過去3回にわたり、書式が異なるデータの集計に関するTipsを紹介してきました。最終回は予告通り、クエリのパフォーマンス問題とTable.SelectColumnsについて話をしていきます。なお、下記サンプルをダウンロードした場合、①~③まで読んでおくことをお勧めします。
サンプルファイル(フォルダパスの修正方法は下記第1回をご参照)
最終アウトプット
実はここまでの話、Power Queryのソースコードが読める人であれば説明は必要ないものとなります。今回の話はList.Bufferを使ってクエリパフォーマンスを最適化するもので、Bufferについて理解している人で最終アウトプットだけがほしい人は下記よりダウンロードしてお使い下さい。それ以外でBufferや"列のダイナミク選択"について知りたい方は最後までお読みください。
最終アウトプット(Ctrl + クリック)
上記をクリックするとExcel Onlineが立ち上がりますが、以下のように自分のローカルドライブへ保存してください。
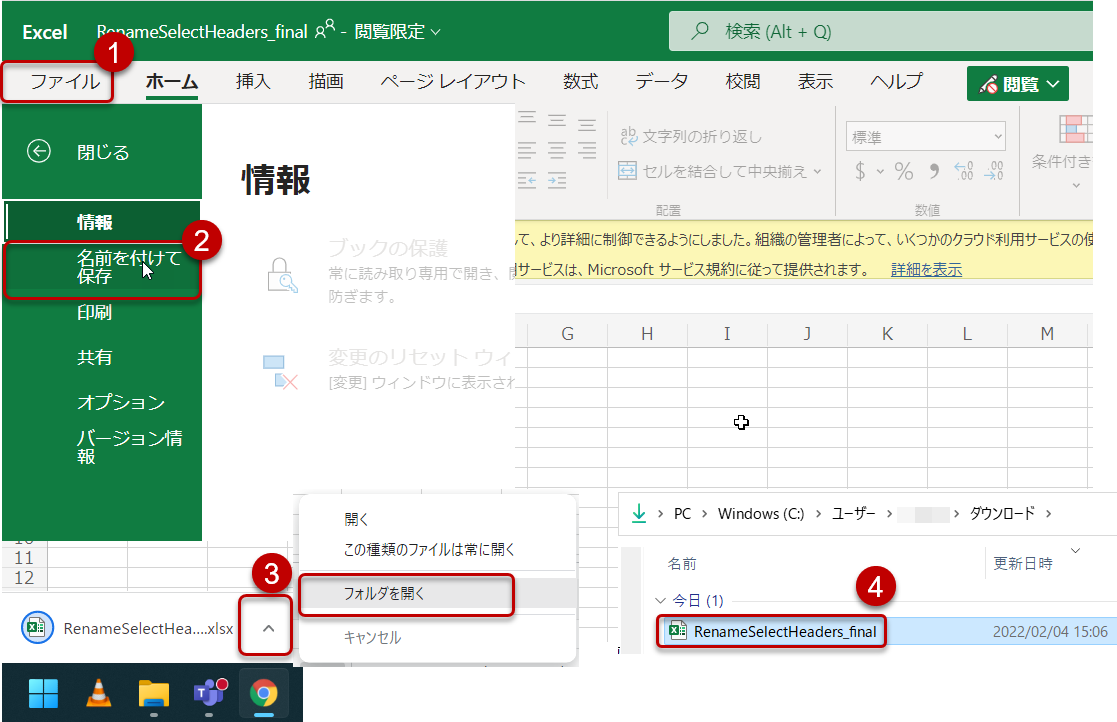
保存後、1回目の記事と同様、以下のように「フォルダパス」の変更を行います。
- セキュリティの警告がある場合、「コンテンツを有効にする」をクリック
