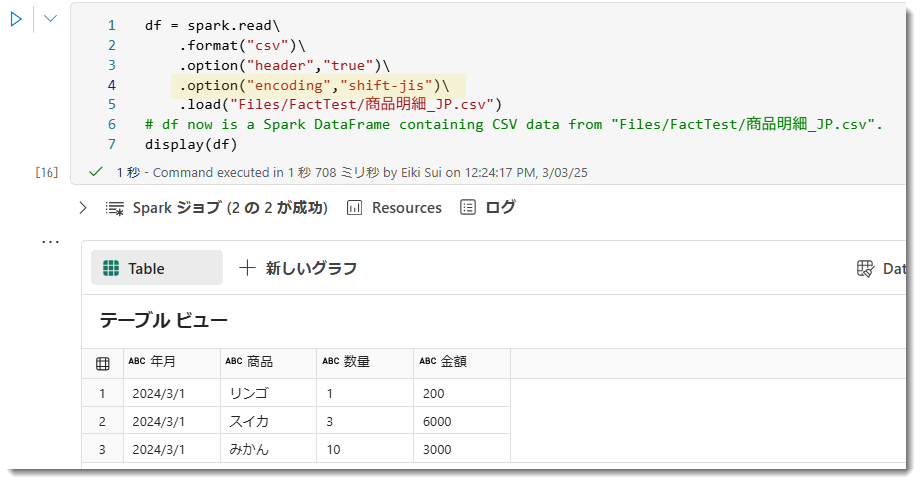
デルタテーブルへロードする際の注意点
なお、ここで「商品明細」という名前でこのデータをテーブルへロードしてみます。「table_name」という変数に"商品明細"を代入し、日本語名のデルタテーブルとして書き込む (write) するようにしたものですが、ご覧の通り、Apache Sparkは非ASCII文字*3が原因で予期しないエラーや不具合が発生する場合があります。Fabric Sparkの環境では日本語文字 (非ASCII文字) でロードすることができないようです。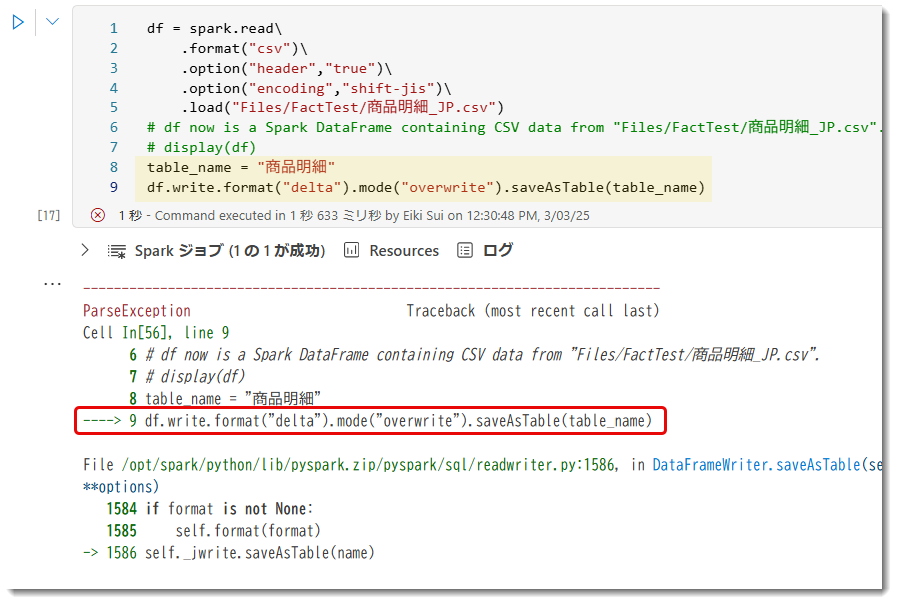
そこで「table_name」を英語に変更し、再度実行してみます。なお、"product detail"のように空白があると同じくロードに失敗しますので、アンダーバー (_) を付けると良いでしょう。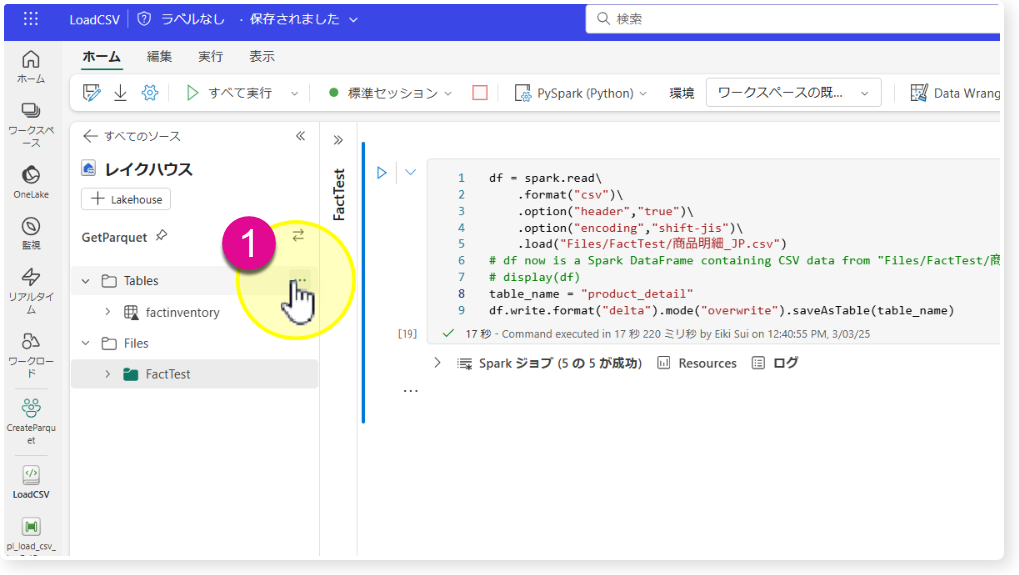
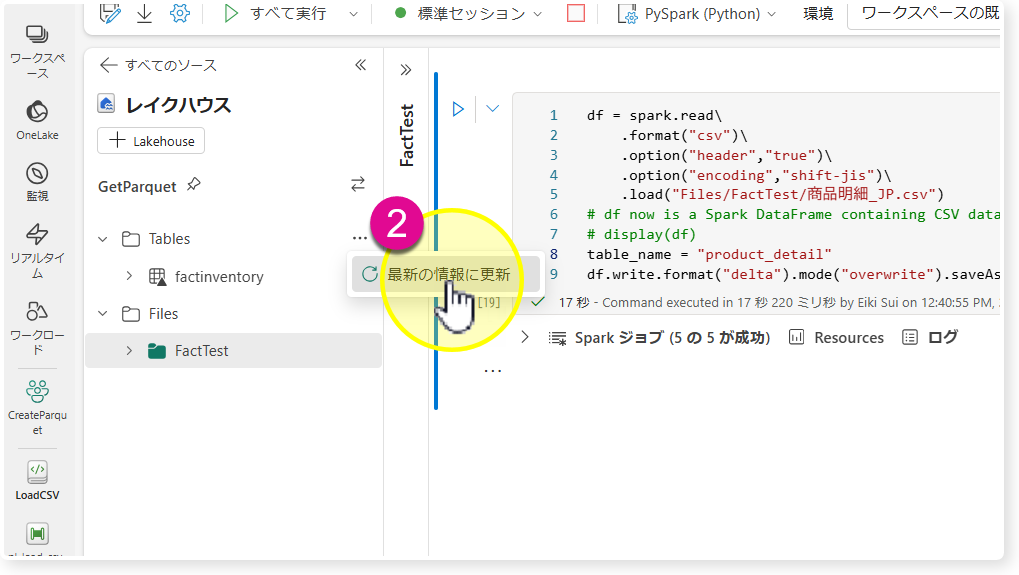


ネーミング規則
上述の通り、ネーミング規則は結構厄介です。Apache Sparkでは、テーブル名に非ASCII文字を使うとトラブルの原因になりますが、Dataflow Gen2を使用すれば日本語名のテーブルも問題なくロードでき、さらにアルファベットでは大文字を使用することもできます。加えて、Power BIユーザーにとってはテーブル名や列名に日本語を使用するのが一般的ですが、これに関するネーミング規則については以前、別の記事で解説していますので、そちらをご参照ください。
読むのが面倒な方のために、Spark でも Dataflow Gen2 でも、以下のルールを押さえておくと、ロード時のエラーを抑えられる可能性があります。
- テーブル名は可能な限り英語ベース
- 最終的にPower BIのセマンティックモデルで使うテーブルの場合、分かりやすい名称にすること (例: Sales, Inventory等)