- 「データ」>「データの取得」>「Power Queryエディタの起動」
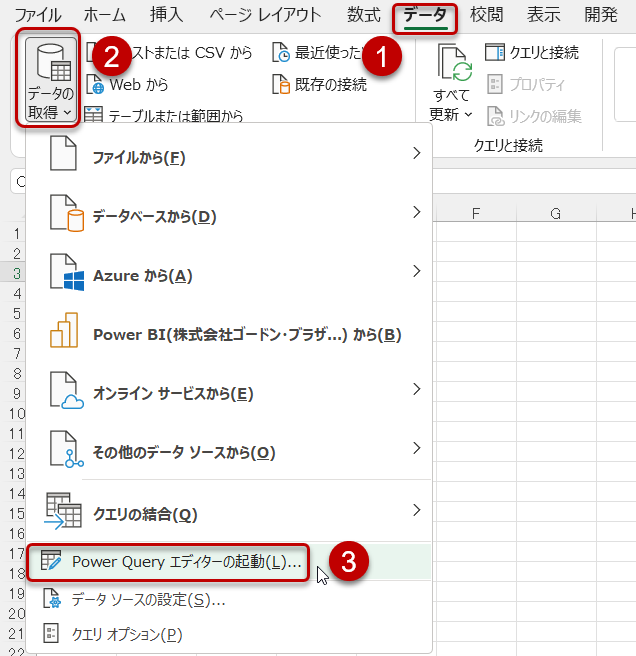
-
クエリエディタが立ち上がるので、Sourceというパラメータをクリックし、Dataフォルダのパスを入力する
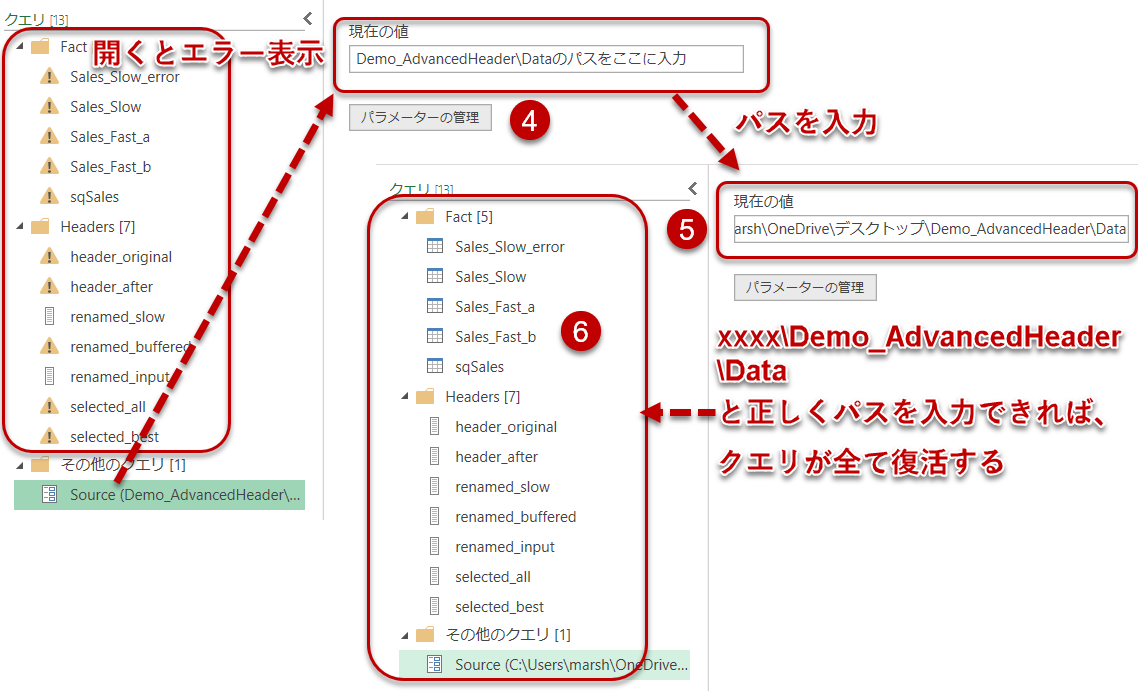
これで今回の記事の内容を含む、①~④まで解説してきた全てのクエリを確認することができるようになります。読むのが面倒、結果だけ知りたいという方はファイルの中身を見てご自身で解釈してみてください。
クエリ・パフォーマンス
Power Queryは通常、データの先頭1000行までのプレビュー画面を表示させ、ボリュームが大きいデータでも処理を最適化して結果(プレビュー画面)を返してくれます。全てのデータを読み込まないため、最終アウトプットまでサクサクと作業できるわけです。しかしながら、中には全てのデータを読み込まないと次のステップへ進めなかったり、ステップを追加するたびに別のファイルに対する読み込みが発生する場合があります。
前回の話で言えば、Listとなっているクエリ(renamed_slow)がこれであり、
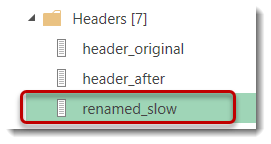
renamed_slowを使って列名を変更してTable.Combineができるメインクエリで何かの処理を行うたびに、繰り返しrenamed_slowの基となるファイルへのアクセスが発生します(下図5)。
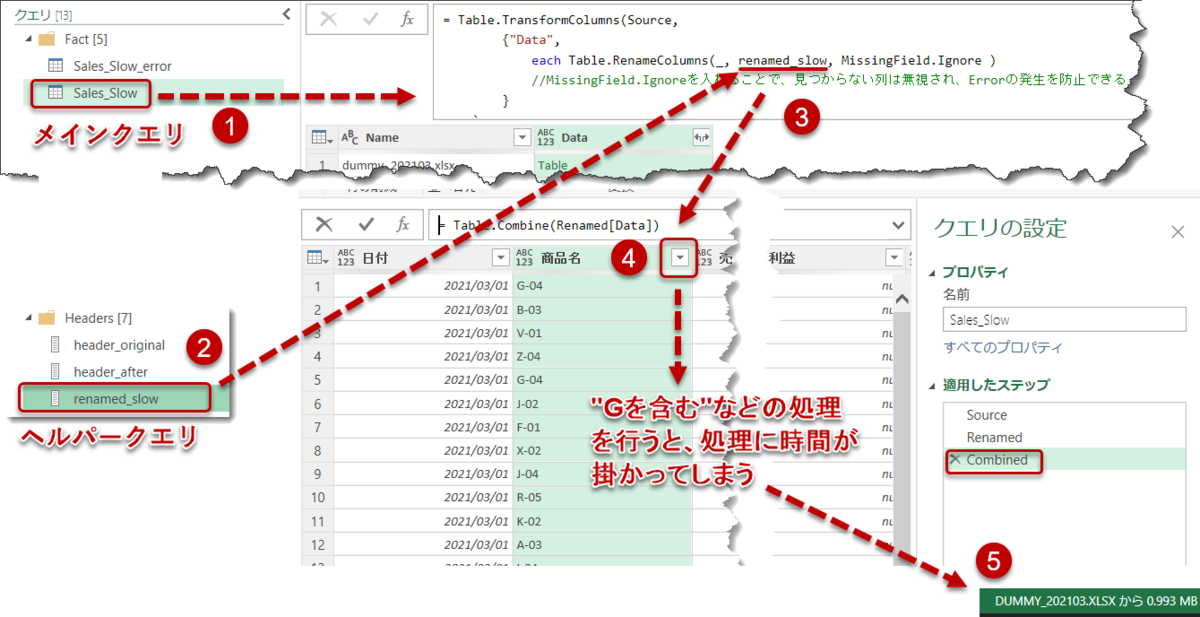
データ量が多い場合、この更新が終わるまでに数分間かかる場合もあり、実務で運用するのに適さない可能性が高くなります。原因は上述の通り、renamed_slowの作り方は複数ファイルのヘッダーをソースとしており、これらが外部のソースであることが原因となります。発生パターンは状況別にいろいろあり、これについては試していくしかないのですが、今回の例では何度も外部ソースへのアクセスが発生していることがクエリのパフォーマンスを遅くしています。
解決法は2つありますが、それぞれPro(メリット)とCon(デメリット)が存在します。
- renamed_slowをList.Bufferで囲う
クエリ: renamed_buffered - クエリエディタにある「データの入力」でBefore / Afterを入力する
クエリ: renamed_input
renamed_buffered