- テーブル名にスペースや特殊文字 (例: /等) を含めない
- 列名も本来は英語ベースが望ましい。上記の記事にて解説の通り、Power BIで最終的にDAXメジャーを記述する際にアルファベットにしたほうが効率が上がります
- データの中身については日本語でないとどうしようもないため、それはそのままで構いません
- 結論
テーブル名:英語
列名: 英語
中身: 日本語 (ローカル言語)
データ型の指定(※ガチ躓きポイント)
ところで、このロードされたデルタテーブルではデータの型が正しく設定されておらず、全てがテキストになっています。
これはデータをCSVからデータを読み取る際、データ型を設定しなかったことが原因で、以下のようにoptionを追加すると正しい型を設定し、デルタテーブルへロードすることができます。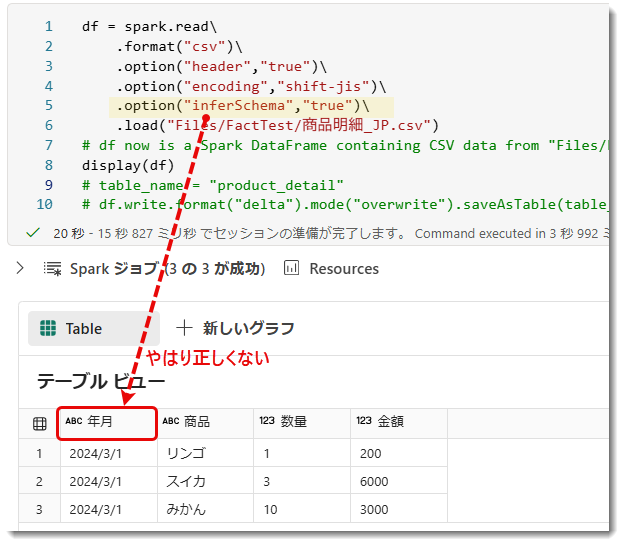
しかし「inferSchema」(Infer = 推測する) を設定しても年月のデータ型は正しくないため、手動で設定してあげる必要があります。以下はApache Spark の データフレーム (DataFrame) *4における スキーマ (Schema) を定義するために使用されるモジュールからpyspark.sql.typesをインポートしたものです。このモジュールを使うと、列のデータ型を指定して、Spark の DataFrame に格納するデータの形式を定義できます。「StructType」と「StructField」を使用し、予めデータ型を設定しておきます。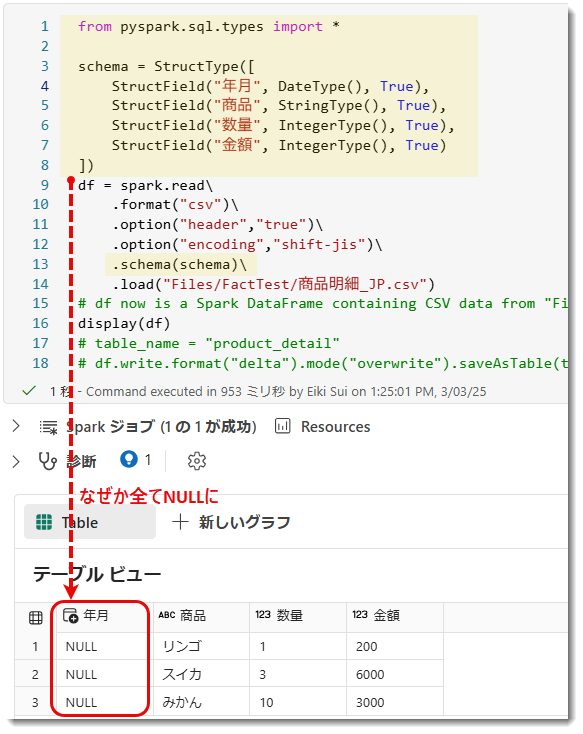
こちらのコードを追加して実行すると、ほとんどの列で正しくデータ型の指定が完了しますが、なぜか「年月」だけが NULL になってしまいました。BI をやっている立場からすると、これは???という状況で、かなり焦ってしまいましたが、どうやら CSV データ内の日付形式が DateType として認識されていないことが原因のようです。