まず1ですが、下図のように、renamed_slowを参照した後、= List.Buffer(Source)と入力し、メモリ上に強制的にそれまでの結果をバッファしておくことで、メインクエリにて1回だけの読み込みで済むようにします。
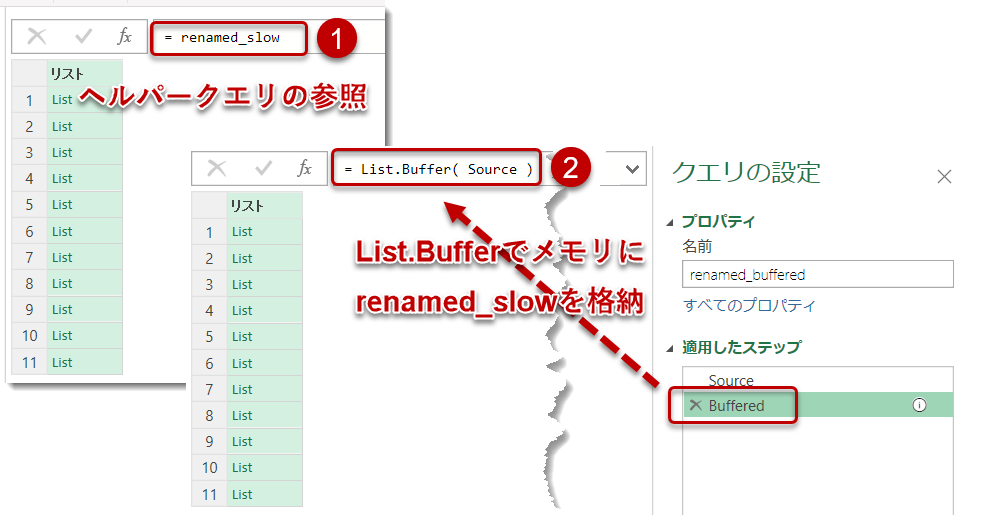
このクエリはrenamed_bufferedという名称にして、renamed_slowと入れ替えれば読み込みが最適化されます。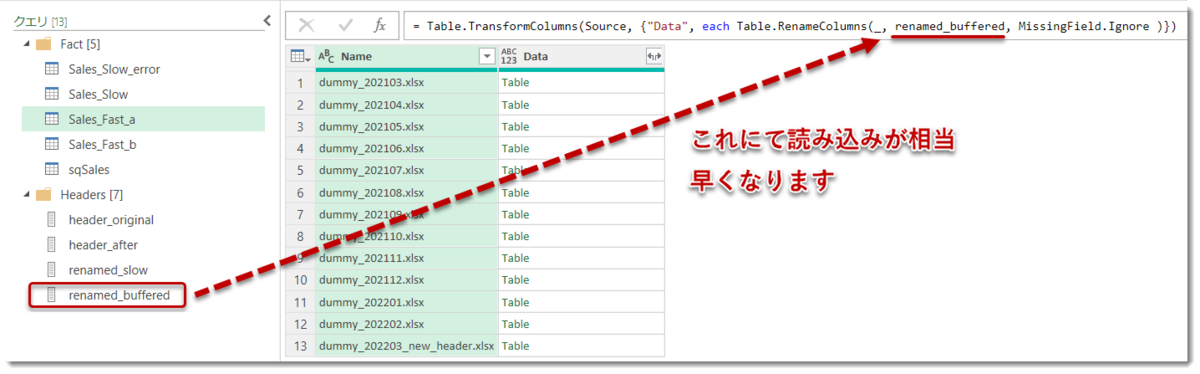
Pro:
Listは全てのファイルにおける全ての列を参照しているため、列が追加されてもすぐに気づくことができ、変更が必要な場合に対処しやすい
Con:
データ量が多い場合、ヘッダーをBufferすると時間が掛かってしまう可能性がある
renamed_input
続いて2のやり方ですが、手入力でBefore(Original)とAfter(Renamed)を入力していきます。
クエリエディタの中で、「ホーム」 >「データの入力」 > 「テーブルの作成」よりOriginalとRenamedの列名をそれぞれ入力していきます(下図)。
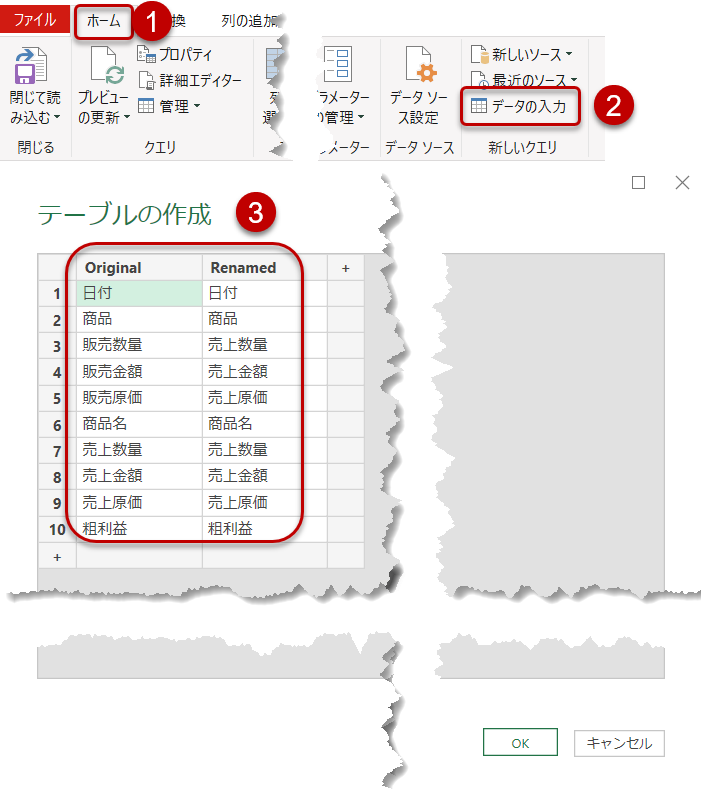
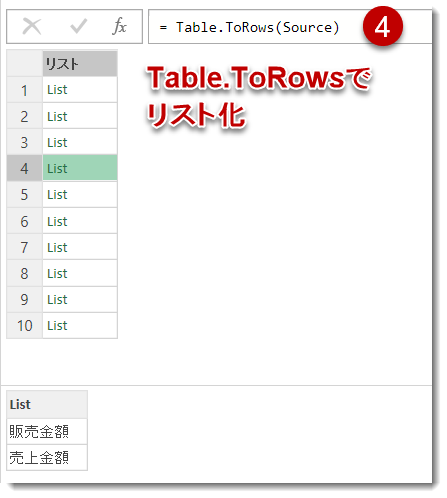