具体的には、Spark の DateType はデフォルトで yyyy-MM-dd の形式を期待しますが、「年月」列が yyyy/MM/dd や yyyy/MM の形式である場合、Spark はこの形式を正しく解析できず、その結果 NULL として読み取ってしまうことがあるようです。
そこで「年月」をまずStringType (テキスト型) に設定し、その後データフレーム (df) 内で調整することにします(下図)。なお、CSVの中身は"yyyy-MM-dd"ではなく、"yyyy-M-d"の書式であったため、to_date関数内で指定する書式は"yyyy/M/d"にする必要があります。df.withColumnは既存の列に対して処理を行ったり、新しい列を追加したり、処理後に新しいDataFrame を返してくれるため、覚えておくべき重要なメソッド(Power QueryでいうとTable.AddColumnやTable.TransformColumnsに類似)と言えます。ちなみに、DAX Guideのように、Power Query Howというサイトがいい感じに事例まで紹介してくれていますので、Power Queryを学び人にとって参考になりそうです。
to_date 関数で 年月 列が正しい形式になりましたので、もう一度ロードします。しかし、完璧に思えたコードでもエラーが発生してしまいました。
エラーメッセージ「AnalysisException: [DELTA_FAILED_TO_MERGE_FIELDS] Failed to merge fields '年月' and '年月'」となりますが、どうやら
既存の Delta テーブルと新しいデータフレームのスキーマが一致していない場合にエラーが発生する
ようです。つまり、まとめると以下の現象になります。
- デルタテーブルは最初、全てテキスト型 (StringType) でロードされていた
- inferSchemaで「年月」以外を正しいスキーマに変更(年月以外)
- この状態(年月のデータ型がまだString型のまま)で再度デルタテーブルとして同じ名前でoverwriteしようとするとエラーが出る。もちろん、年月のデータ型がDateTypeに直ってもエラーが発生
対処法:
- 別名でテーブルを指定する
- 一回既存のテーブルを削除 (Drop) してから正しいデータ型の状態でデルタテーブルを再構築
前者はテーブルが無数に増える可能性があり、いろいろと非現実的のため却下。後者が選択肢になりますが、以下のようにSpark SQLを指定します。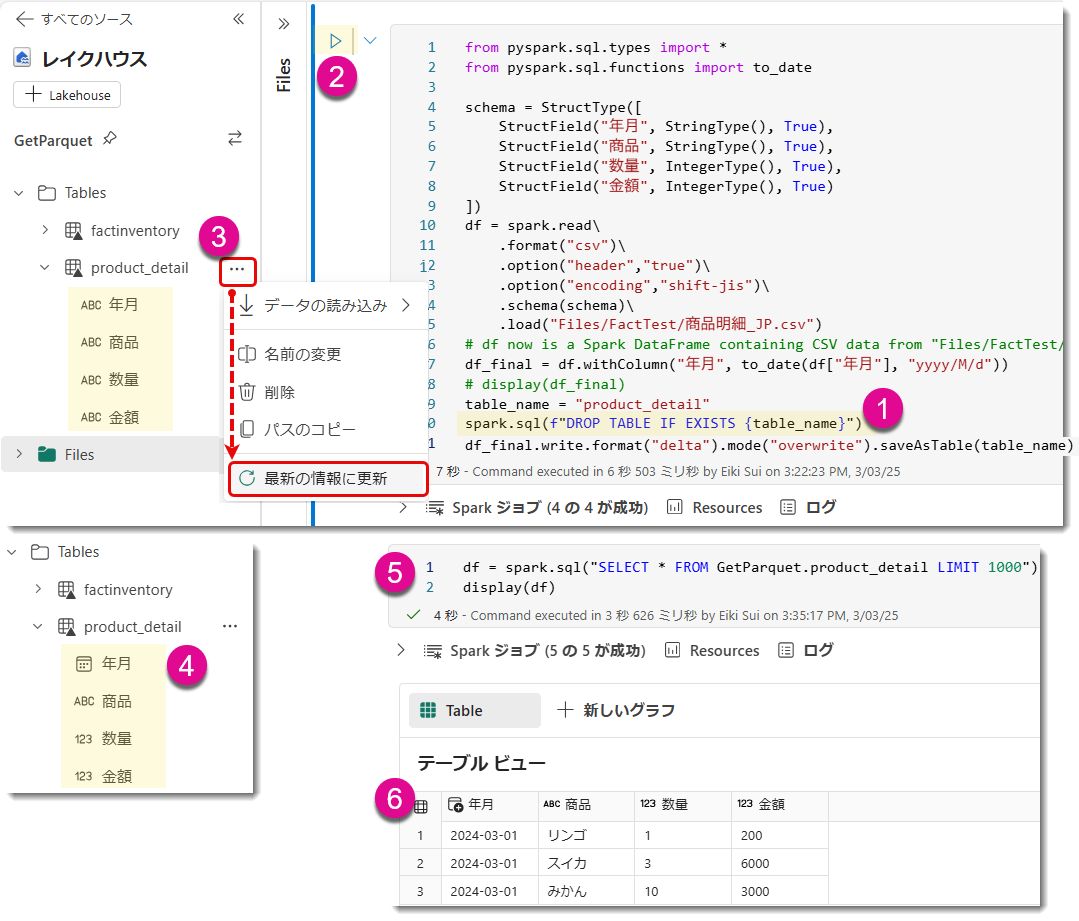
ご覧の通り、最終的には正しい書式のテーブルを作ることができました。今回のこの挙動はDataflow Gen2でも起こり得ることで、スキーマが変わったことでデータが更新されなかったりと気を付ける必要があります。
Power BIユーザーでPower Queryに慣れている人は、いきなり面を食らってしまう躓きポイント
となりそうです。
最後に、テーブルを削除するために spark.sql(f"DROP TABLE IF EXISTS {table_name}") というコマンドを使用しますが、これは Apache Spark の SQL 機能で、指定されたテーブルを削除するのに使います。
- spark.sql:
Spark の SQLContext や SparkSession オブジェクトで、SQL クエリを実行するためのメソッド - f"DROP TABLE IF EXISTS {table_name}":
f-string と呼ばれる Python の文字列フォーマットの機能を使用。f-string は、波括弧{}の中に変数や式を埋め込むことで、文字列内で動的に値を挿入できます。例えば、fullpath = f"{base_path}/{file}"のように、変数base_pathと変数fileを指定して結合することも可能です
f-stringについては結構使用することが予想されます。
DROP TABLE 以外のやり方
Fabric名人のNagata氏より耳よりな情報。DROP TABLEをしなくてもスキーマを上書きすれば保存できるということで試してみたら、その通りになりました。