最後にTable.ToRowsという関数を使って、2つの列にあるデータをRenameするためのリストへ変換すれば完了。この場合、List.Bufferは必要ではなく、あとは上で紹介したやり方で列名を変換してTable.Combineで結合するだけです。このやり方で作ったヘルパークエリの名前はrenamed_inputです。
Pro:
パフォーマンスはrenamed_buffered以上に良い(基データのデータ量に左右されないため)
Con:
BeforeとAfterを追加できるようにするためには、まずはrenamed_slowを作り、その結果を見てマニュアルで入力する必要がある。また、renamed_slowに直接繋がっていないため、列が追加された場合に気づかない可能性も。そのため、頻繁に列名が変わる(追加される)場合、ソースを見て再入力をする手間が増えてしまう
ワンポイントアドバイス
余談ですが、マニュアルで入力した場合、Binary.FromTextやその他見慣れないM言語が出現し、もはや数式バーでの修正ができなくなってしまいます(下図)。
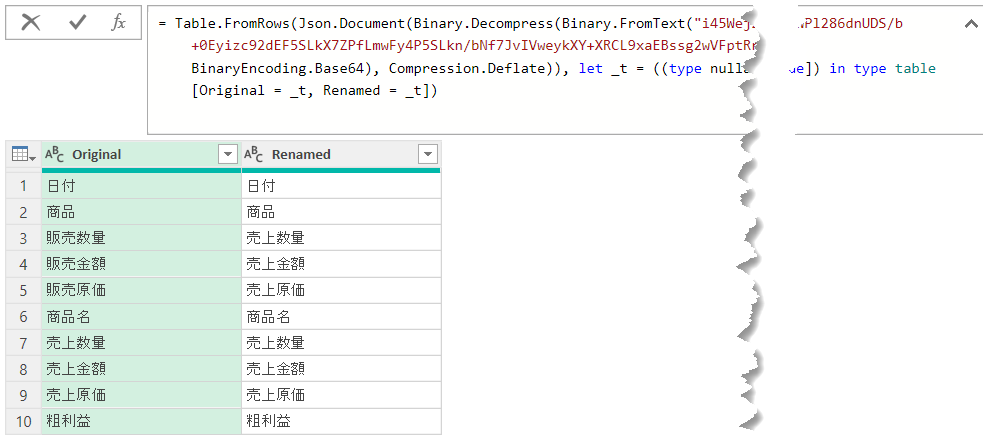
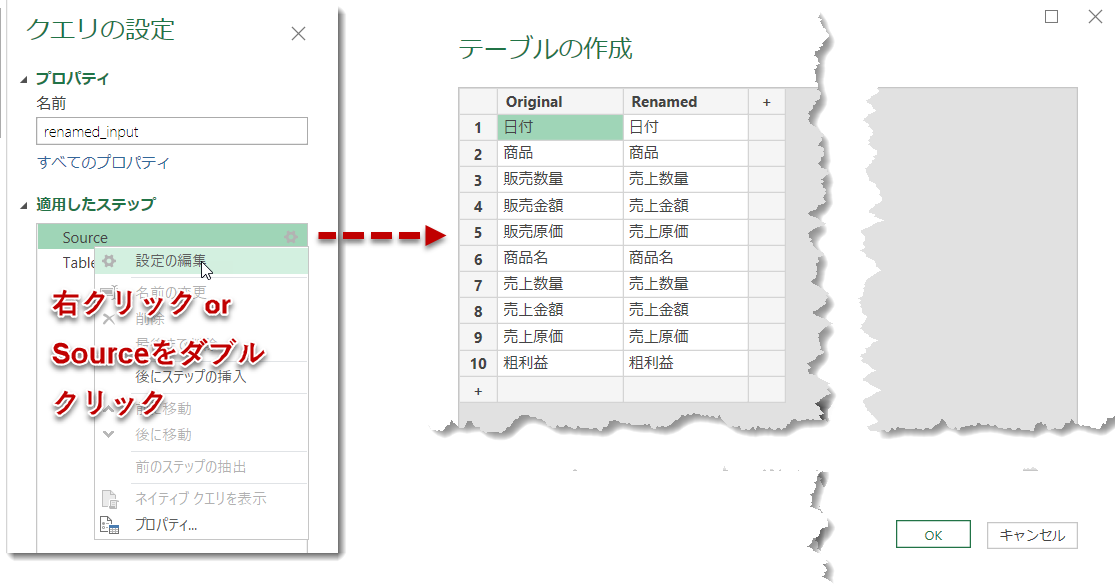
このタイプのクエリを修正するためには、下図のように、Sourceステップをダブルクリックするか、Sourceステップに合わせて「右クリック」 > 「設定の編集」をクリックします。
このように、パフォーマンスを改善するためのやり方は難しくはないのですが、データ量と相談しながら臨機応変に使い分ける良いでしょう。ちなみに、List.BufferはListをバッファするものですが、テーブルをバッファする場合、Table.Bufferを使用します。どちらもメモリ上に結果を一時的に待避させる処理を行いますが、今回のようなケース(何度も読み込みが発生するListをバッファするケース)以外にも、Table操作において、重複削除前の行の順序が変わることを防ぐ等に使うことができます。
ただし、便利だからといって頻繁に使ったり、何も考えずに使ったりすると返ってパフォーマンスが悪くなることも多いので、試しながら使うべきかどうかを判断したほうが無難です。
追記: Table.Bufferについて、Power Queryやデータフローで開発を行う際に第二のパラメータを指定すると開発エクスペリエンスが向上することが記述されていますので、下記も併せてお読みください。
列の選択
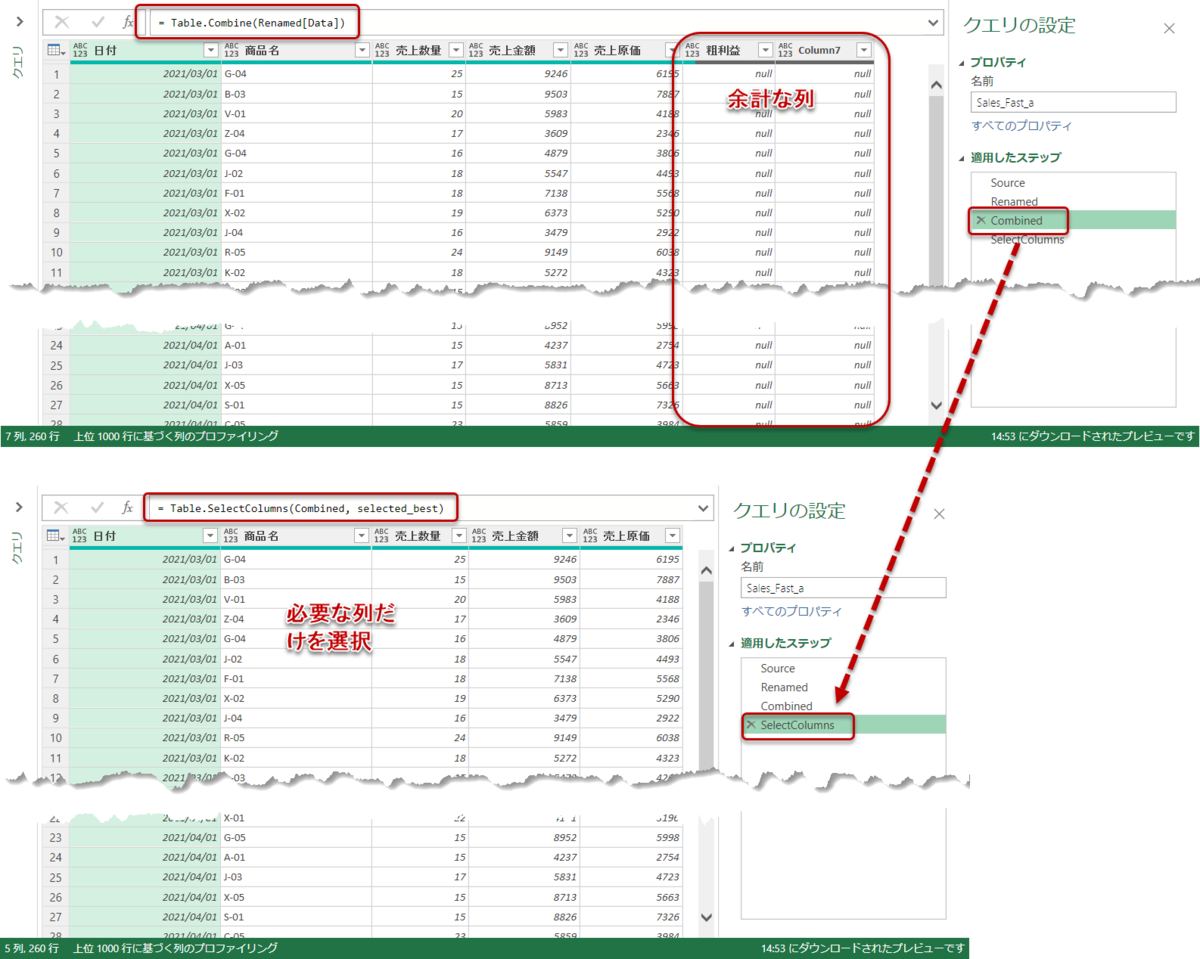
最後の処理になりますが、Table.Combineを実施した場合、[粗利益]と[Column7]が結合後のクエリに出現してしまいます。これは、一番最後のファイル(dummy_202203_new_header.xlsx)においてこの2つの列が出現したことが原因で、[Column7]は必要のない列だとすぐに分かりますが、[粗利益]は用途次第で残すかどうかの判断になります。
一般的に、[粗利益]という列は[売上金額] - [売上原価]の列で計算でき、Power BIやExcel Power Pivotでは必要のない列となりますので、今回は不要と判断し、この先話を進めていきます。
そうすると、最後の処理が「列の選択」ということになりますが、Table.SelectColumnsまたはTable.RemoveColumnsのどちらかを使ってデータモデルに投入する前の最終クエリを作っていくことになります。ここで両方の関数についてみると、
Table.SelectColumns(前ステップ, 必要な列名List)
Table.RemoveColumns(前ステップ, 必要ない列名List)
という定義になっています。どちらを使用したほうが、将来発生するかもしれないエラーを防ぎやすいでしょうか?