ということで、spark.sql(f"DROP TABLE IF EXISTS {table_name}")をコメントアウトさせ、最後にデルタテーブルへロードするときに.option("overwriteSchema", "true") を入れてみました。下図の通り、エラーもなく処理が完了しています。
思うところ: 初心者キルな・・・しかし慣れれば、自然に覚えるので今回で覚えました。情報ありがとうございます。
まとめ
Microsoft Fabricのデータエンジニアリング・ワークロードを使ってみました。初歩的なことしか行っていませんが、Power BIペルソナにとって最初からやや学習障壁が高いと思います。Power BIとの大きな違いの1つは、Power BIはPower BI Desktopを使ってローカル環境で開発できる点ですが、Sparkを使ったデータエンジニアリングでは全てがクラウドで完結し、コードの記述が必要なため、ビジネスユーザーにとっては敷居が高くなりがちです。
ただし、学習曲線は存在するものの、慣れてしまえば大量データの処理が驚くほど迅速に終わる可能性があり、次回以降にその実力を紹介したいと思います。
*1:Apache Sparkを使用してデータ分析や処理を行うためのインタラクティブな開発環境です。コードセルを実行し、結果を視覚化・分析できるツールで、データフレーム操作や機械学習の実行が可能です
*2:大規模データ処理のためのオープンソースフレームワーク。インメモリ計算を活用し、高速な分散処理を実現。バッチ処理、ストリーミング、機械学習、SQLクエリをサポートし、Hadoopやクラウド環境で動作。柔軟性とスケーラビリティが特徴
*3:ASCII文字は半角の英数字や記号など。非ASCII文字は日本語文字や全角の英数字、記号等に含まれる。半角のカナは1バイト情報量の単位
*4:Spark DataFrameは、分散データ処理を行うためのデータ構造で、テーブルに似た形式でデータを格納します。列と行から成るデータセットを表し、SQLクエリや変換操作をサポートして、効率的に大規模データを処理することができます