答えは前者のTable.SelectColumnsです。理由は2つ。
- 将来、追加されるファイルに[Column8]、[Column9]等の不要列が出現した場合、Table.RemoveColumnsでは「必要ない列名List」にこれらを指定しなければならず、その都度追加作業が発生してしまう
- データモデルに投入するデータは、モデルサイズを最小化させるため、可能な限り不要な列を除外したほうが良い。ということは、必要な列を自分で選べるようにコントロールできたほうが、メンテナンスの手間が減る
最後のステップではもう1つのヘルパークエリを作ります。必要な列だけを抽出すればよいので、前回の記事で作ったheader_afterを使います。ソースコードは以下の通り。
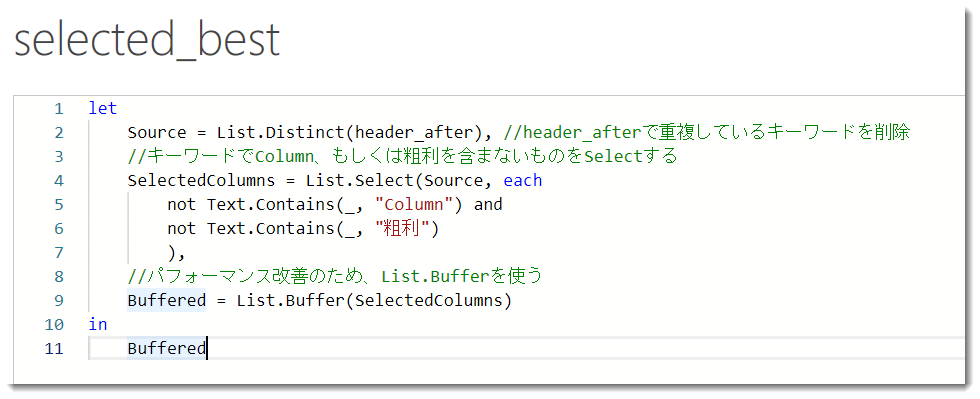

これで最後のステップでは上記5列だけが選択され、残りの列は除外されるようになります。この最後のヘルパークエリではList.Distinct、List.Select、Text.Contains、List.Bufferという4つの関数を使っていますが、List.SelectとText.Containsも非常によく使う関数となりますので、使う場面を覚えておくと非常に役に立ちます。
最終的には列を選択するTable.SelectColumn関数により、selected_bestというリスト(上記5つのキーワード)だけが選択された状態となります。
= Table.SelectColumns(Combined, selected_best)
なお、ここでデモを終わりますが、データモデルに結果をインポートする場合、必ず列のデータ型を変更しておくことが必要になります。これをやらなかった場合、DAX関数(SUMやSUMX等)が使えない状態になってしまいます。
最後に
実は最終回までの説明は非常に長いものでしたが、M言語が分かる人であれば、「詳細エディタ」や「適用したステップ」を1つずつ見ていけば殆ど解説が必要ない内容となっています。その領域に達するまでには自分で試行錯誤をしつつ、参考書も読みながら悪戦苦闘を繰り返す必要がありますので、私がここで書いた内容はその中で自分が考えたベストプラクティスのようなものとなります。
好みやPower Queryのスキルの差によって、それはベストプラクティスではないという意見も必ず出てきますが、それはそれで問題ない話だと思っています。例えば、スキルの高い人はカスタム関数を作って、一発で結果にたどり着くこともできます。また、例えば今回紹介した内容が難しいということで、クエリを複数作って、最終的に自分で理解できるように分解しながらやってみた、というのでも問題ありません。重要なのは、
自分の中でのベストなやり方を他の人が自分よりもスマートに実現できた場合、それを自分が理解できる範囲内で自分にとってのベストプラクティスとして洗い替えをしていく
という姿勢を持つことだと思います。
4回に渡って「書式が異なるデータの集計」について紹介してきましたが、個人的にはExcel等のファイルベースで作業を行う人が最も遭遇するパターンの1つではないかと思います。ぜひ、ご自身のユースケースに応用してみて下さい。